CV - Exam - Paper Presentation
Choose a paper from CVPR from conferences from 2024 on, reproduce code and make a presentation on it.
Choosen Paper: Memories of Forgotten Concepts
Paper List
(Alternatives just in case):
- LoTUS: Large-Scale Machine Unlearning with a Taste of Uncertainty
- Forensics-Bench: A Comprehensive Forgery Detection Benchmark Suite for Large Vision Language Models -> Forensics-Bench
- Track Any Anomalous Object: A Granular Video Anomaly Detection Pipeline
Eventually other alternatives:
- main
- HypCD
- DeepLA-Net
- APHQ-ViT
- lsnet
- piad_baseline
- BIT
- Bai_A_Regularization-Guided_Equivariant_Approach_for_Image_Restoration_CVPR_2025_paper.pdf you have to do the training, no pre-trained, but it’s just a CNN
- LATTE-MV
Todo
- Divide abstract in structure Structure of an Abstract
- Answer questions in Abstract
- Introduction
- Background
- Search for papers about Diffusion Models Inversion
- Original DDIM paper: 2010.02502
- Follow up of DDIM: EDICT 2211.12446
- ReNoise: Real Image Inversion Through Iterative Noising 2403.14602
- Null Text Inversion 2211.09794
- Analysis
- Limitations
- Conclusions
- Make presentation
- Read Appendices
- Appendix A
- Appx B
- Appx C
- Appx D
- Appx E
Paper Summary
- Paper: Memories of Forgotten Concepts
- My Fork: Memories_of_Forgotten_Concepts
- Google Drive where i run experiments 1kbt9DAHF4ECX1E-XeGrGi0iaGvuUu7zO?hl=it
Abstract
Problem:
- Diffusion models dominate the space of text-to-image generation, yet they may produce undesirable outputs, including explicit content or private data.
- In this paper we reveal that the erased concept information persists in the model and that erased concept images can be generated using the right latent.
Methods:
- Utilizing inversion methods, we show that there exist latent seeds capable of generating high quality images of erased concepts
- Moreover, we show that these latents have likelihoods that overlap with those of images outside the erased concept.
Results:
- We extend this to demonstrate that for every image from the erased concept set, we can generate many seeds that generate the erased concept.
Conclusion
- Given the vast space of latents capable of generating ablated concept images, our results suggest that fully erasing concept information may be intractable, highlighting possible vulnerabilities in current concept ablation techniques.
Introduction
- Diffusion models have emerged as a prominent tool for text-to-image tasks, extending their importance beyond the research community
- However, it has been demonstrated that these models can generate undesirable content, such as violent and explicit material. 1
- This could be done by ablate (i.e, forget or erase) specific concepts (e.g., objects, styles)
- Erased concepts are described by text, and the weights of the model are steered away from generating images that are associated with these texts. Then, the ablated model is expected to generate images that do not belong to the population of the erased concept, when introduced with the text describing the erased concept.
- Questions the authors poses: does this mean the concept is erased? Can the model still generate images of the erased concept in some other way?
- Definition of ablated model: forgetting an image means that the ablated model can no longer generate a specific image (say, a specific image of a church) with a reasonable likelihood.
- For example: a model cannot generate anymore images that are categorized as belonging to an ablated concept like a churk
- Hypothesis: An ablated model should not have a high likelihood seed vector that can be used to generate a high-quality ablated image.
- Assumptions: both ablated text prompt and the target ablated image are given
- For an effectively erased model, it should not be possible to identify a latent seed that is both likely and yields a high-quality ablated image. However, authors analysis shows that the opposite holds true
- Authors uses a method called diffusion inversion to find the latent seed vector that corresponds to the ablated image.
- Authors find that multiple distinct seed vectors can be used to generate an ablated image.
- We show that by using multiple random support images, it is possible to obtain seed vectors with high likelihood that can generate a given query image.
Contributions:
- Introduce a metric to analyze how much an ablated model remembers erased concepts and images.
- Show that diffusion inversion of ablated images recovers latent seed vectors with high likelihood and generates images with high PSNR score
- Show that a single image can be inverted to multiple distant seeds, suggesting that erasing is harder than it looks.
Background
Diffusion Models concept erasure
- Diffusion Models are used for image generation. See 2 and 3. Trained on large scale datasets containing images from a wide variety of categories
- Issues: some images in the dataset contain not-safe-for-work (NSFW) content, copyrighted images, or private content, which the models learn to generate.
- One way to solve this is to retrain the model without the “illegal” data. However, these issues can incurr multiple times on large-scale models, making the retraining infeasible.
- Also, problematic images may be generated also if they are not present in the training set.
- Machine Unlearning: given a pretrained model, the process of removing the effect of training data from it is reffered as machine unlearning. 45
- Many unlearning issues and concerns arise for these models too, e.g., privacy regulations and generation of NSFW content 6
- Schramowski et al. propose modifying a model’s inference behavior to limit generation of certain data. 3
- Other methods suggest to finetune the model to reach this goal, or focus on changing the textual embeddings. For instance see 7
- Zhang et al. show an attack method against these models, using adversarial prompts that lead to the generation of an erased concept. 8
- Why this study is different: Authors do NOT propose an attack on concept erasing methods, NOR do they find specific prompts that generate concept images. Instead, they invert a concept image to find a suitable latent, showing that the image still lies in the plausible region of the distribution, even after the erasure process.
- The closest work to the one of the authors is: Pham et al. examining different concept erasing methods by using textual inversion to find a suitable textual embedding for generating given erased concept images 9
Latent Diffusion Models
Diffusion models are generative models that learn to map a Gaussian noise
Given
And for generation
is a noise variance parameter
During the training, the model learn to predict the added noise
The loss (MSE) :
For faster computing in space with lower complexity than the image space Rombach et al showed that using a VAE encoder and decoder, denoted as Enc(
The loss term for training LDMs is thus:
Generation is done by sampling a latent seed
In our work, we specifically focus on LDMs, as we use the decoder in some of our analyses
Diffusion Models Inversion
Inversion is the procedure of finding the latent seed that can be used to generate a given image.
As the generation nature of diffusion models is iterative, simple optimizations are too computationally heavy to perform on SOTA models.
One technique is DDIM Sampling, that can be used deterministically “DDIM inversion” was proposed as simply way to invert. 10
DDIM: denoising diffusion implicit models
Another technique is called null text inversion (NTI) 11
Garibi et al. proposed a method that inverts an image by using iterative steps of refinement between the diffusion steps, termed Renoise. 12
DDIM
The baseline idea of diffusion inversion is DDPM (Denoising Diffusion Probabilistic Models), in two steps:
- Forward process: corrupt the image by gradually adding Gaussian noise i.e:
until pure gaussian nose - Reverse process (generation): learn a neural network that predicts the noise
The problem is that DDPM is slow and stochastic. DDIM is instead detinistic.
Key idea: the training objective of DDPM does NOT require the reverse process to be Markovian.
Math:
At step
that gives an estimate of the original clean sample.
The reverse step in DDIM is written as:
without the random noise term, so the process becomes fully deterministic.
This DDIM process is non-markovian, has the same marginal distributions as DDPM, uses the same trained network but follows a deterministic path to reverse and get the original image. It is much faster because it follows a smooth trajectory instead of diffusing randomly.
EDICT
DDIM inversion for real images is unstable as it relies on local linearization assumptions, which results in the propagation of errors, leading to incorrect image reconstruction and loss of content.
in EDIT authors propose a Exact Diffusion Inversion via Coupled Transformers (EDICT). Key idea: maintining two coupled noise vectors in the diffusion process.
As noted in DDIM, the denoising process is approximately invertible:
Affine Coupling Layers are invertible neural network, the layer input is split into two equal-dimension halves. The layer output is the concatenation of the two outputs from the two splits. The idea is tha this can be used to track two quantities which can then be used to invert each other. These two quantites are partitions of a latent representation with a network specificalyl designed to operate in a fitting alternating manner.
This lead to rewriting the equation by adding a new variable
Now consider the initialization of the reverse denoising diffusion process, where
Then the sequences can be recovered eactly according to:
To avoid that the two sequences
Renoise
Real Image Inversion Through Iterative Noising
As other methods, it is based on the linearity assumption that the direction from 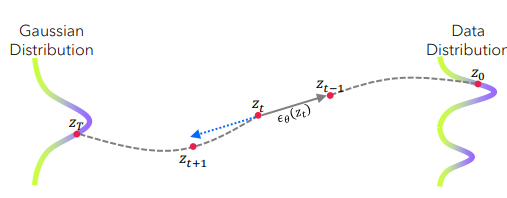
Samplers: they use a UNet model (denoted by
An image
however directly computing this equation is infeasible, since it relies on
However this assumption not only restricts the applicability of the inversion method to older diffusion models, but also struggles to produce accurate reconstructions in certan cases. This method is also sensitive to the prompt
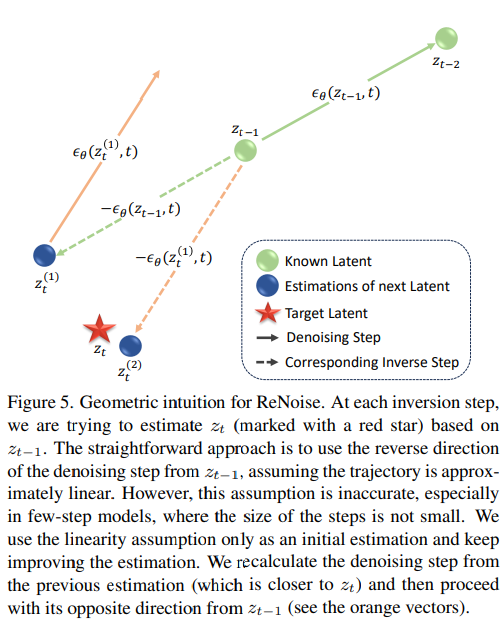
Observing that:
is a more precise estimate than compared to - using this as input to the UNet is more precise than
Iterating this process generates a series of estimates for
Then by averaging several
Summary:
- Start with
- In the
-th renoising iteration the input to the UNet is the result of the preivous iteration, - After that,
is calculated using the inverted sampler, maintaining as the starting point of the step Repeat for renoising iterations, to obtain a set of ostimations. The next point is the weighted average where is the weight associated to .
Null Text Inversion
Models like stable diffusion are composed of two pieces:
- A text-conditioned UNet
- A classifier-free guidance (CFG)
during sampling, the model predicts noise twice:
Then combines them:
is a guidance scale, and is null text (empty prompt).
That empty prompt embedding is crucial for Null Text Inversion.
The key idea of Null Text Inversion: instead of optimizing the image or the conditional prompt embedding, the null-text embedding is optimized at every timestamp
- perform DDIM inversion
- Freeze weights except for null embedding: for each timestamp
, keep the model weights fixed and optimize the null-text embedding.
This minimize the reconstruction error at each timestamp and make the predicted
why optimize the null embedding:
- rewrite previous equation as
In this i have a latent trajectory that reconstructs the original image very accurately
Analysis
Basic Setup
To evaluate if a model has erased the concept
- White box access to the Latent Diffusion Model (LDM) that eares
, denoted as - An erased set
(image, caption) pairs with images containing the concept - A reference set
(image, caption) pairs with images that do not contain the concept
Goal: analyize and quantify the erasing effect of
Requirements:
- images have a low reconstruction error, i.e., high PSNR;
- and analyze the likelihood of the latent vector.
How do we measure memory?
Given a latent seed
Results are reported in Negative Log Likelihood (NLL) units, denoted as:
The Central Limit Theorem is used to approximate
For a set of images, we invert them to latent seeds
This NLL is performed on the erased set
These can be shown in the following figure:
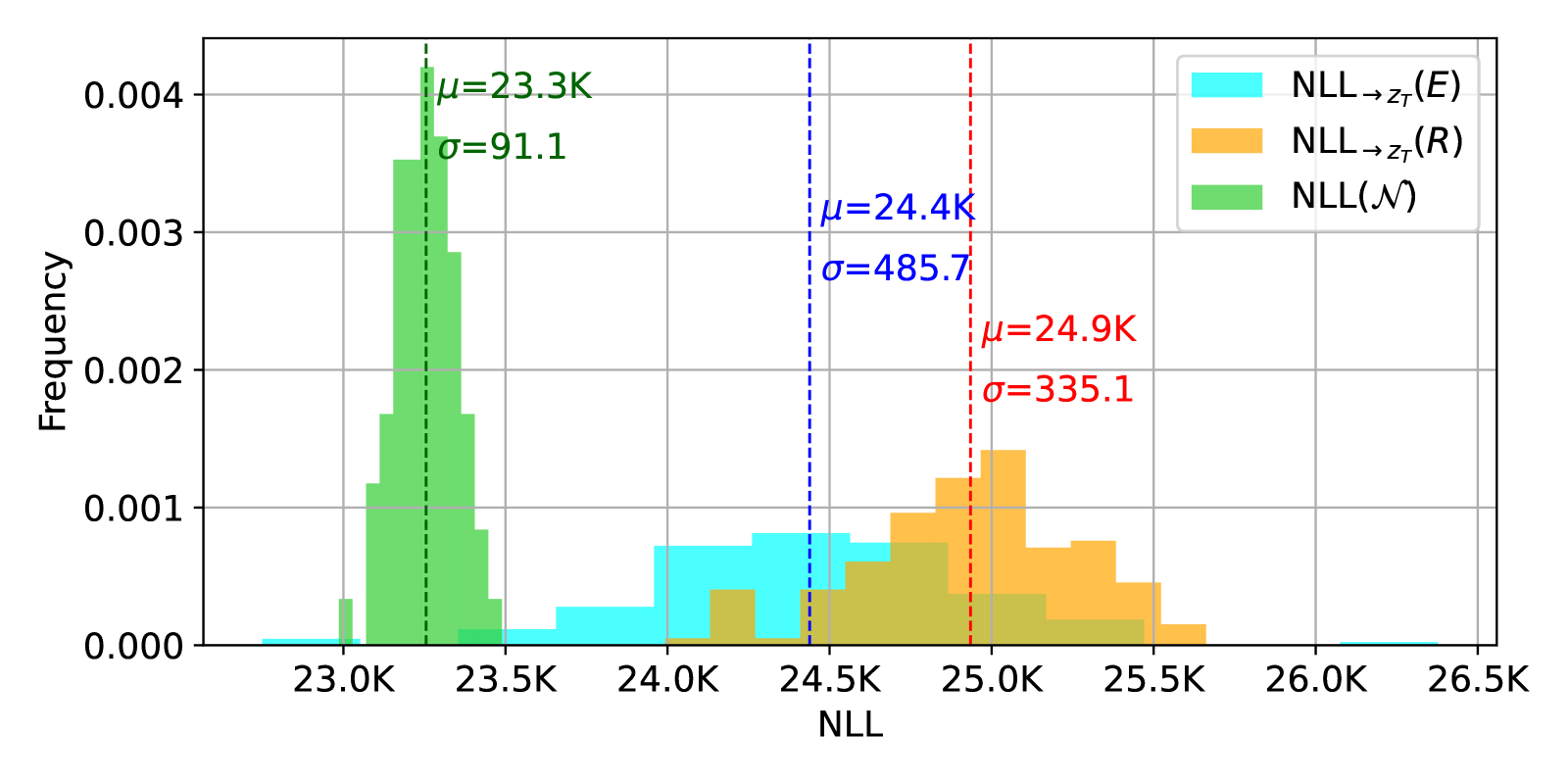 For a model that erased the concept Nudity the likelihood distribution fits different Gaussians that are different from the sampling distribution of the LDM which is standard normal distribution
For a model that erased the concept Nudity the likelihood distribution fits different Gaussians that are different from the sampling distribution of the LDM which is standard normal distribution
We found it difficult to have a clear understanding based on the NLL values alone, Therefore, we opt for a unit-less number that conveys information in relative terms.
From a likelihood perspective, a model that erases a concept should ideally map it in a low likelihood region in
Therefore, we measure the distance of images in the erased set
Specifically, we use the ratio of the Earth Mover’s Distance (EMD) to obtain this measure, denoted Relative Distance13:
The distance should be
A value smaller than 1 suggests that the erased set is closer to the Normal distribution than the reference set, which indicates that something is wrong with the model.
A high distance means the reference set is far more likely than the erased set which is what we hope for.
Figure 3:
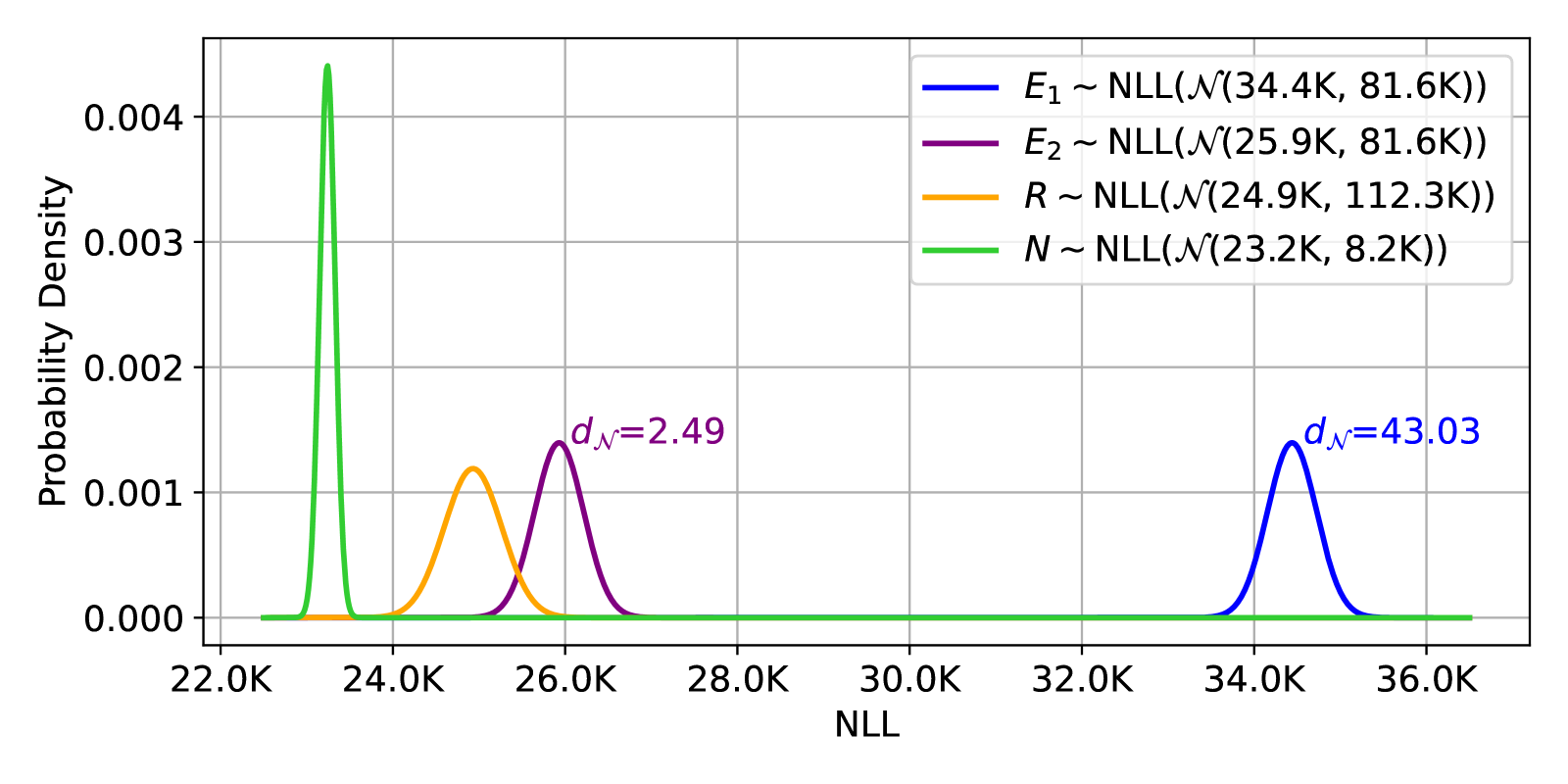 The erased model
The erased model
Experimental Setup
Authors consider six different concepts: Nudity, Van Gogh, Church, Garbage Truck, Parachute and Tench.
Authors consider recent different methods that ablate the base Stable-Diffusion 1.4 that are:
- ESD
- FMN
- SPM
- AdvUnlearn
on all concepts,
- Salun
- Scissorhands
- EraseDiff
on all concepts except from Van Gogh.
- UCE on nudity and van gogh
AC only on Van Gogh
(TODO: fai tabella)
The latent space dimension for this model is 4×64×64.
Datasets are collected according to Zhang et al 8
How??
We consider two types of analyses:
- The first is inquiring about the memory of an ablated concept, by aiming to retrieve a single latent to every given query image.
- The second, exploring many memories of an ablated image, aiming to find multiple seeds that correspond to the same query image
Memory of an ablated concept
- Authors shows that on a dataset level, concept erasure models can generate the erased concepts with high PSNR and high likelihood.
- Namely, for every image in the dataset, we can find a likely latent that recovers that image
- Given the erased set with images that depict concept
(e.g., various images of churches), namely we use it to analyze a model that was finetuned to erase this concept - For every query image
, we perform diffusion inversion to retrieve latent seed . This latent is later used for diffusion inference, leading to a reconstructed image .
Figure 4 shows this process:

Results are shown in figure 5 (left and right panel):
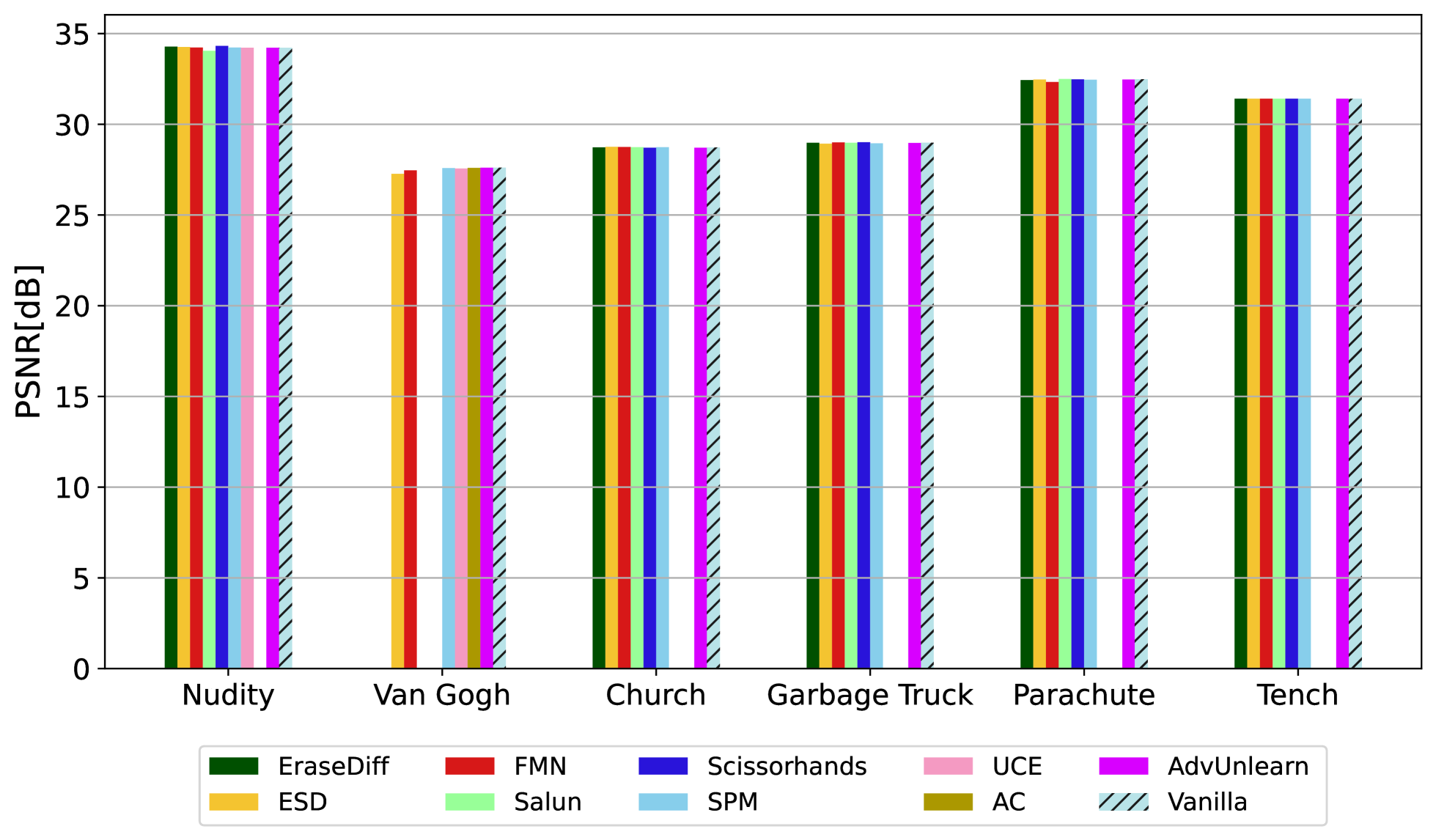

- All current ablated model can generate images containing the erased concept.
- high PSNR values for reconstruction among all the different methods.
- Concepts with finer texture details such as Van Gogh and Church, tend to have lower PSNR
- Smoother concepts such as Nudity and Parachute, achieve higher reconstruction.
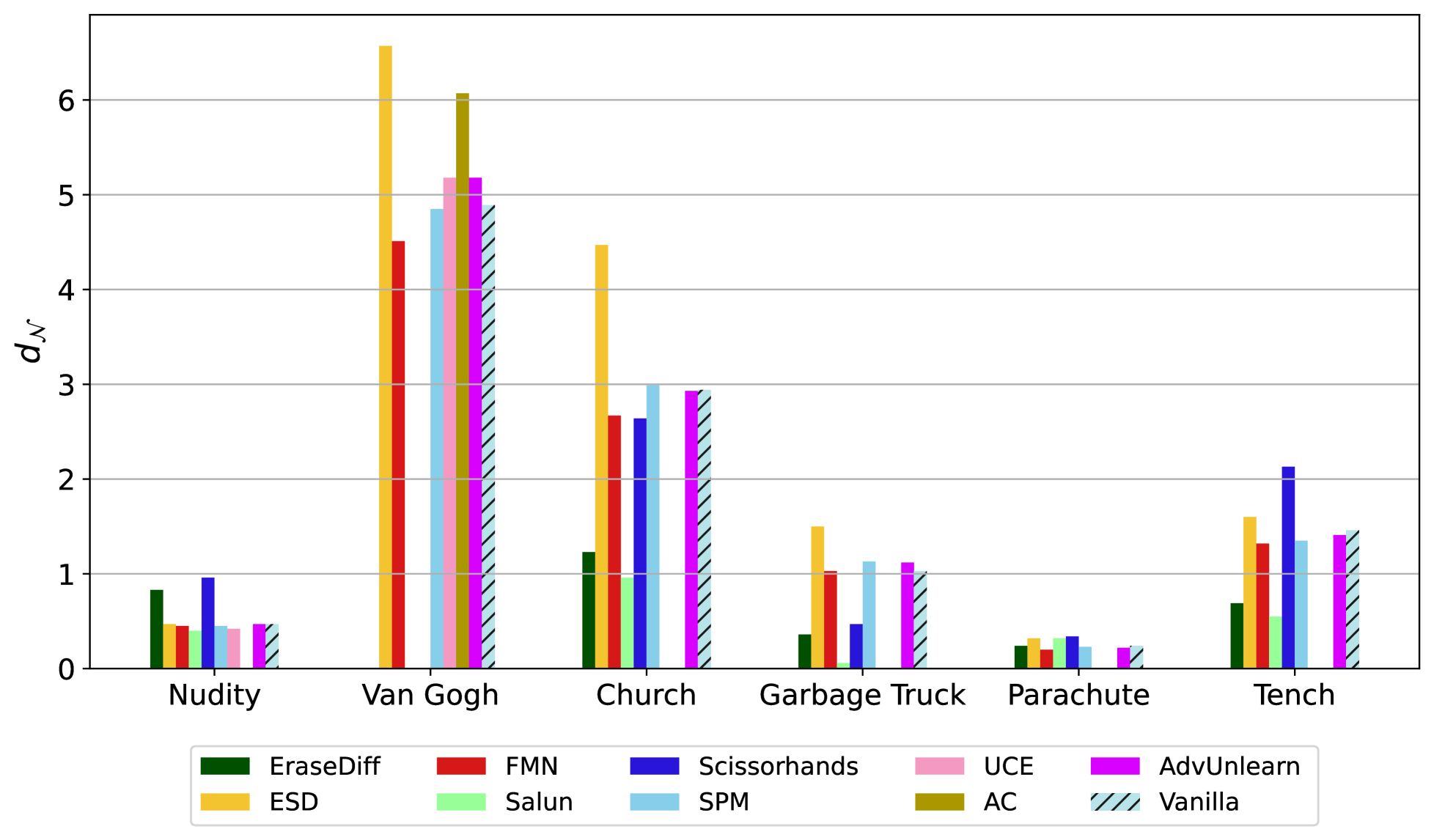
The right panel shows the relative distance of different concepts and concept erasing methods.
- The highest distance means the best distance in terms of erasing, is achieved by ESD on concept
=Parachute, with a distance of . - This score indicates that there exists a non-negligible overlap between the distribution of the erased concept and the reference dataset.
Recall from figure 3, what does it mean a distance of 2.49:
- The Supplementary contains additional examples and results
Also:
See that many model achieve a similar relative distance to vanilla model. This suggests that these models may make harder to generate images of the erased concept using text prompts that describe it, but it is still plausible the generation of such spaces in the latent space.
The many memories of an ablated image
- For a given image
, is there more than one distinct latent seed with a sufficiently large cosine distance between them, that can be used to generate a the query image ? - These latent seed should satisfy two main requirements: should be likely (in terms of probability distribution) and should be well-seprated from each other.
Sequential Inversion Block
We seek distinct “memories” of the same query image. To do that, we start with random support images.
For each support image, we invert the VAE decoder
Then the reconstructed query images are fed to the diffusion inversion to produce the desired
Formally, the Sequential Inversion Block maps support images
- Initial Decoder Inversion find a latent
in the decoder latent’s space that will serve a starting point for the next step in the block - Decoder Inversion Towards the Query Image: starting from a initial latent seed, find the latent that reconstruct the image
i.e - Latent Diffusion Inversion apply
as starting point for a diffusion model inversion process, resulting in latent seed which is the output of the Sequential Inversion Block
More formally:
then starting from
Then, using this latent seed as starting point in a diffusion model inversion process will result in latent seed
The retrieved latent
In addition, authors anlyize likelihood of
Experimental Setup:
- Randomly select an image from COCO dataset
- For each concept select 5 random query images and validate that for every query image,
- For each concept, there are at least ten distinct latents.
- Each of these latents is initialized using a different support image.
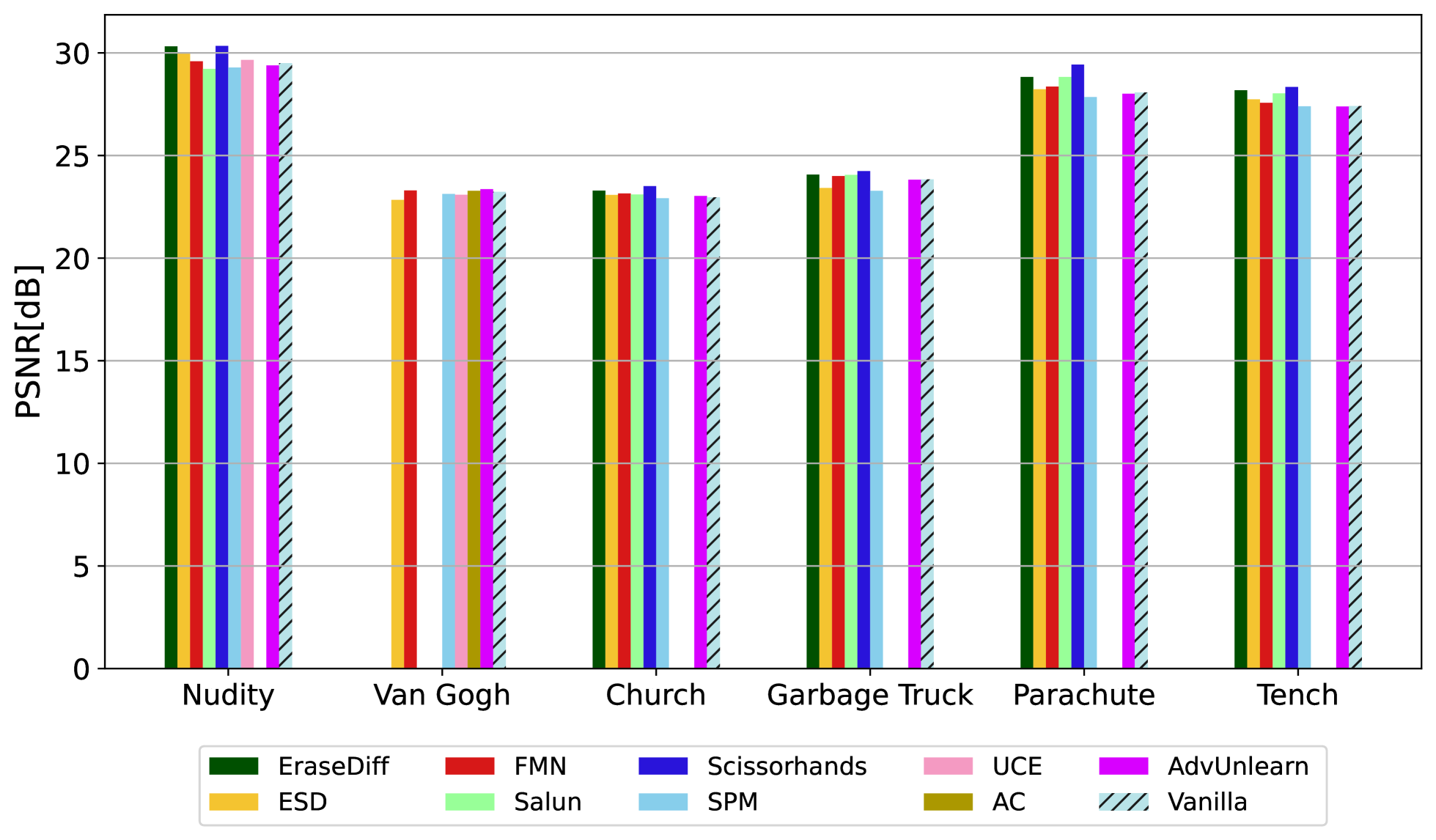
For all methods and all concepts, authors were able to recover likely latent seed vector i.e low relative similarity that lead to an high-quality reconstruction (high PSNR).
However, compared to the concept level forgetting we see a lower PSNR value and lower
Figure 8 shows these results:
Geometric Interpretation of the retrieved memories
- To understand how the retrieved seeds are
are distributed geometrically in space with respect to the original target seed , we compute the average euclidean distance between all and .
See figure 6:

On the left part All these distances are tightly spread around the mean distance.
- the mean is 152.14 and the standard deviation is 2.72.
- This leads to a coefficient of variation of 2%
- Computing the coefficients for all images, lead to a mean and standard deviation of the coefficients of 2% and 1% respectively
Also, figure 9 shows the average pairwise cosine distance:

And considering these, authors conclude that their procedure produces memories that lie (with a high probability) on a sphere centered around a
Following this geometric insight, one could choose any number of
This raises following questions for future forgetting work: Will re-mapping all these possible seeds into images that do not resemble
Limitations
- The analysis of this paper assumes a white-box setting i.e accessing the model’s weights and the ability to inverse it
Figure 10 shows that:



Reassemble:

When an image associated with the ablated concept “Church” is scrambled, inverted and then reassembled, the model retains certain associations with the original concept.
Although the concept classifier score for “church” drops significantly (from 0.99 to approximately
This generalization ability appears to conflict with concept erasure, as models may inadvertently retain latent representations of ablated concepts.
Applying our analysis gives coherent results, as the likelihood of the seed that results from the shuffled image is lower, and the PSNR is worse. Specifically, the NLL of the retrieved
Conclusions
As diffusion models become more accessible and common to the public, the importance of the safety and privacy of these models increases. Recent papers address this concern, developing essential methods for editing diffusion models’ outputs to ensure a safer and more controlled generation. Previous methods sought to limit the generative capabilities of specific concepts by disrupting the ability to generate these concepts through descriptive text. In this work, we hypothesize that an ablated model should not have a high likelihood seed vector that can be used to generate a high-quality ablated image. We show, across many methods and different categories, that previous attempts did not truly erase concepts. We do so, by introducing an analysis on the reconstruction quality of images from the erased concepts, and on the likelihood of its corresponding latent seeds. We hope our proposed analysis encourages further research on reliable concept erasure evaluation.
- Previous attemps did not truly erase concepts.
Questions
What is a diffusion model? What is an ablated difussion model? What is a latent seed? What does it mean the problem may be intractable? What could possible be the conseguences of the problem being intractable?
- What is PSNR?
- What is an erased diffusion model?
- Do you understand diffusion mathematically?
- Do you understand inversion?
- Do you understand why likelihood matters?
- Connect this to bayesian theory of decision
- Do you understand why this is a safety problem?
- Can you critically interpret results?
Footnotes
-
Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models 2211.05105 ↩ ↩2
-
Erasing Concepts from Diffusion Models 2303.07345 ↩
-
When machine unlearning jeopardizes privacy 2005.02205 ↩
-
Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models 2211.05105 ↩
-
Robust Concept Erasure Using Task Vectors 2404.03631 ↩
-
To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy To Generate Unsafe Images … For Now 2310.11868 ↩ ↩2
-
Circumventing Concept Erasure Methods For Text-to-Image Generative Models 2308.01508 ↩
-
EDICT: Exact Diffusion Inversion via Coupled Transformations 2211.12446 ↩
-
Null-text Inversion for Editing Real Images using Guided Diffusion Models 2211.09794 ↩
-
Renoise: Real image inversion through iterative noising. 2403.14602 ↩
-
The Earth Mover’s Distance as a Metric for Image Retrieval rubner-jcviu-00.pdf ↩