AI - Lecture - Solving Problems by Searching - Heuristic Search Strategies and Heuristic Functions
- Source: Book Artificial Intelligence A Modern Approach 4 edition global edition - Russel - Chapter 3
Informed (Heuristic) Search Strategies
Uninformed search strategies are slow and using an heuristic can help to find solutions more efficiently
Heuristic function: is denoted as
- Example: in route-finding problems, we can estimate the distance from the current state to a goal by computing the straight-line distance on the map between the two points.
Greedy best-first search
Expands first the node with the lowest
Applied to the route-finding problem in Romania, we compute first the straight-line distance heuristic called 
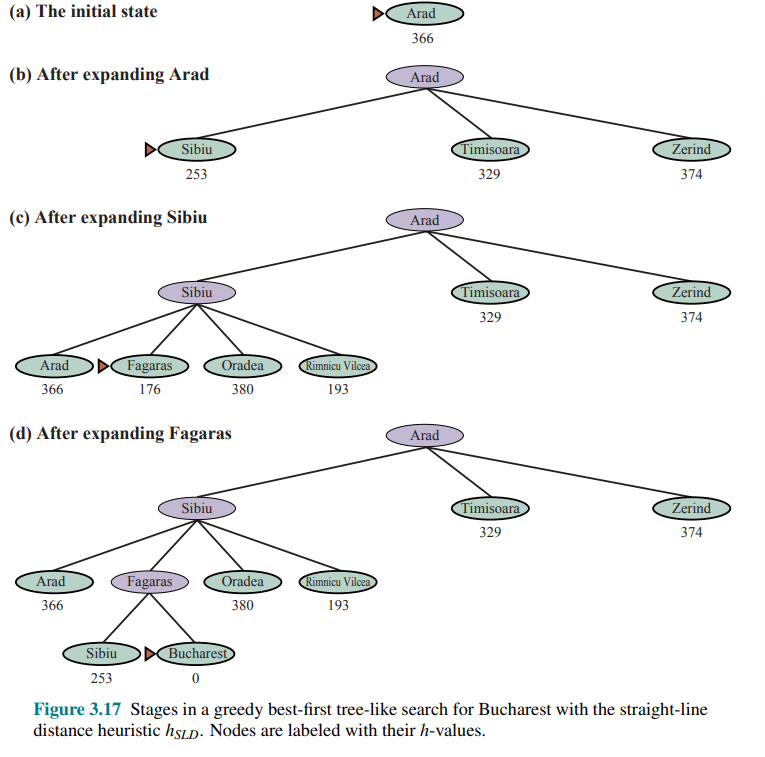
For this kind of problem, the greedy best-first search find the solution without even expanding a node that is not on the solution path.
Greedy best-first graph search is complete in finite state spaces, but not in infinite ones.
The worst-case time and space complexity is
A* Search
The most common informed search algorithm is A star search, that uses the evaluation function:
is the path cost from the initial state to node n is the estimated cost of the shortest path from n to a goal state, so we have:
Consider following figure:
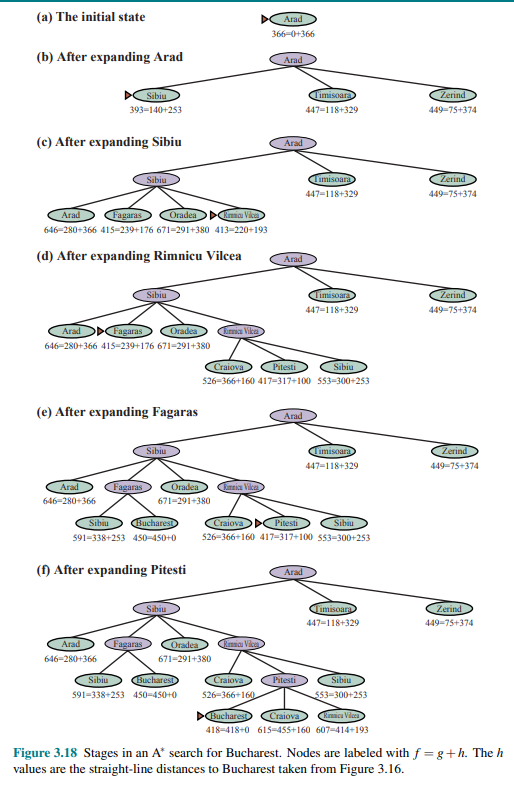
The values of
Notice that at step (e), Bucharest appears on the frontier with a cost of 450, however the algorithm does not select it because there is a possibility that going through Pitesti, whose cost is as low as 417, a better solution would be find. In fact, at step (f), After Pitesti Bucharest is selected as the lowest at
Admissible Heuristic:
search is complete assuming all action costs are and the state space either has a solution or is finite. - A key property is admissibility, an admissible heuristic is one that never overestimates the cost to reach a goal (an admissible heurstic is therefore optimistic).
- With an admissible heuristic,
is cost-optimal
Proof by contradiction that
- Suppose the optimal path has cost
, but the algorithm returns a path with cost - Then there must be some node n which is on the optimal path and is unexpanded (because if all the nodes on the n the optimal path had been expanded, then we would have returned that optimal solution)
Let
(otherwise n would have been expanded) by definition because we said that n is on the optimal path - If we consider admissibiliy then
then we can write: - Then
because by definition
However, the first and the last lines from a contradiction, so the supposition that the algorithm could return a suboptimal path must be wrong: it must be that
Consistency
Another slightly stronger property is called consistency. An heuristic
This is a form of the triangle inequality i.e a side of a triangle cannot be longer than the sum of the other two sides.
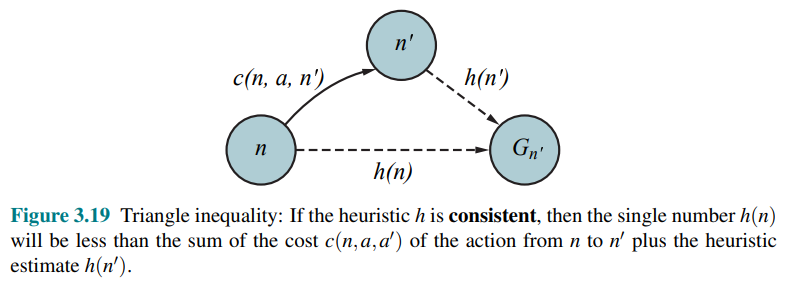
Every consistent heuristic is admissible but not viceversa, so
In addition, with a consistent heuristic, the first time we reach a state it will be on an optimal path, so we never have to re-add a state to the frontier, and never have to change an entry in reached. With an inconsistent heuristic, we may end up with multiple paths reaching the same state, and if each new path has a lower path cost than the previous one, then we will end up with multiple nodes for that state in the frontier, costing us both time and space.
These complications have led many implementers to avoid inconsistent heuristics, but Felner et al. (2011) argues that the worst effects rarely happen in practice, and one shouldn’t be afraid of inconsistent heuristics.
Search Contours
A useful way to visualize a search is to draw contours in the state space, just like the contours in a topographic map.
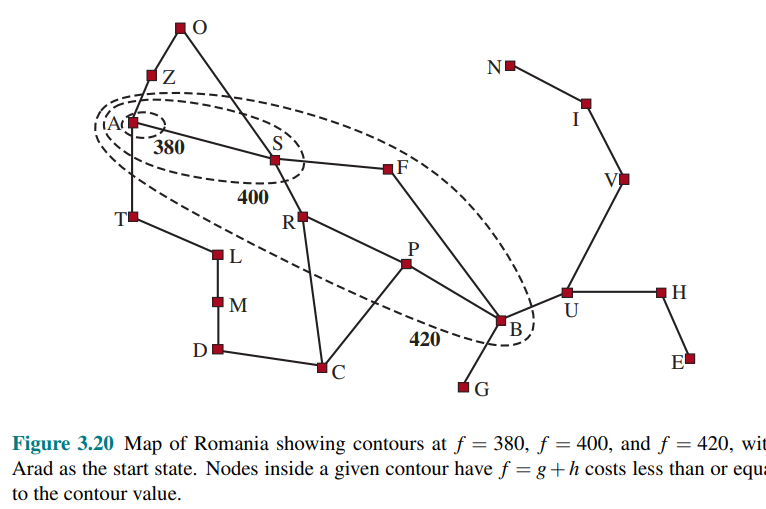
In the contour labeled 400 in the figure, all the nodes have
- In a
search, the algorithm expands the frontier node of lowest f-cost, adding nodes in the concentric bands of increasing -cost - With uniform-cost search, we also ahve contourse but of
-cost, not The contours with uniform-cost search will be “circular” around the tstart state, spreading out equally in all directions with no preference towrds the goal - A good heuristic will make the
search stretch toward a goal state and become more narrowly focues around a optimal path - The
costs are monotonic: the path always increases as you go along a path, because action costs are always positive. Therefore you get concentric contour lines that don’t cross each other. - However it is not obvious if
cost will monotonically increase.
If
- Surely expanded Nodes:
expands all nodes that can be reached from the initial state on a path where every node on the path has . if might expand some of the nodes right on the “goal contour if it expands no nodes with .
We say that
Pruning
Problems of A star search
For example: consider a version of the vacuum world with a super-powerful vacuum that can clean up any one square at a cost of 1 unit, without even having to visit the square. In that scenario, squares can be cleaned in any order.
With
Satisficing Search: Inadmissible heuristics and weighted A*
Satisficing Solution:
If we allows
For example, road engineers know the concpet of detour index, which multiplier applied to the straight-line distane to account for typical curvature of a road. A detour index of 1.3 means that if two cities are 10 miles apart in straight-line distance, a good estimate of the best path between them is 13 miles. For most localities, the detour index ranges between 1.2 and 1.6.
This can be applied to any problem, not just ones involving roads, with an approach called weighted A star search, where we weight the heuristic value more heaviliy, giving us the evaluation function:
Figure 3.21 shows a search problem on a grid world.
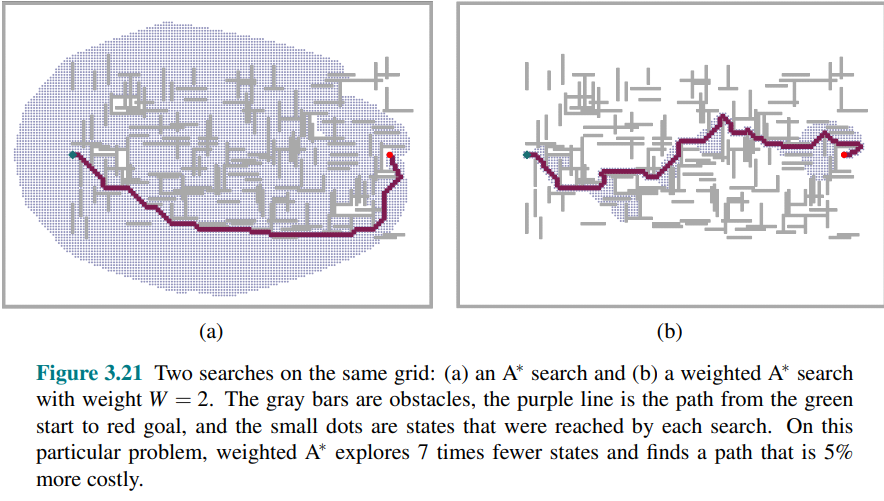
- In (a) it finds the optimal solution, but has to explore a large portion of the state space to find it
- In (b), a weighted
search finds a solution that is slightly costlier, bu the search time is much faster.
If the optimal solution costs
search: ( ) - Uniform-cost search:
, ( ) - Greedy best-first search:
, - Weighted
search:
You could call weighted
There are a variety of suboptimal search algorithms, which can be characterized by the criteria for what counts as “good enough”:
- bounded suboptimal search: we look for a solution that is guaranteed to be within constant factor
of the optimal cost - bounded-cost search: we look for a solution whose cost is less than some constant
- unbounded-cost search: we accept a solution of any cost, as long as we can find it quickly
One example is the speedy search which is a variant of the greedy best-first search that uses as a heuristic the estimated number of action required to reach a goal, regardless of the cost of those actions.
Memory-bounded search
One main issue of
Memory use is split between the frontier and the reached states. Using the “best-first search” implementation (see Best-First Search), a state that is on the frontier is stored in two places: as a node in the frontier and as an entry in the table of reached states. One possible improvement is to keep a state in only one of the two places, saving a bit of space at the cost of complicating the algorithm Another is to keep reference counts of the number of time a state has been reached, and remove it from the reached table when there are no more ways to reach the state.
Now let’s consider new algorithms designed to conserve memory usage:
Beam Search
Beam search limits the size of the frontier, keeping only the
Iterative-deepening
It is similar to Depth-limited and iterative deepening search.
Gives the benefit of
It is a very important and commonly used algorithm for problems that do not fit in memory.
In
For problems like the 8-puzzle where each path’s
For a problem where every node has a different
Recursive best-first search (RBFS)
Attempts to mimic the operation of standard best-first search, but using only linear space.
RBFS resembles a recursive depth-first search, but rather than continuing indefinitely down the current path, it uses the
If the current node exceeds this limit, the recursion unwinds back to the alternative path.
As the recursion unwinds, RBFS replaces the
In the following figure the algorithm is shown:

And in the following one, stages of a RBFS search for the shortest route to Bucharest.
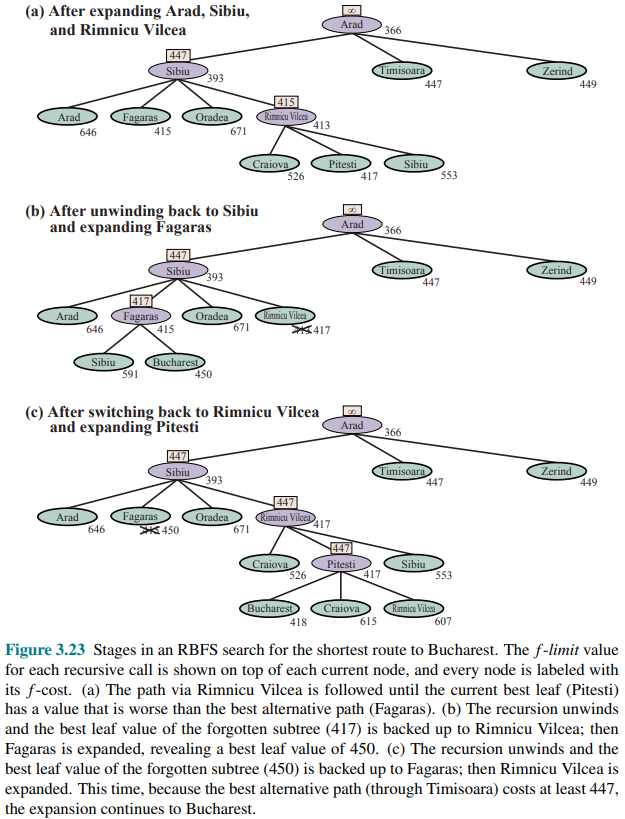
RBFS is optimal if the heuristic function
Its space complexity is linear in the depth of the deepest optimal solution, but its time complexity is rather difficult to characterize: it depends both on the accuracy of the heuristic function and on how often the best path changes as nodes are expanded. It expands nodes in order of increasing
To solve this, two algorithms variante are MA star (memory-bounded
With this information
The complete algorithm is described in the online code repository accompanying the source book.
On very hard problems, however, it will often be the case that SMA∗
is forced to switch back and forth continually among many candidate solution paths, only a small subset of which can fit in memory. (This resembles the problem of thrashing in disk paging systems.). The extra time required for repeated regeneration of the same nodes means that the problems that would be practically solvable by
Bidirectional heuristic search
With bidirectional search, it turns out that it is not individual nodes but rather pairs of nodes (one from each frontier) that can be proved to be surely expanded.
We use
They solve the same problem but different notation is required because different evaluation functions are required for example due to different heurstics depending on whether you are striving for the goal or for the initial state. We assume admissible herustics.
Consider a forward path from the initial state to a node
In other words, the cost of such a path must be at least as large as the sum of the path costs of the two parts (because the remaining connection between them must have nonnegative cost), and the cost must also be at least as much as the estimated
For any pair of nodes
The evaluation function that mimics the lb criteria is:
The node to expand next will be the one that minimizes this
This function guarantees that we will never expadn a node with
The following figure works through an example bidirectional search:
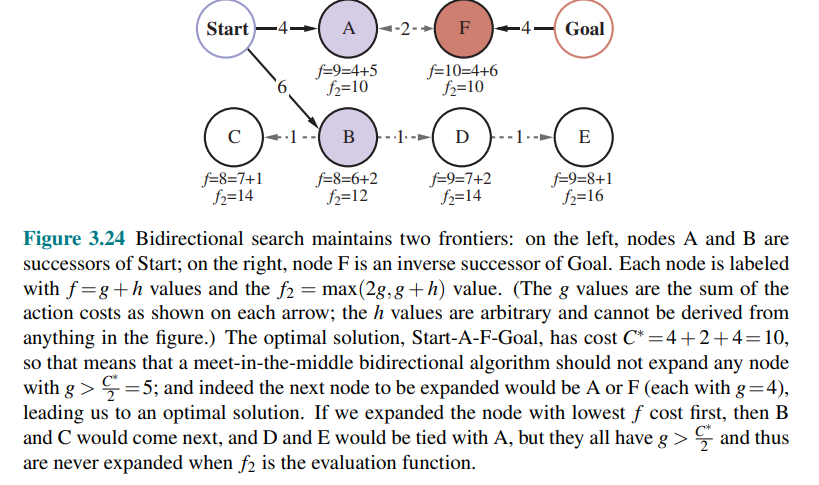
If an approach where the
An alternative called front-to-front search attempt to estimate the distance to the other frontier. Clearly, if a frontier has millions of nodes, it would be inefficient to apply the heuristic function to every one of them and take the minimum.
Bidirectional search is sometimes more efficient than unidirectional search, sometimes not.
Heuristic Functions
The accuracy of a heuristic affects the search performance.
Consider the 8-puzzle with
There is a long history of such heuristics for the 15-puzzle; here are two commonly used candidates:
: the number of misplaced tiles. : the sum of the distances of the tiles from their goal positions. Since tiles cannot move along diagonals, the distance is the sum of the horizontal and vertical distances, sometimes called the city-block distance or Manhattan distance.
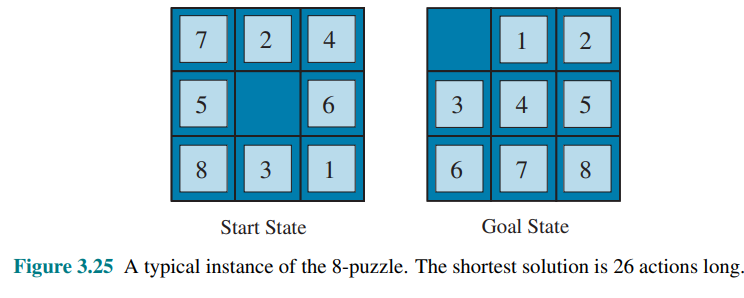
is admissible because any tile that is out of place will require at least one move to get it to the right place. is the sum of the distances of the tiles from their goal positions. It is admissible because all any move can do is move one tile one step closer to the goal. Tiles 1 to 8 in the start state of figure 3.25 give a Manhattan distance of: that is less than the true solution cost of 26.
The effect of heuristic accuracy on performance
One way to characterize the quality of a heuristic is the effective branching factor
If the total number of nodes generated by
For example, if
A better way to characterize the effect of
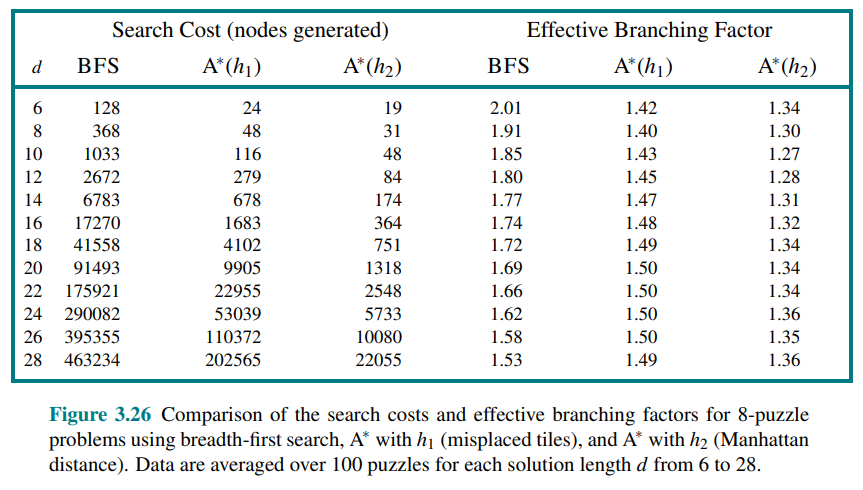
If one heuristic’s value is greater than or equal to another for all states (and strictly greater for some), we say that it dominates the other. In our case,
Generating Heuristics from relaxed problems
A problem with fewer restrictions on the actions is called a relaxed problem.
The state-space graph of the relaxed problem is a supergraph of the original state space because the removal of restrictions creates added edges. Therefore, any optimal solution to the original problem is by definition also a solution to the relaxed problem. However, the relaxed problem may have better (shorter) solutions if the added edges provide shortcuts. Hence, the cost of an optimal solution to a relaxed problem is an admissible heuristic for the original problem.
If a problem definition is written in a formal language, it is possible to construct relaxed problems automatically. For example, if the 8-puzzle actions are described as:
A tile can move from square X to square Y if
X is adjacent to Y and Y is blank
We can generate three relaxed problems by removing one or both of the conditions:
- A tile can move from square X to square Y if X is adjacent to Y. (leads to
, Manhattan distance) - A tile can move from square X to square Y if Y is blank.
- A tile can move from square X to square Y. (leads to
, misplaced tiles)
Notice that it is crucial that the relaxed problems generated by this technique can be solved essentially without search, because the relaxed rules allow the problem to be decomposed into independent subproblems.
If a collection of admissible heuristics
This composite heuristic picks whichever function is most accurate on the node in question.
Generating Heuristics from Subproblems: Pattern databases
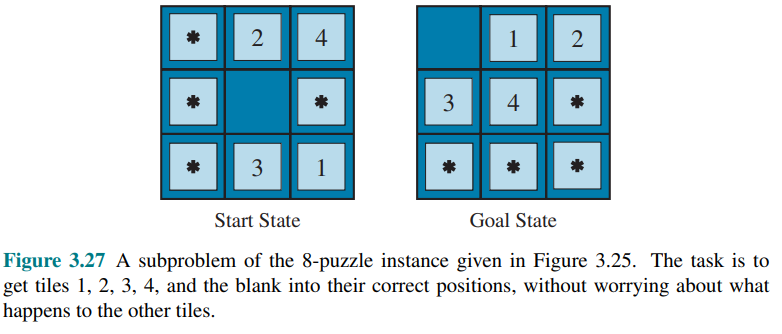
The idea behind pattern databases is to store exact solution costs for every possible subproblem instance.
In this example, every possible configuration of four tiles and the blank would be stored. In total there will be
The database itself is constructed by searching back from the goal and recording the cost of each new pattern encountered. The expense of this search is amortized over subsequent problem instances.
Each database yields an admissible heuristic, and these can be combined by taking the maximum value.
If we want to sum the costs, we need to ensure they don’t overlap in terms of moves. This leads to the idea of disjoint pattern databases. By recording only the moves involving the specific tiles of the subproblem, the total cost becomes a lower bound on the cost of solving the entire problem.
With such databases, it is possible to solve a 15-puzzle in a few milliseconds.
Generating Heuristics with landmarks
Route-finding services use precomputation of optimal path costs. This is time-consuming but needs only be done once and is amortized over billions of user requests.
We could generate a perfect heuristic by precomputing the cost of the optimal path between every pair of vertices, but that would require
A better approach is to choose a few landmark points (also called pivots or anchors) from the vertices. For each landmark
Given the stored tables, we can create an efficient (though potentially inadmissible) heuristic:
If the optimal path goes through a landmark, this heuristic will be exact; otherwise, it may overestimate the cost (inadmissible).
Some route-finding algorithms save even more time by adding shortcuts, which are artificial edges in the graph that define an optimal multi-action path.
That is called differential heuristic (because of the subtraction).
Consider for example a landmark that is somewhere out beyond the goal. If the goal happens to be on the optimal path from
“Consider the entire path from
to , then subtract off the last part of that path, from goal to , giving us the exact cost of the path from to goal”
The goal will still be a bit off the optimal path to the landmark, the heuristic will be inexact but still admissible. Landmarks that are not out beyond the goal will not be useful.
There are several ways to pick landmark points:
Random: Selecting random point is fast but it is better to spread the landmarksout so they are not too close to each other. A greedy approach is to pick a first landmark at random, then find the point that is furthest from that, and add it to the set of landmarks, and continue, at each iteration adding the point that maximizes the distance to the nearest landmark.
Past search requests: if you have logs of past search requests, then you can pick landmarks that are frequently requested in searches.
For the differential heuristic it is good if the landmarks are spread around the perimeter of the graph. Thus a good technique is to find the centroid of the graph, arrange
Learning to search better
An agent could learn how to search better, and this method rests on an important concept called metalevel state space. Each state in a metalevel state space captures the internal state of a program that is searching in an ordinary state space such as the map of Romania.
For example, the internal state of the
For example, consider figure we saw in A* Search:
This figure shows a sequence of larger nad larger search trees, these can be seen as depcting a path in the metalevel state space where each state on the path is an object-level search tree.
The path in the figure has only 5 steps, including one that is not especially helpful. But consider an harder problem i.e with much more misssteps; a metalevel learning algorithm can learn from these experiences to avoid exploring unpromising subtrees. The goal is to minimize the total cost of problem solving, trading off computational expense and path cost.
Learning Heuristics from experience
We have seen that one way to invent a heuristic is to devise a relaxed problem for which an optimal solution can be found easily. An alternative is to learn from experience.
For example consider as “experience” solving lots of 8-puzzles. Each optimal solution to an 8-puzzle problem provides an example (goal, path) pair. From these examples, a learning algorithm can be used to construct a function
Most of these approaches learn an imperfect approximation to the heuristic function, and thus risk inadmissibility. Usually machine learning and in particular reinforcement learning methods are used.
Some machine learning techniques work better when supplied with features of a state that are relevant to predicting the state’s heuristic value, rather than with just the raw state description. For example, the feature “number of misplaced tiles” might be helpful in predicting the actual distance of an 8-puzzle state from the goal.
We could take 100 randomly generated 8-puzzle configurations and gather statistics on their actual solution costs.
The most simple approach is using a linear combination:
where constants
Notice that this heuristic satisfies the condition