NLP - Lecture 1 - Introduction
Introduction
NLP allows to cope with human language in a variety of ways, and it’s triggering a revolution in the way we interact with systems and technology.
NLP is at the intersection of computer science, artificial intelligence and linguistics.
Goal: Allowing machines to read, understand, and derive meaning from human languages in order to perform tasks that are useful. Example, question answering: Amazon Alexa, Apple Siri, Google Assistant, Facebook M, Microsoft Cortana…
Fully understanding and representing the meaning of language (or evendefining it) is a difficult goal.
In literature terms like ‘natural language processing’, ‘computational linguistics’, and ‘human language technologies’ may be thought of as essentially synonymous.
Why NLP?
Every day large and constantly growing amounts of information in form of text are produced. The amount exceeds human processing powers, therefore we want to extract relevant information in some automatic way.
NLP tasks

What does an NLP system need to know?
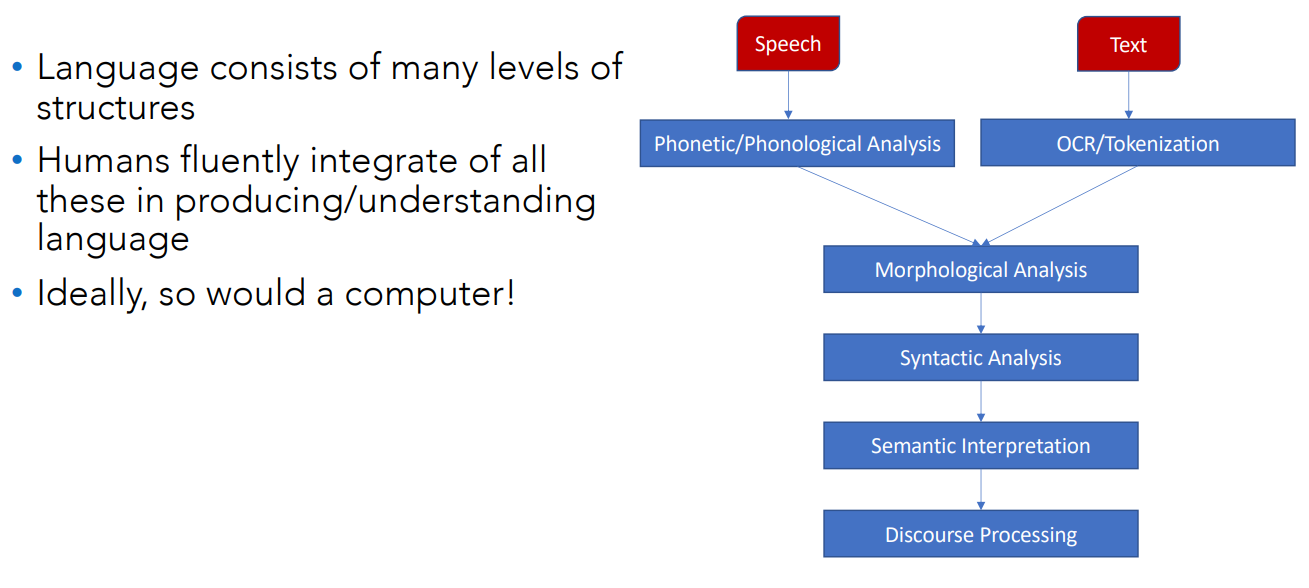 See also Speech Recognition.
See also Speech Recognition.
Words
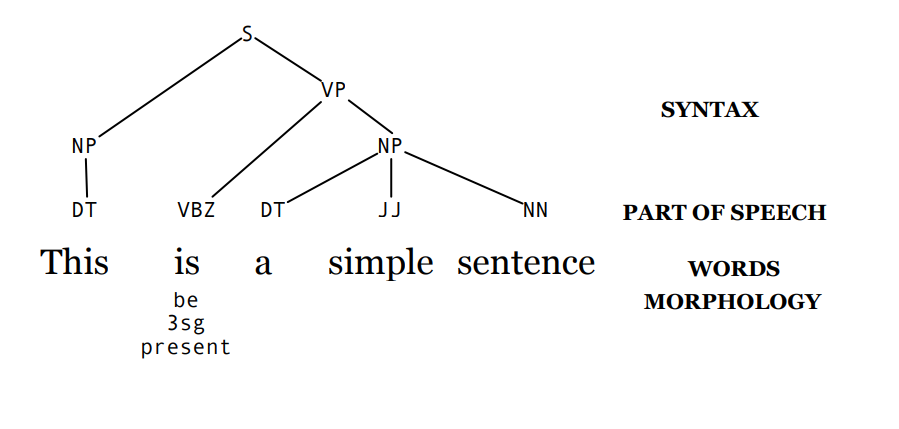
this is a simple sentence
Morphological analysis: consists in breaking words into the simplest meaningful units (morphemes).

Syntax / part of speech analysis (parsing): analyizing sentence structure (grammar) to undestanrd how words relate.

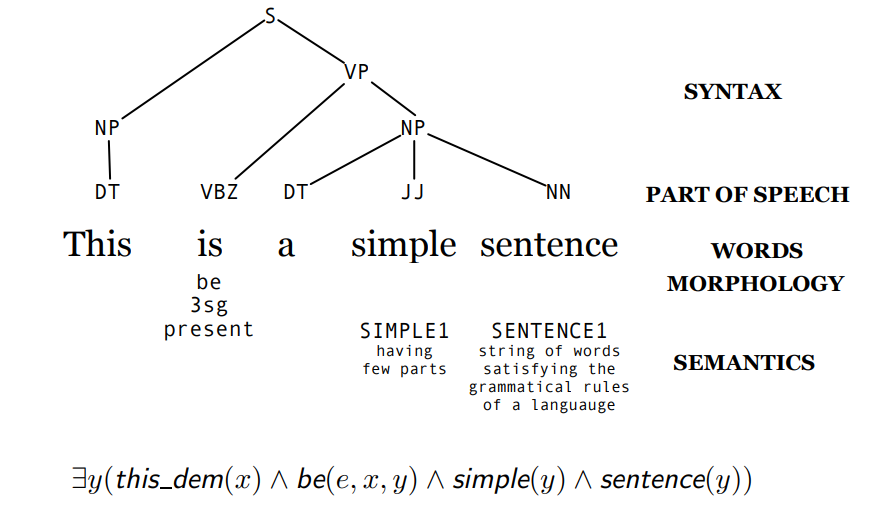
Semantics analysis/interpretation: assigning meaning to words and sentences based on their context and structure.
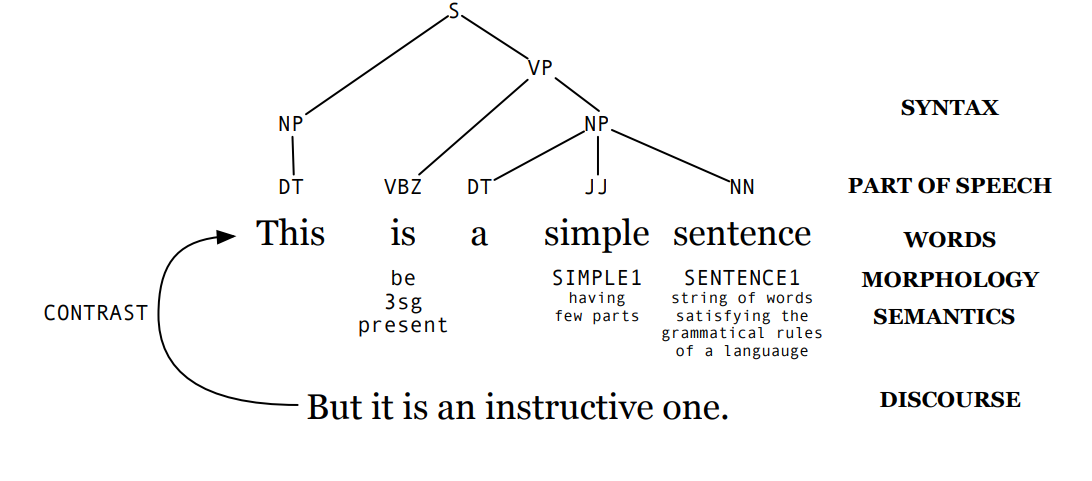
Discourse processing: for example interacting with other humans, understanding meaning across multiple sentences (context, references, coherence).
Development of NLP
Rules approach: ideally we want to define set of rules to emulate language. But, natural language is messy, ambiguos, flexible. We can say one things in many different way. So capture a final set of rules of all possible cases was unfeasable.
Statistics: analyze large multilingual set of text (corpus). This requires extensive work to define context.
Machine Learning and NN: semantic information learned from data.
- Recall ML2 Lecture on transformers
Why NLP is challenging
NLP distinguishes itself from other AI application domains, as for instance computer vision or speech processing.
We have some problems to address:
- Ambiguity
- Sparsity
- Expressivity
- Context dependence and unknown representation
Ambiguity
Text data is fundamentally discrete. But new words can always be created. Examples:
- Stan: an extremely enthusiastic and devoted fan (stalker-fan)
- Nomophobia: anxiety caused by not having a working mobile phone
To make a comparison with image processing.
Comparison between NLP and image processing
To compare it with image processing, think about how color works: pixel values are continuous numbers, so we can directly apply mathematical operations to them. With language, it’s different — words are not physical measurements but symbolic representations, so they don’t have inherent numerical meaning. Our brains interpret them, but to make them usable for computation we need to map them to something numerical, like through a lookup table, dictionary, or embedding.
Language is continuosly evolving, if you look a newspaper from 10 years ago, the words used are very different from today.
Natural language is ambiguos:
- For example the phonetic transpiction of “rait” might mean write, right, rite
Interpretation may depend on the context, for example the word bank refers both to the financial institution but also the bank of a river.
Words can belong to several categories: noun, verb, or model.
- For example the word “chair” could be a noun (the chair to sit in) but also a verb it means for example thriving a conference, chair a conference.
Also, consider syntactic structure: the sentence “I saw a man with a telescope” is ambiguous — does it mean I used a telescope to see the man or I saw a man who was holding a telescope?
Another aspect is discourse. “The meeting is canceled. Nicholas isn’t coming to the office.”. What is the casual relationship? The meeting is cancelled because Nicholas isn’t coming, or Nicholas isn’t coming because the meeting is cancelled?
Resolving ambiguity is hard


Nowdays there are even more difficulties because we have nonstandard language, emojis, hashtags, names:
Sparsity
Another problem is that text is sparse data due to Zipf’s Law.
Zipf’s Law is a statistical principle that describes how words are distributed in natural language.
To illustrate, let’s look at the frequencies of different words in a large text corpus.
Assume a “word” is a string of letters separated by spaces (a great oversimplification, we’ll return to this issue). Token is the term that we will use for linguistic data.
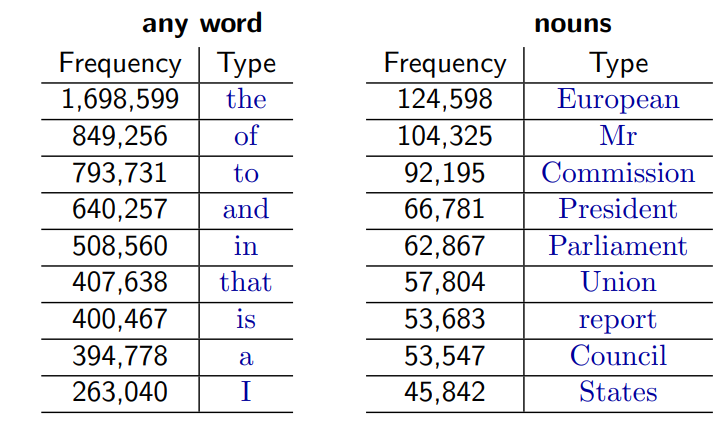 But also, out of 93638 distinct word types, 36231 occur only once. For example Cornflakes, mathematicians, fuzziness, jumbling. What we’re basically saying is that a machine learning model might run into words it’s never seen before, or that appear extremely rarely — and that can lead to problems.
But also, out of 93638 distinct word types, 36231 occur only once. For example Cornflakes, mathematicians, fuzziness, jumbling. What we’re basically saying is that a machine learning model might run into words it’s never seen before, or that appear extremely rarely — and that can lead to problems.
If we plot the word frequencies:
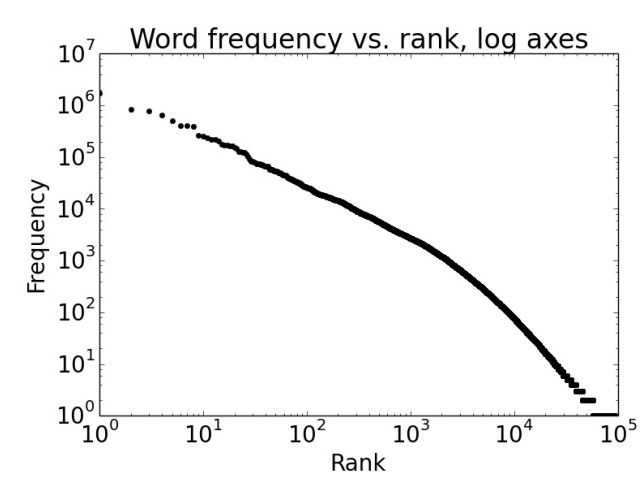 The Zipf’s Law summarize the behavior we’re observing here
The Zipf’s Law summarize the behavior we’re observing here
frequency of a word rank of a word (if sorted by frequency) constant
Implications of Zipf’s Law
Few words are very frequent, and there is a long tail of rare words Regardless of how large our corpus is, there will be a lot of infrequent (and zero-frequency) words.
In a classification problem, for instance, this means we need to find clever ways to estimate probabilities for things we have rarely or never seen during training.
Expressivity
Not only can one form have different meanings (ambiguity), but the same meaning can be expressed with different forms:

Context dependence and unknown representation
 The correct interpretation is context-dependent and often requires world knowledge.
Very difficult to capture, since we don’t even know how to represent the knowledge a human has/needs.
The correct interpretation is context-dependent and often requires world knowledge.
Very difficult to capture, since we don’t even know how to represent the knowledge a human has/needs.
- What is the ”meaning” of a word or sentence?
- How to model context?
- Other general knowledge?
That is, in the limit NLP is hard because AI is hard. In particular, we’ve made remarkably little progress on the knowledge representation problem.
Learning & Knowledge
In linguistics there are two main approaches that influenced the learning:
Rationalism
A significant part of the knowledge in the human mind is not derived by the senses but is fixed in advance, presumably by genetic inheritance.
Generative linguists have argued for the existence of a language faculty in all human beings, which encodes a set of abstractions specially designed to facilitate the understanding and production of language.
Empiricism
The view that there is NO such thing as innate knowledge, and that knowledge is instead derived from experience, either sensed via the five senses or reasoned via the brain or mind.
Nowadays, many statistical NLP techniques work very well on texts, without the need to use special bias representing linguistic knowledge or mental representation of language.
History of Rationalism and Empiricism:

NLP in Finance
In finance, data can help make timely decisions come in text.
Earnings reports are one example. A company will release its report in the morning, stating, “Our earnings per share were $1.12.”
By the time that unstructured data makes its way into a database of a data provider, where you can get it in a structured way, hours have passed, and you’ve lost your edge.
NLP can deliver these transcriptions in minutes, giving analysts a competitive advantage.
NLP in Social Networks
- Automated fake news detection
- Fake news refers to information content that is false, misleading, or whose source cannot be verified.
- An example, companies like Facebook, X, TikTok, Google, Pinterest, Tencent, YouTube, and others worked with the World Health Organization to mitigate COVID-19-driven infodemic.
NLP in Healthcare
Huge volumes of unstructured patient data is inputted into electronic health record systems
- 80% of healthcare documentation is unstructured text
Healthcare NLP uses specialized engines capable of discovering previously missed or improperly coded patient conditions.
Learning Stuff
Reference Text: Speech and Language Processing (3rd ed, draft): slp3
The exam will consists in an oral part and a project that will assign to you after middle course and it is based to use some advanced architecture to perform some kind of task.
Rao & McMahan, Natural Language Processing with Pytorch, 2019, O’ Reilly.
The project should be implemented in python (any kind of framework you want).
NLP tasks and their relative difficulty
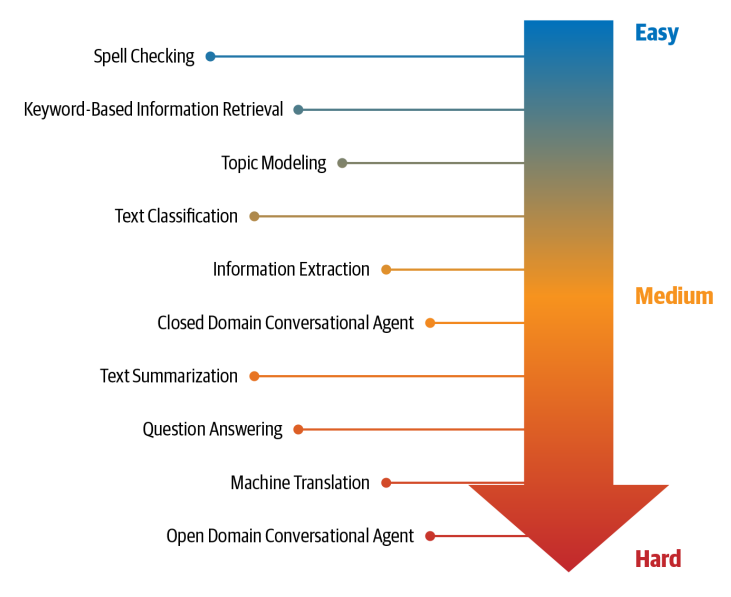 We will cover some of these tasks.
We will cover some of these tasks.