NLP - Lecture 9 - Text Representation - NLP from symbols to numbers
Natural language is inherently a discrete symbolic representation of human knowledge.
Sound is transformed into letters or ideograms and these discrete symbols are composed to obtain words, then:
 The composition of symbols in words and of words in sentences follow rules that both the listener and the speaker know.
The composition of symbols in words and of words in sentences follow rules that both the listener and the speaker know.
In NLP and ML, it is mandatory to encode text data into a suitable numerical form. The encoding is fundamental for good-quality results. “Trash in, Trash out!” -> anything that is not accurate of our data is trash outside.
How do we transform a given text into a numerical form to feed it into an NLP or ML algorithm? This conversion from raw text to a suitable numerical form is called text representation.
Feature Representation
A common step in any ML task, whether the data is text, images, video or speech. Nonetheless, feature representation is much more involved for text as compared to other data formats.
For image and speech is straightforward
Word and Meaning - What is the meaning of a word?
In classical NLP applications, our only representation of a word is as a string of letters, or an index in a vocabulary list. That’s not very satisfactory.
The linguistic study of word meaning is called lexical semantics. A model of word meaning should allow us to relate different words and draw inferences to address meaning-related tasks.
Lemmas and Senses
A word form is associated with a single lemma, the citation form used in dictionaries.
- For example, words forms sing, sang, sung are associated with the lemma sing
A word form can have multiple meanings (polysemous); each meaning is called a word sense, or sometimes a synset. For example: The word form mouse can refer to the rodent or the cursor control device.
Relation Synonymy
Lexical semantic relationship between words are important components of word meaning. Two words are synonyms if they have a common word sense.
- For example car and automobile.
Two words are similar if they have similar meanings.
- For example car and bycicle
Two words are related if they refer to related concepts:
- For example car and gasoline
Two words are antonyms if they define a binary opposition:
- For example hot and cold
One word is a hyponym of another if the first has a more specific sense:
- Notions of hypernym or hyperonym are defined symmetrically
- Example: car and vehicle
Words can have affective meanings, implying positive or negative connotations / evaluation:
- Example: happy and sad; great and terrible.
The linguistic principle of contrast says that difference in form is difference in meaning. In practice, the word synonym is therefore used to describe a relationship of approximate or rough synonymy
Relation: Similarity
While words don’t have many synonyms, most words do have lots of similar words. Words with similar meanings, not synonyms, but sharing some element of meaning:
- car, bicycle
- cow, horse
Knowing how similar two words are, can help in computing how similar the meaning of two phrases or sentences are. It isan an essential component of NL understanding tasks like question answering, paraphrasing, and summarization
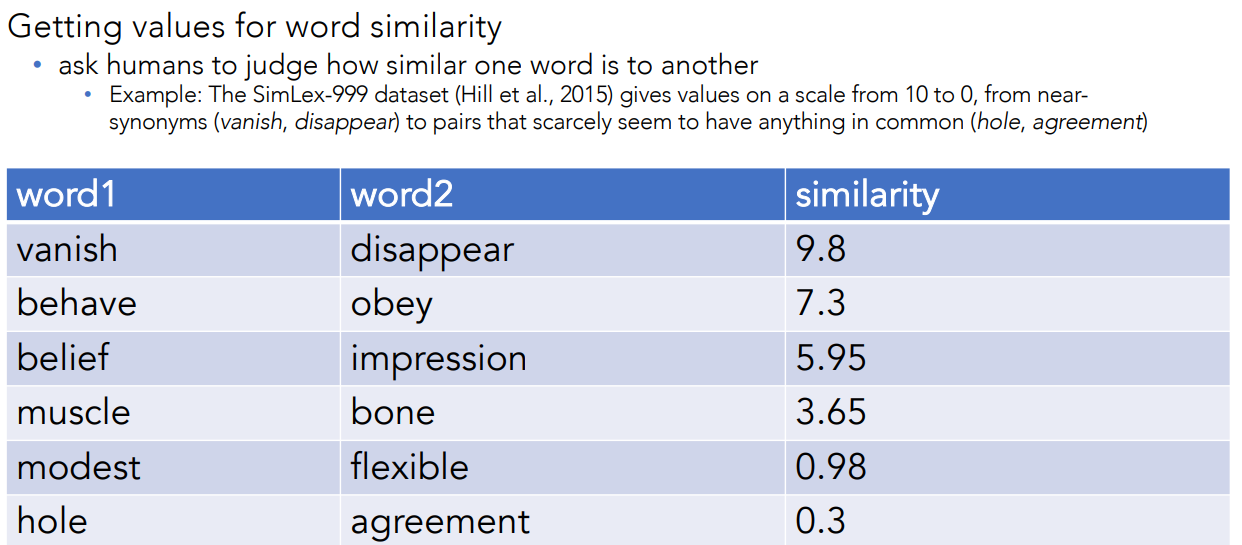
Ask Humans How Similar Two Words Are (The SimLex-999 dataset Hillet et al., 2015)
Relation: Word Relatedness
The meaning of two words can be related in ways other than similarity. One such class of connections is called word relatedness (also called “word association” in psychology).
Words can be related in any way, perhaps via a semantic field:
- coffee, tea: similar
- coffee, cup: related, not similar
Relation: Semantic Field
One common kind of relatedness between words is if they belong to the same semantic field. Words that
- cover a particular semantic domain
- bear structured relations with each other
Examples:
- Hospitals -> surgeon, scalpel, nurse, anaesthetic, hospital
- Restaurants -> waiter, menu, plate, food, chef
- Houses -> door, roof, kitchen, family, bed
Relation: Antonymy and Hyponymy
Senses that are opposites with respect to only one feature of meaning
Otherwise, they are very similar!
- Examples: dark/light short/long fast/slow rise/fall hot/cold up/down in/out
More formally: Antonyms can
- define a binary opposition or be at opposite ends of a scale
- long/short, fast/slow
- Be reversives
- rise/fall, up/down
One word is a hyponym of another if the first has a more specific sense. Notions of hypernym or hyperonym are defined symmetrically
- Example: car and vehicle
Connotation (Sentiment)
Words have affective meanings
- Positive connotations (happy)
- Negative connotations (sad)
Connotations can be subtle. All the following words can mean something that’s a copy of an original, but they feel very different:
- Positive connotation: copy, replica, reproduction
- Negative connotation: fake, knockoff, forgery
Evaluation (sentiment)
- Positive evaluation (great, love)
- Negative evaluation (terrible, hate)
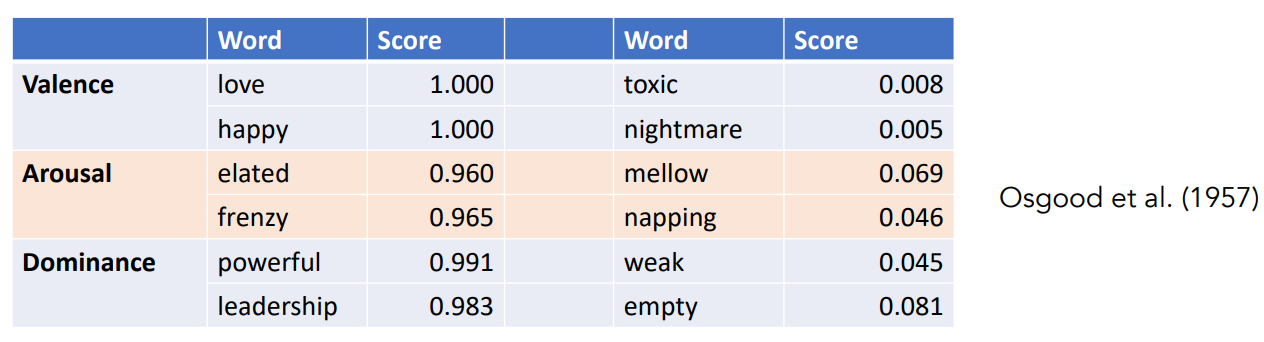
Words seem to vary along 3 affective dimensions:
- valence: the pleasantness of the stimulus
- arousal: the intensity of emotion provoked by the stimulus
- dominance: the degree of control exerted by the stimulus
Recapping
Concepts or word senses have a complex many-to-many association with words (homonymy, multiple senses). Have relations with each other
- Synonymy
- Antonymy
- Similarity
- Relatedness
- Connotation
How do we represent meaning in a computer?
Previously commonest NLP solution
- Use, e.g., Wordnet, a thesaurus (dizionario dei sinonimi) containing lists of synonym sets and hypernyms (“is a” relationship).

WordNet
WordNet (English) is a hand-built resource containing 117,000 synsets, sets of synonymous words (See wordnet.princeton.edu).
Synsets are connected by relations such as:
- hyponym/hypernym (IS-A: chair-furniture)
- meronym (PART-WHOLE: leg-chair)
- antonym (OPPOSITES: good-bad)
globalwordnet.org now lists wordnets in over 50 languages (but variable size/quality/licensing).
NLTK and WordNet
NLTK provides an excellent API for looking things up in WordNet

You can visualize the synsets using the website visuwords.com
Problems with resources like WordNet
-
A useful resource but missing nuance, e.g., “proficient” is listed as a synonym for “good”. This is only correct in some contexts.
-
Also, WordNet list offensive synonyms in some synonym set without any coverage of the connotations or appropriateness of words.
-
It is also missing new meanings of words, that is impossible to keep up to date.
-
It is subjective
-
Requires human labor to create and adapt.
-
Can’t be used to accurately compute word similarity
Text representation
There are a variety of approaches, depending both on the task to be addressed and the model to be employed
- Basic vectorization approaches
- Distributed representation Here, we’ll overview basic approaches, and just introduce distributed representation deferring its details when needed.
Text representation: Introducing scenario
We’re given a labeled text corpus and asked to build a sentiment analysis model.
The model needs to understand the meaning of the sentence. The crucial points are:
- Break the sentence into lexical units (i.e., lexemes, words or phrases)
- Derive the meaning for each lexical unit
- Understand the syntactic (grammatical) structure of the sentence
- Understand the syntactic (grammatical) structure of the sentence
The semantics (meaning) of the sentence is the combination of the above points. Any good text representation scheme reflect the linguistic properties of the text in the best possible way.
Vector Space Models
Text units, i.e., characters, phonemes, words, phrases, sentences, paragraphs, and documents, are represented with vectors of numbers.
In the simplest form:
- Vectors of identifiers, e.g., index numbers in a corpus vocabulary.
The most common way to measure the similarity between two text elements is the cosine similarity
The difference between representation schemes consists in how well the resulting vector captures the linguistic properties of the text it represents.
Word Representations
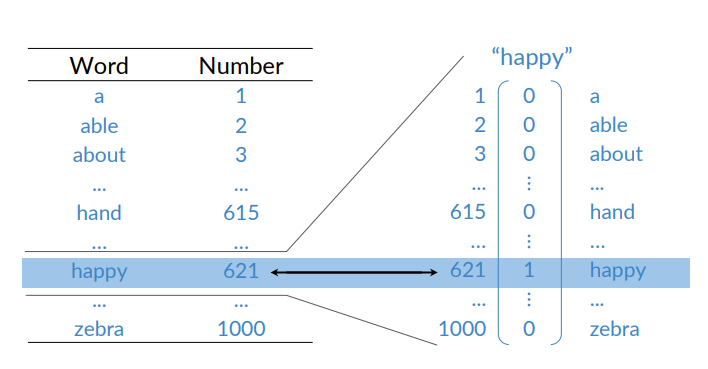
With word vectors, one will be able to create a numerical matrix to represent all the words in a vocabulary:
- Each row vector of the matrix corresponds to one of the words
There are several ways to represent words a numbers:
- Integers
- One-hot vectors
- Bag-of-words
Basic approaches
Map each word in the vocabulary
Example:
Let’s consider a toy corpus:
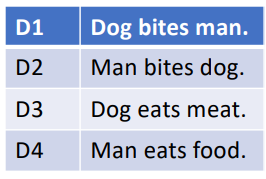 Lowercasing text and ignoring punctuation the vocabulary is comprised of six words,
Lowercasing text and ignoring punctuation the vocabulary is comprised of six words,
Integers
We can assign a unique integer to each word. Pro: it’s simply, cons: little semantic sense.

One-hot encoders
Represent the words using a column vector where each element corresponds to a word in the vocabulary.
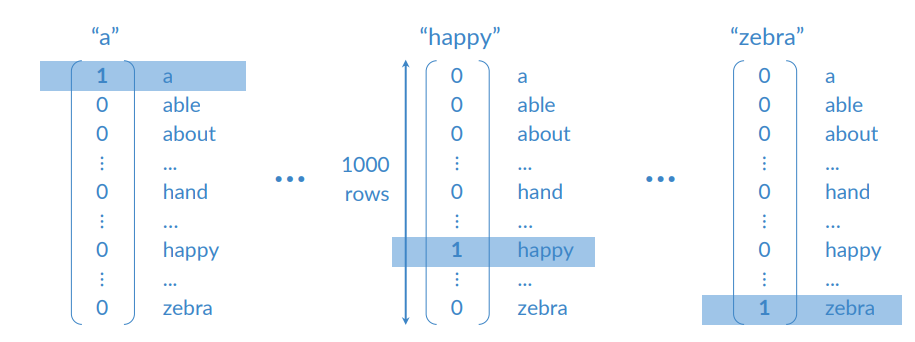
Each word
The representation for individual words is then combined to form a sentence representation. Example:
V= [dog, bites, man, eats, meat, food]- • ID: dog =1, bites = 2, man =3, meat = 4, food = 5, eats = 6, i.e dog = [1 0 0 0 0 0] or man = [0 0 1 0 0 0], etc.
We can create a document Document D1=[[1 0 0 0 0 0] [0 1 0 0 0 0] [0 0 1 0 0 0]].
Similarly, for D2, D3, and D4.
One-hot vectors
Words can be considered categorical variables. Simple to go from integer to one-hot vectors and back. Mapping the words in the rows to their corresponding row number.
One-Hot vectors cons
The size of a one-hot vector is proportional to the size of
- Many real-world corpora have large vocabularies
- Sparse representation (i.e., most of the entries are 0)
Not fixed-length representation:
- A text with 10 words gets a longer representation than a text with 5 words.
- Most learning algorithms work with feature vectors of the same length.
If words are atomic units, there’s no notion of similarity:
- Consider run, ran, and apple. Run and ran have similar meanings as opposed to run and apple, but they’re all equally apart
- Semantically, very poor at capturing the meaning of the word in relation to other words
Not capable of handling the out-of-vocabulary (OOV) problem:
- There is no way to represent new words from test sets, not present in the training corpus.
Example In a web search, if a user searches for “Seattle motel”, we would like to match documents containing “Seattle hotel” But:
motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
These two vectors are orthogonal. But there is no natural notion of similarity for one-hot vectors!
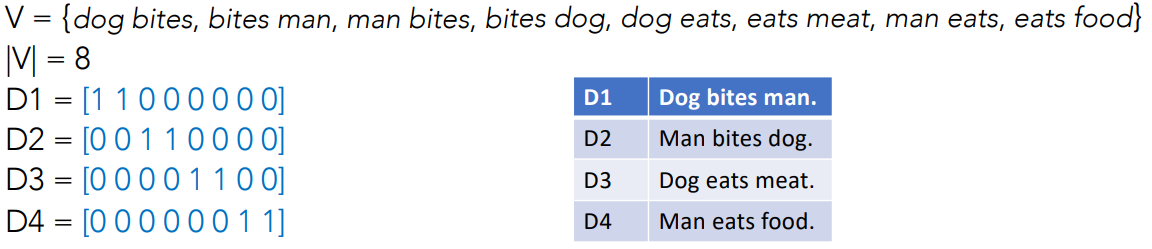
Bag of Words
Bag of Words (BoW) represents the text as a bag (collection) of words while ignoring the order and the context
The intuition is that a text is characterized by a unique set of words. If two text pieces have the same words, then they are similar.
BoW maps words to unique integer IDs between 1 and
Each document in the corpus is converted into a
Obs.: sometimes we don’t care about the frequency of occurrence of words, but want to represent whether the word exists or not in the text.
Example:
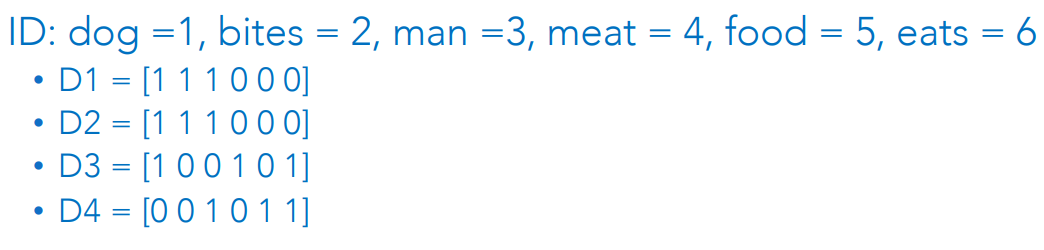
BoW pros and cons
Pros:
- Simple to understand and implement.
- Documents having the same words will have their vector representation similar in Euclidean space
- Fixed-length encoding for any sentence of arbitrary length Cons:
- The size of the vector increases with the size of the vocabulary
- Sparsity continues to be a problem
- It does not capture the similarity between different words that mean the same thing
- “I run”, “I ran”, and “I ate”
- The three BoW vectors are all equally apart
- No way to handle out-of-vocabulary words
- Word order information is lost
- D1 and D2 have the same representation in the example
Bag of N-grams
All the representation schemes seen so far treat words as independent units. There’s no notion of phrases or word ordering.
The bag of n-grams breaks texts into chunks of
The corpus vocabulary,
Example: 2-gram (bigram) model
 Observation: increasing the value of
Observation: increasing the value of
Bag of N-grams pros and cons
Pro:
- Some context and word-order information is captured
- The vector space can capture some semantic similarity
Cons:
- As n increases, dimensionality (and therefore sparsity) quickly increases
- No way to address the OOV problem
TF-IDF
Term Frequency-inverse Document Frequency (TF-IDF) introduces the notion of importance of words in a document. Commonly used representation scheme for information-retrieval systems.
Intuition: If a word
The importance of
TF and IDF are combined to form the TF-IDF score.
TF stands for term frequency measures how often a term or word occurs in a given document. The measure is normalized by the length of the document:
IDF stands for inverse document frequency measures the importance of the term across a corpus:
The score TF-IDF =
Example, with a size of corpus 
The TD-IDF vector representation for 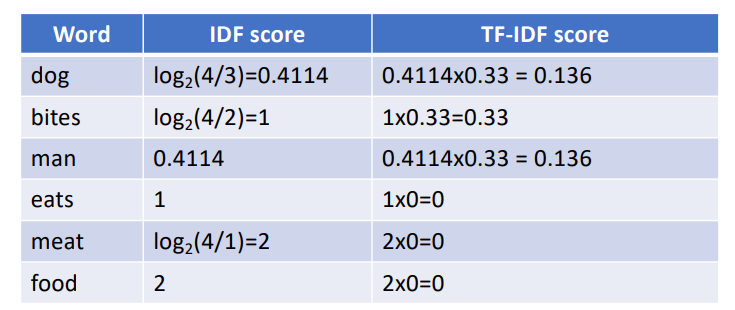
There are several variations of the basic TF-IDF formula used in practice
- Avoiding possible zero divisions
- Do not entirely ignore terms that appear in all documents
TF-IDF could be used to compute the similarity between two texts using Euclidean distance or cosine similarity.
It still suffers from the curse of dimensionality as the previous vectorization methods.
Distributional semantics
It is difficult to define the notion of word sense in a way that computers can understand
We take a radically different approach, already foreseen in the following works: “The meaning of a word is its use in the language” - Ludwig Wittgenstein, Philosophical Investigations, 1953.
Distributional semantics develops methods to quantify semantic similarities between words based on their distributional properties, i.e., neighboring words.
The basic idea lies in the so-called distributional hypothesis:
- Language elements with similar distributions have similar meanings;
- The meaning of a word is defined by its distribution in language use.
 The basic approach is to collect distributional information in high-dimensional
vectors, and to define distributional/semantic similarity in terms of vector
similarity.
The basic approach is to collect distributional information in high-dimensional
vectors, and to define distributional/semantic similarity in terms of vector
similarity.
Word vectors
We will build a dense vector for each word, chosen so that it is similar to word vectors that appear in similar contexts, measuring similarity as the vector dot (scalar) product

The obtained vectors are called word embeddings. Each discrete word is embedded in a continuos vector space. They are a distributed representation.
Word embeddings can be used to visualize the meaning of a word
The most commonly used methods are two:
One: listing the words in a vocabulary
- Locality-sensitive hashing (LSH) can be used, which hashes similar input items into the same buckets with a high probability.
Two: project the
dimensions of a word embedding down into 2 dimensions - t-distributed stochastic neighbor embedding (t-SNE) is used, preserving metric properties.

The basic approaches to vector representation share key drawbacks.
- To overcome these limitations, methods to learn low-dimensional representation were devised.
- They use neural network architectures to create dense, low-dimensional representations of words and texts
Distributed representation schemes significantly compress the dimensionality. This results in vectors that are compact and dense.
Based on the distributional hypothesis from linguistics:
Words that occur in similar contexts have similar meanings