Conditional Random Fields (CRF)
Conditional Random Fields are an alternative to Hidden Markov Models.
CRF is a discriminative sequence model based on log-linear models.
Linear CRF
In this chapter it is descrived how to apply CRF for tasks like POS tagging and NER tagging
Assume a sequence of words
In Hidden Markov Models you search for the tag sequence that maximizes
In contrast in CRF we compute directly the posterior
is the set of all possible sequences
However, the CRF does not compute a probability for each tag at each time step. Instead, at each time step the CRF computes log-linear functions over a set of relevant features, and these local features are aggregated and normalized to produce a global probability for the whole sequence.
Assume you have
is a function that maps an entire input sequence to an entire output sequence .
It is common to pull out the denominator, and write it as
- where
is the denominator of the previous function
Each
Linear CRF Constraint: each local feature depend only on the previous tag (i.e. output token)
This restriction makes it possible to use versions of the linear chain CRF efficient Viterbi and Forward-Backwards algorithms from the HMM (see Part-of-Speech Tagging (POS) and Named Entity Recognition (NER)).
A general CRF doesn’t have this restriction and can include “long-range” dependencies, like
Features in a CRF POS Tagger
Each local feature
So some legal features representing common situations might be the following:
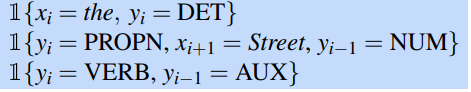
For simplicity assume all CRF features take on the vale 1 or 0.
Consider this template that use information only from
the pair the pair nearby context words like.
During training and testing, these templates automatically populate the set of features from every instance
Example: considering Janet/NNP will/MD back/VB the/DT bill/NN
is the word back, the following features would be generated and have value 1: and back VB and MD VB and will and = bill
Known and unknown words
- Known-word features are computed for every word seen in the training set
- Unknown-word features may be built for all words or only on training words whose frequency is below some threshold.
- Usually features that occur fewer than 5 times are discarded.
Remember that in a CRF we don’t learn weights for each of these local feature
It is those global features that will then be multiplied by weight
Thus for training and inference there is always a fixed set of
Inference and Training for CRFs
Starting from equation:
consider
- The partition function
can be ignored for a given observation sequence (doesn’t depen on ).
To find the best sequence, we use the Viterbi Algorithm. Recall that Viterbi Algorithm in practice works by filling a
The Viterbi Step becomes:
Training a CRF works very much like training logistic Regression: it maximizes the conditional log-likelihood of the training corpus with respect to the weights
Summary
- Linear CRF assumption similar to HMM, use only current and previous output
- Maximize log-likelihood like in a linear regression model.
- Use Viterbi algorithm to find the best tag sequence.