SC - Lezione 14
Checklist
Domande, Keyword e Vocabulary
- vector function
- vector-valued function
- Contour Plot
- Newton Method for non-linear systems
- Jacobian Matrix
- What’s the difference between gradient and Jacobian?
- Taylor Series
- Quadratic Convergence of Newton Method
- Newton-like Method (o damped Newton method)
- Damp parameter
- Search Direction
- Fixed Point Problem for vectorial-valued functions
- Contraction Mapping
- Dominant eigenvalue of the Jacobian matrix of
- Relationship between
and Fixed Point Problem
Appunti SC - Lezione 14 - Systems of non linear equations
Let
Let us consider this equations:
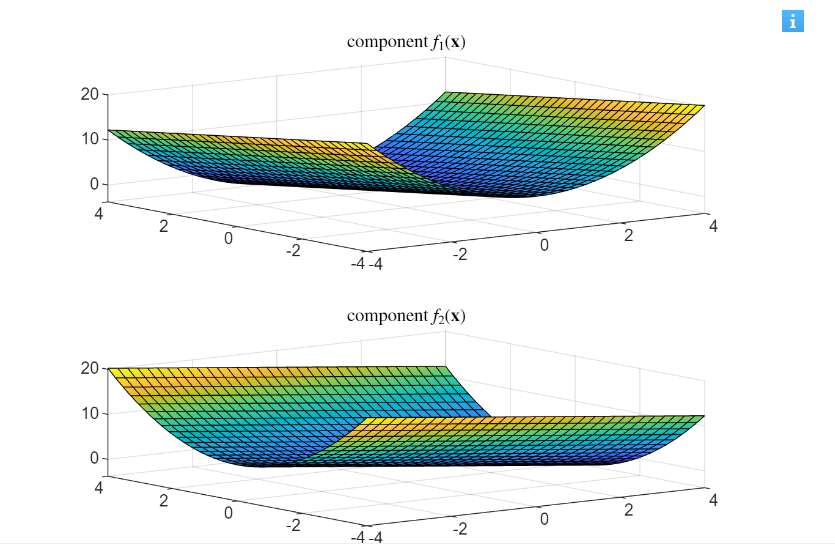
We have that n=2 and the variables are
fsolve
In matlab we can use this command to solve the non-linear system
contour plot
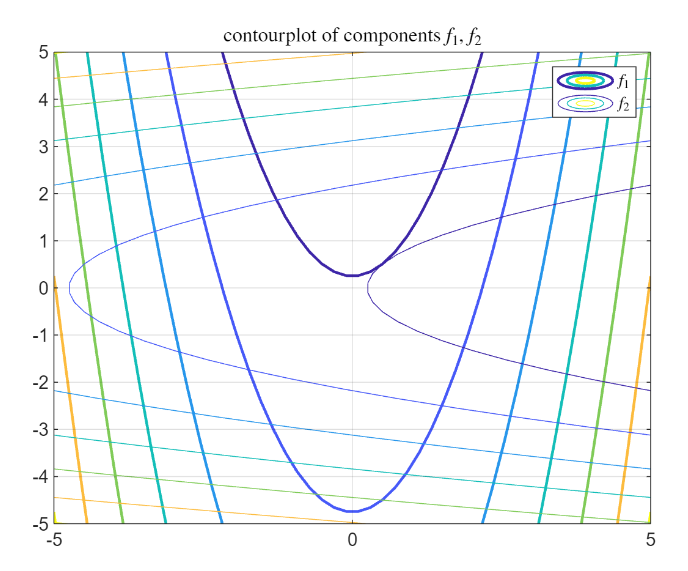 Consider the first function
Consider the first function
So the graphical solution of 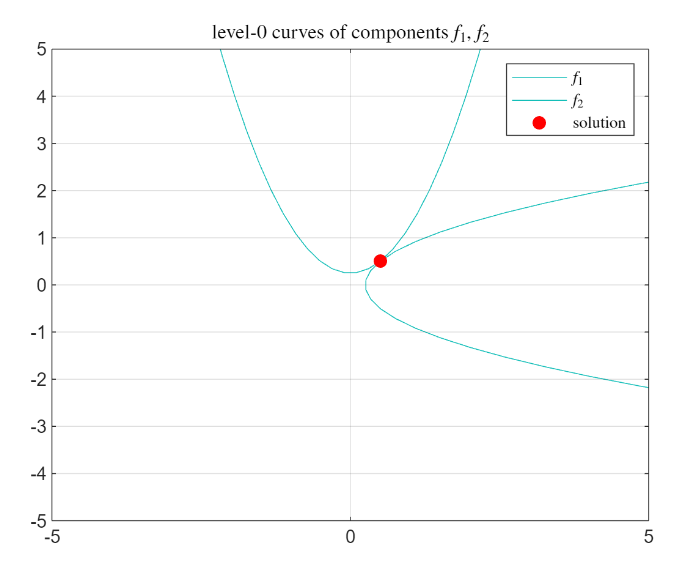
Newton Methods for solving non linear system
A non-linear system
We recall that for 1 variable we have that:
What we consider now is just this but generalized to multivariable context.
Jacobian Matrix
Since we are in a multivariable context, we must consider the Jacobian Matrix of
Jacobian Matrix
It’s the matrix with all the first-order partial derivatives of a vector-valued function.
For a function
the jacobian matrix is an matrix given by:
J = \begin{bmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \dots & \frac{\partial f_1}{\partial x_n} \ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \dots & \frac{\partial f_2}{\partial x_n} \ \vdots & \vdots & \ddots & \vdots \ \frac{\partial f_m}{\partial x_1} & \frac{\partial f_m}{\partial x_2} & \dots & \frac{\partial f_m}{\partial x_n} \end{bmatrix}$$
What's the difference between gradient and Jacobian?
The Gradient is a vector of partial derivatives of a scalar-valued function
The Jacobian is a matrix of the partial derivatives a vector-valued function The gradient is a special case of the Jacobian when the function has a single output
For example, consider a simple function with two variables; it has two partial derivatives, which can be combined to form the gradient vector.
When dealing with a vector-valued function, each element of the vector has its own gradient. This idea extends to the Jacobian matrix, which is composed of the gradients of each component in the vector-valued function.
The Jacobian matrix is very important in Artificial Intelligence
So the formula for solving these non linear system is:
The rows of the Jacobian matrix are the gradient of the components of
Deriving the method from Taylor Series
The method can be easily derived from the Taylor series of a vectorial function F at
omitting the second order term and looking for the next approximation
The second order term represents the error of the approximation and is omitted because we don’t know it.
The method can be written, at each step
Such that the update solution will be:
Note that:
Some properties
the newton’s method is a local method with quadratic convergence rate. It converges and the number of correct digits of the approximations doubles at each step.
The Newton’s method for nonlinear systems requires a function for computing the Jacobian matrix
JF = @(x) [2*x(1) -1; -1 2*x(2)];
maxiter = 30; xiniz = [0.1,0.2]'; tol = 1e-8;
rNEW = NewtonSystems(F,JF,xiniz,tol,maxiter)Then we have another example in three dimensions
Damped Netwon’s Methods (Newton-like method)
A useful variant of Newton’s method is the damped Newton’s methods, that consists in considering in the updating formula a parameter
Method Definition You compute first the correction as in Newton Method:
But instead of using it all you just use a part of it:
It’s called the damp parameter in this case.
How to compute this parameter? It’s very easily theoretically because what you want is just that your functions becomes zero. At a certain point
In the following approximation the norm of the function must be less than 10 and so on with each iteration.
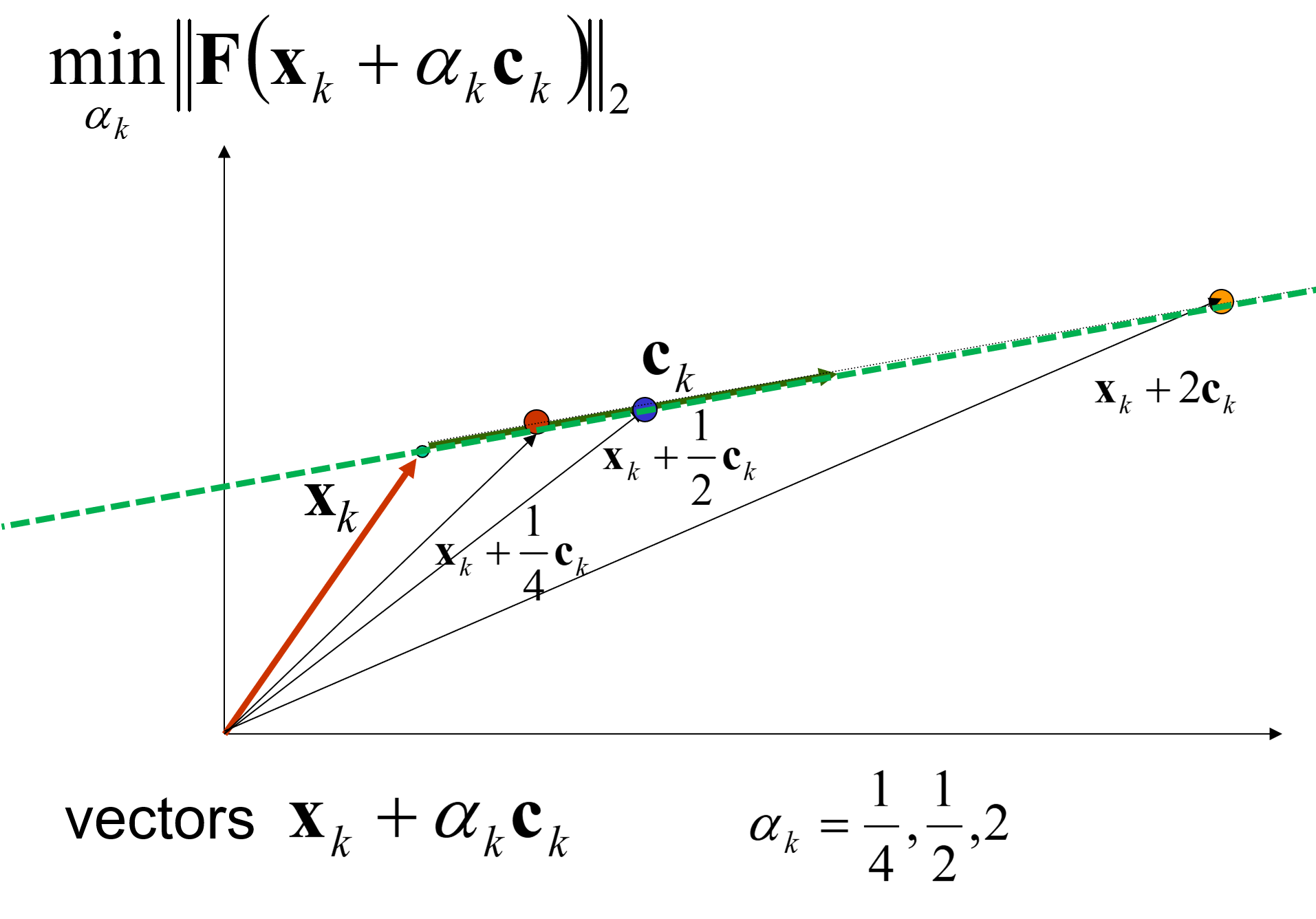
What is the best way to do that? minimize this quantity:
Remember this is a function of one variable, a scalar function, so you want to minimize respect to the choice of
Fixed Point Problem

Let
nota:
è una funzione vettoriale
Fixed Point of a function
The fixed point problem can be solved by the fixed point method:
which is a local method with linear convergence rate.
Suppose that you have a solution in a certain set:
Contraction Mapping In
Means that
if
The modulus of the dominant eigenvalue of
TL:DR if the spectral radius
F(x)=0 and Fixed Point Problem
The problem
Is equivalent to
We see in matlab that the method diverges since the spectral radius of
Matlab code:
G = @(x) [x(2)^2+0.25; x(1)^2+0.25];
xiniz = [0.6,0.6]';
x = xiniz;
for i = 1:100
x = G(x);
end
x
JG = @(x) [ 0 2*x(2); 2*x(1) 0]; % Jacobian matrix of G at point x
[X,L] = eig(JG(r))