Bayesan Theory of Decision
See also:
- [[../../Statistics & Probability & Game Theory/Statistics/Probability, Sample Spaces and Events, Independent Event, Conditional Probability and Bayes Theorem (Statistics)|[STATISTICS] Probability, Sample Spaces and Events, Independent Event, Conditional Probability and Bayes Theorem]] for the statistics foundations required to understand this chapter
- Source: F.Camastra,A.Vinciarelli, Machine Learning for Audio, Image and Video Analysis, (5° Chapter)
The fundamental idea in BTD is that a decision problem can be solved using probabilistic considerations.
Dataset definition: consider a set of pairs
Assume we have a dataset of i.i.d data: independent and identically distributed. This means they are drawn independently accordingly to the probability density
Assume a binary classificator with two classes.
Assume all the relevant probabilities are known.
Bayes Theorem
The Bayesian Decision Theory is based on this theorem: defined as:
- Reads as: the conditional probability of
given datapoint is given by the conditional probability of given class multiplied by probability of class , normalized by the probability of
In the context of Bayes Theorem:
: is called posterior probability is called likelihood is called prior probability is called evidence
Informally we say that:
Posterior Probability simplified formula
Evidence in the case of two classes is calculated as:
Being a normalization factor, it can be neglected, and we can conclude that:
When
Demonstration of the theorem
Recall the definition of conditional probability (also called joint probability).
The joint probability density of finding a pattern X in the class
But the same joint probability can also be written as:
Plugging equation the two equation together we have:
Divide by
Bayesian Decision Rule
Intuition - Boys and Girls Example
Imagine a classroom with boys and girls. The examiner has a list of surnames but doesn’t know each student’s gender. When a student comes forward after being called, they “reveal” which of the two possible states of nature they belong to.
States of Nature: the classroom is our natural world, the state of nature is the class label
Probabilistic assumption: since the examiner doesn’t know the true state (i.e if the student is a boy or girl) it make sense to treat
Prior Probability Decision Rule
Before seeing anything else, the examiner only knows how many boys and girls are in the class.
Let
With no extra information, the decision must rely on these priors:
Joint Probability Decision Rule
We said that
When
Consider a binary classifier.
We observe that for a pattern
The probability error
Then, deciding
If we plug the Bayes Theorem and neglect evidence we obtain that:
Optimality of Bayes Decision Rule: Bayes decision rule (or Bayes classifier) is optimal, i.e., no other rule (or classifier) exists that yields lower error.
Loss function
In many academic papers, the concept of a “Loss Function” is frequently encountered.
When considering more than two classes we talk of a loss function. This lets the classifier take actions that aren’t simple class assignment for example, choosing to reject a decision.
postal OCR example
In postal OCR systems, the allowed error rate is extremely low. If the device reading an address makes more than 1.5% mistakes, the correct action is to reject the input rather than guess. A loss function makes this kind of behavior possible.
The loss function assigns a “cost” to every possible action. This cost turns classification errors into meaningful decisions, and lets us say that some mistakes are worse than others.
For instance, suppose that the cost of a misclassification of a pattern can depend by the apriori probability of the membership class. Misclassifying a pattern that belong to class
Conditional and expected Risk
- Let
be the finite set of possible classes the pattern belong to - Let
be the set of the possible action of the classifier. - Let
be the posterior probability
The loss function
Conditional risk is defined as:
- So for each possible true class, we multiply the penalty of choosing
by the posterior probability of that class, and sum over all classes.
When we observe a pattern
A decision rule
Given a decision rule
In theory we want to minimize this, but in practice we can’t compute the integral because we only have a finite dataset.
So we replace it with the empirical risk:
is the number of patterns in the dataset
This is essentially the Bayesian Decision Rule written in terms of the empirical risk. During training, the error we measure is the empirical risk.
As the dataset grows, the empirical risk approaches the expected risk, which is why we say that empirical risk is consistent:
Binary Classification Case
We now apply the previous ideas to the special case of binary classification.
In this case, choosing
The conditional risks become:
The Baye decision rule becomes:
Decide
This same rule can also be expressed in terms of posterior probabilities.
To show this, we have to demonstrate that
Scambiando questi valori otteniamo:
And we obtain:
Since the posterior probabilities come from Bayes’ theorem, we substitute them explicitly (and drop the evidence term, which appears on both sides):
Now we isolate everything on one side:
- The right-hand side is called likelihood ratio
- The left-hand side acts as a threshold.
If the likelihood ratio exceeds this threshold—which does not depend on the particular pattern
So the bayes decision rule in terms of posterior probabilities (binary case) becomes:
Decide
These expressions are positive because the loss associated with making an error for example
We check this because if one of the terms were negative, the direction of the inequality would flip. In general, these quantities are positive.
In summary, the classifier compares the likelihood ratio:
with a threshold that does not depend on the pattern. If the ratio is larger, we choose
Zero-One Loss Function
In order to find a decision rule that minimizes the error rate, we must first degine an appropriate loss function.
The zero-one is a particular type of Loss function. Introducing a specific loss function is fundamental to do computations for the likelihood ratio disequation.
The zero-one loss fuction assigns 0 (correct) if the action
Formally defined as:
is the action that the classifier makes, is the class means the probability that the classifier take the action and the posterior probability is
Property: zero-one loss function assigns no penatly to the correct decision, and viceversa any error has penalty one. All errors are evaluated in the same way.
Now apply the zero-one loss function to the conditional risk, we get:
is only for the correct case and for the remaining cases it’s . - Therefore, we can rewrite the summation as
because the only term that does not appear in this sum is when , i.e is always , a constant so it disappear from the summation - Recall the the sum of the probabilities is one, therefore
- to pass from left to right term, just add and subtract
: - by definition (of probability) the first term plus
is 1
- to pass from left to right term, just add and subtract
We want to minimize
Discriminant Functions
The use of discriminant functions is a popular approach to make a classifier.
In neural networks, the output can be interpreted as a score, and classification is performed by comparing this score against thresholds. For example, if the output is larger than a certain threshold, the input is classified as belonging to Class A; otherwise, it belongs to Class B, and so on.
This approach can also be represented within the framework of Bayesian decision theory. By using discriminant functions, we temporarily set aside considerations of risk and conditional probabilities and adopt an alternative method. However, we will ultimately show that these two approaches are equivalent. Specifically, selecting the class with the highest discriminant function value is equivalent to selecting the class with the highest posterior probability.
Set of discriminant functions: Given a pattern
Definition of discriminant function:
Discriminant function rule
Assign the pattern
Assign the data point to the discriminant function whose output is the highest value for that datapoint.
Equivalence between discriminant function and bayesian rule
Now we show that it is easy to represent a Bayes classifier in the framework of the discriminant functions.
For each conditional risk
Consider the Zero-One Loss Function, ad apply the definition to get:
- we neglect
as constant and obtain
Justification: An important property of discriminant functions is that they are not uniquely determined. If we add each function a constant, we get a new set of discriminant functions which produces the same classifications produced by the former set.
Now, using the explicit definition of posterior probability by Bayes Theorem, we obtain:
Let
The evidence can be neglected hence we obtain as final formula:
Decision Regions: the use of such set of discriminant functions induces a partition a partition of
Note
A surface has 3 dimensions, an hypersurface has more than 3 dimensions, i.e 4,5,100 dimensions
Discriminant Functions - Binary Classification Case
In this case we have two classes, therefore two discriminant functions
The two can be combined in an unique discriminant function:
A pattern
Decision Rule Binary Classification Discriminant Functions
Decide
This is obivious because,
Apply the posterior probability definition as before and the log trick:
This is true for both gamma 1 and gamma 2, then we remember that gamma is defined as
grouping together similar terms:
Prerequisite for Gaussian Likelihood: Gaussian Density
Probability density function
Is a non negative function
Expected value of a scalar function
We define the expected value of a scalar function
If
Univariate Gaussian Density
The univariate gaussian function (or univariate normal density)
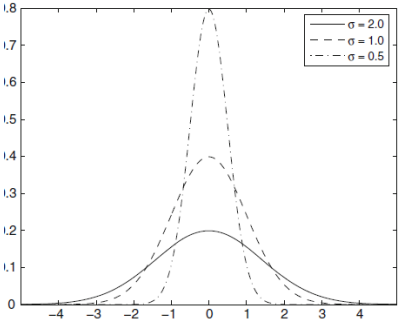
where
And where
Now we introduce one thing that we need:
Kurtosis
The Kurtosis is defined as a:
We are interested because, in the gaussian distribution, the Kurtosis is always 3.
The Kurtosis is the simplest way (but the noisiest) to assess if a distribution is a gaussian.
Property of the Gaussian Density
We are interested in the gaussian density because is fully characterized by the mean
The Gaussian density is very important because:
- The aggregate effect of the sum of large number of independent random variables leads to a normal distribution.
Since the patterns can be considered as ideal prototypes corrupted by a large number of random noise, then the Gaussian is a quite good model to represent the probability distribution of the patterns.
Multivariate Gaussian Density
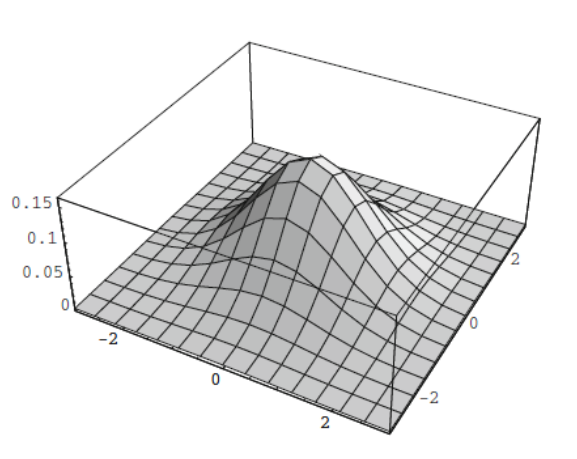
Definition of Multivariate Gaussian Density: Let
Let’s unpack this equation:
- The left term is a fraction
- at the denominator we have the determinant of the covariance matrix
- at the denominator we have the determinant of the covariance matrix
- The right is an exponential with an argument.
is the mean vector, similarly defined as in univariate gaussian density. The difference is if we have 10 components i.e 10 variables, we will have a vector with 10 values that represents the mean. is the covariance matrix, the equivalent in multiple dimension of the variance.
mean vector: is given by
Covariance Matrix
The covariance matrix is given by:
Properties of
- Is always symmetric:
- Positive semidefinite, that is all its eigenvalues
are nonnegative ( )
If
the expectation operator computed on
The last value is also called the covariance between
Property 2: if
Eliminating redundant features lead to simpler models. Ofc you can’t eliminate both otherwise you lose the information.
Related topic: The Curse of Dimensionality
Proof of covariance matrix is always semidefinite
Semidefinite positive means that for any
If
For the linearity of the expectation operator, we substitute
- where
The expectation operator on
Mahalanobis distance
Defined as:
When
Discriminant Functions for Gaussian Likelihood
In this section we investigate the discriminant functions in the special case that the likelihood
Recall that Discriminant Functions can be equal to posterior probability. This is shown in Equivalence between discriminant function and bayesian rule section.
So we rewrite again the equation of the log-discriminant function:
Suppose that
Plug Multivariate Gaussian Density equation into
Discriminant Funtions for Gaussian Likelihood equation 1 - Full passages
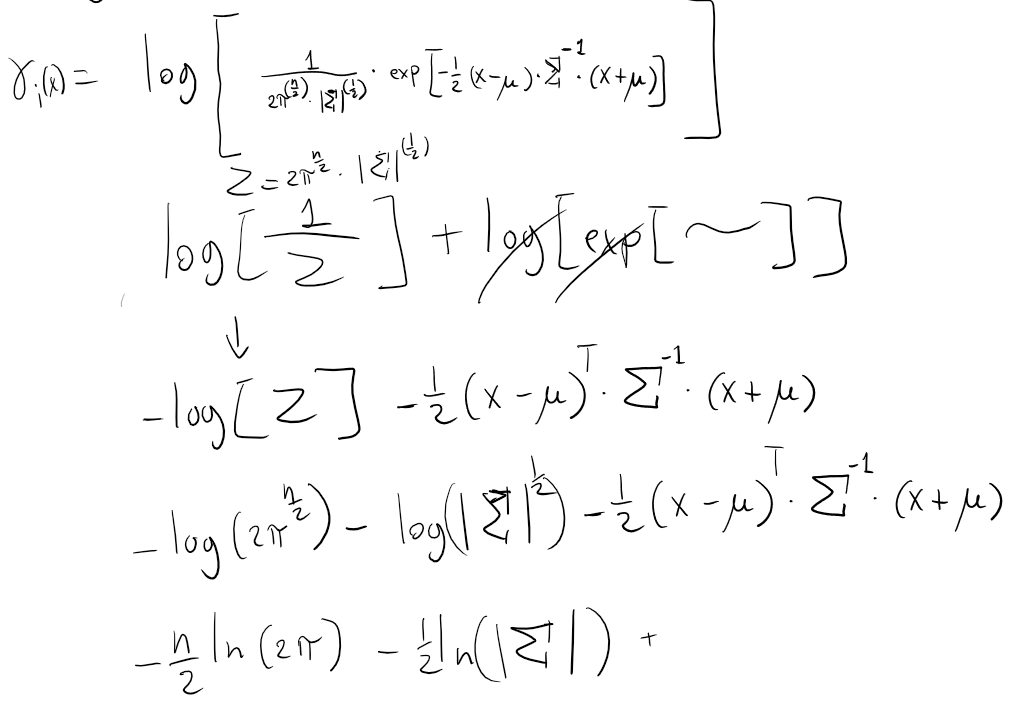
Discriminant Functions for Gaussian Likelihood - General Formula
This formula will be often referred in the specific cases that follows.
Case 1: Features are Statistically Independent
When the features are statistically independent, the non-diagonal elements of the covariance matrix
assumption: assume for simplicity that each feature
Under this further condition,
- Inverse of Cov matrix:
- Determinant of Cov matrix:
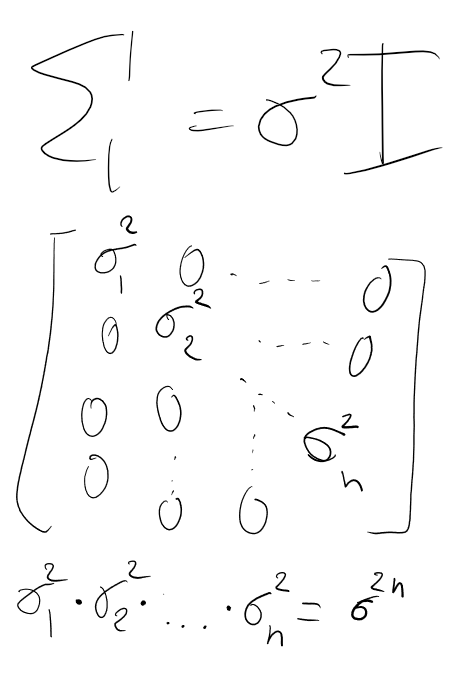 Substitute these terms into the General Formula to obtain:
Substitute these terms into the General Formula to obtain:
Some comments:
- when
corresponds to the identity matrix, the Mahalanobis distance becomes euclidean distance, as we can see in can be simplified becomes
Notice that
Formula 1: Statistical Independent Features
Case 1.1 - Statistically Independent Features, Prior Probabilities are all equal
Recall Bayes Theorem that prior probability is
Formula 1.1 - Statistically Independent Features, Prior Probabilities all equal - Minimum Distance Classifier
Definition: this is called minimum-distance classifier and apply the minimum-distance rule (i.e K-Means).
The mean vector (called centroid in the K-means),
Case 1.2 - Statistically Independent Features, Prior probabilities not all equal
If the prior probabilities are not all the same, the decision is influenced in favor of the class with the highest apriori probability.
In particular, if a pattern
Consider the Formula 1 Statistical Independent Features
Using properties of the inner product, it can be rewritten as:
Apply the following simplifications:
is the norm of is the norm of is equal to since So we can rewrite it as:
Since
That is a linear expression of the following form:
This is called linear discriminant function or linear classifier
Formula 1.2 - Statistically Independent Features, Prior Probabilities NOT all equal - Linear Classifier
Of the form:
Case 2: Covariance Matrix is the Same For All Classes
This corresponds to the situation in which the patterns fall in hyperellipsoidal clusters of equal size.
Consider Discriminant Functions for Gaussian Likelihood - General Formula
Since the first two tersm are independent of
Formula 2 - Covariance Matrix Same For All Classes, General Formula
Case 2.1 Covariance Matrix Same for all Classes, Prior probability are all equals
The last term be neglected.
Thee minimum mahalanobis distance rule, where to classify a pattern
Formula 2.1 Covariance Matrix Same for all Classes, Prior probability are all equals
If the prior probabilities are not all the same, the decision is influenced in favor of the class with the highest a priori probability. In particular, if a pattern x has the same distance from two or more different mean vectors, the decision rule choose the class
Case 2.2 Covariance Matrix Same for all Classes, Prior Probability NOT are all equals
Consider Formula 2 - Covariance Matrix Same For All Classes, General Formula
The term
Hence the discriminant functions are:
Also in this case the discriminant function are linear. The resulting decision surface between two adjacent region
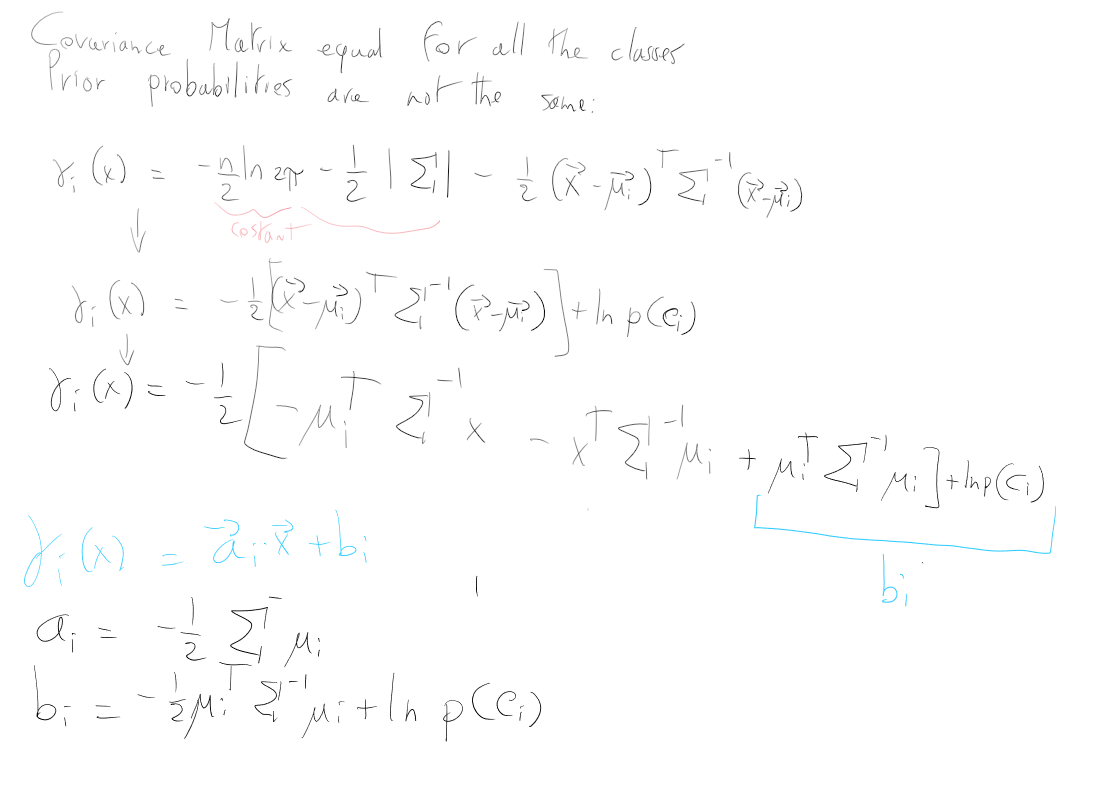 Here’s the passages to distinguish
Here’s the passages to distinguish 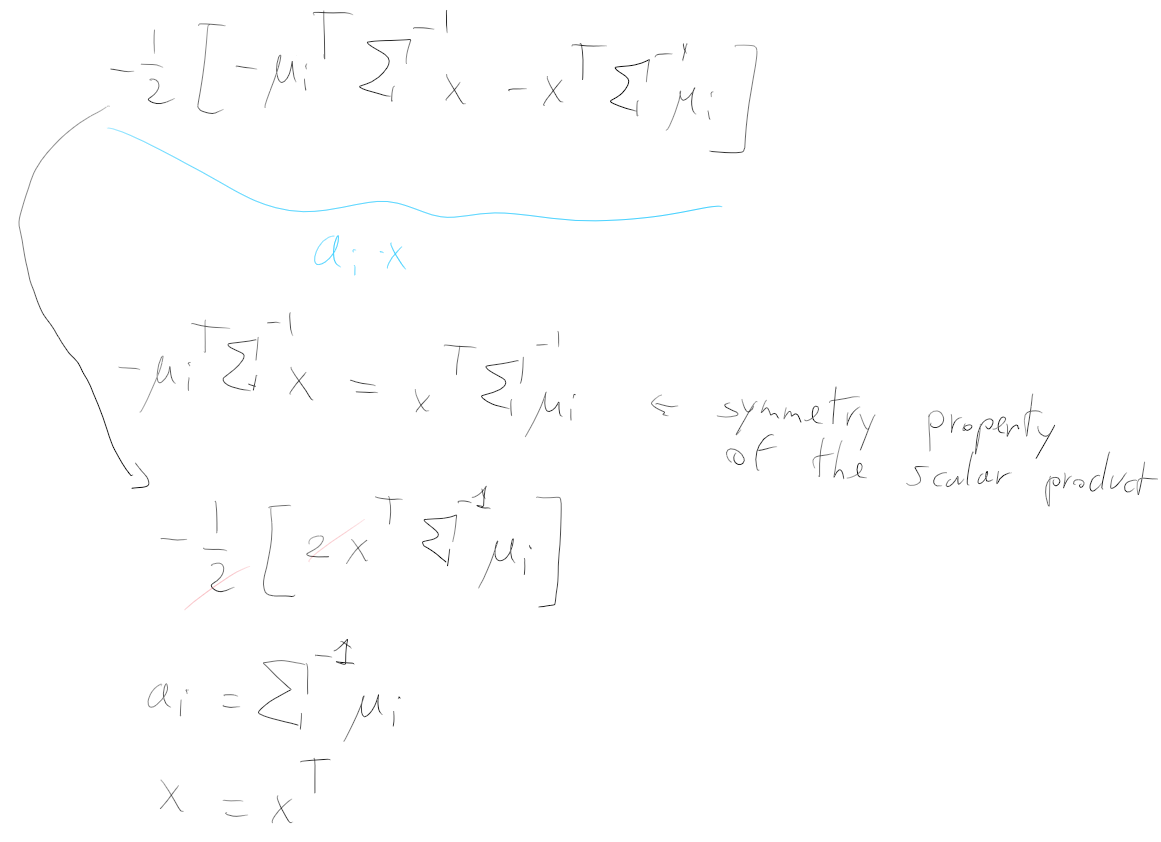
Formula 2.2 Covariance Matrix Same for all Classes, Prior Probability NOT are all equals
Of the form:
Case 3 - Covariance Matrix Is Not The Same for All Classes
The most general case that you can find in real data.
Consider again: Discriminant Functions for Gaussian Likelihood - General Formula
Formula 3, Covariance Matrix Not The Same For all Classes
Notice that the unique term that is an additive constant is
where:
The discriminant functions in this case are nonlinear. In particular, in the binary classifiers the decision surfaces are hyperquadrics.
The results obtainted for the binary classifiers can be extended to the case of more than two classes, fixed that are two classes that share the decision surface.
Optimality: a linear classifier is optimal only when Case 2 Covariance Matrix is the Same For All Classes.
Summary table - Discriminant functions for gaussian likelihood
| Name | Formula | Alternative form | Alternative name | |
|---|---|---|---|---|
| Formula 0 | General Formula | |||
| Formula 1 | Statistical Independent Features | |||
| Formula 1.1 | Statistical Independent Features, all equal prior probabilities | Minimum distance rule/classifier | ||
| Formula 1.2 | Statistical Independent Features, NOT all equal prior probabilities | Linear | ||
| Formula 2 | Covariance Matrix Same for all classes | |||
| Formula 2.1 | Covariance Matrix Same for all classes, Prior probability are all equals | minimum mahalanobis distance rule | ||
| Formula 2.2 | Covariance Matrix Same for all classes, Prior probability NOT are all equals | |||
| Formula 3 | Covariance Matrix is not the same for all classes |