NLP - Lecture 15 - Spelling Correction
Is a task that changes misspelled words into correct ones. It is used everywhere in phones and computers.
Autocorrect example
How autocorrect works:
- identify a misspelled word
- find strings n-edit distance away
- filter candidates
- compute word probabilities
Building the model

Find string n edit distance away:
- Given a string find all possible strings that are n edit distance away using: insert, delete, switch and replace
- Edit distance counts the number of these operations so that the n edit distance tells you how many operations away one string is from another.
Edit Distance
Edit: an operation performed on a string to change it:
- Insert (add a letter) -> to: top, two, …
- Delete (remove a letter) -> hat: ha, at, ht
- Switch (swap two adjacent letters) -> eta: eat, tea, …
- It does not include switching two letters that are not next to each other (e.g., ate)
- Replace (change one letter to another) -> jaw: jar, paw
By combining these edits, you can find a list of all possible strings that’s are n-edit away
- For autocorrect, n is typically 1-3 edits
Filter candidates:
- Many of the strings that are generated do not look like actual words
- Keep ones that are real words (correctly spelled)
- Compare it to a dictionary or vocabulary
Summarizing
- Identify a mispelled word
- Find strings n-edit distance away
- Filter candidates
- Calculate word probabilities (See lecture on language models)

Probabilities are computed starting from a corpus.
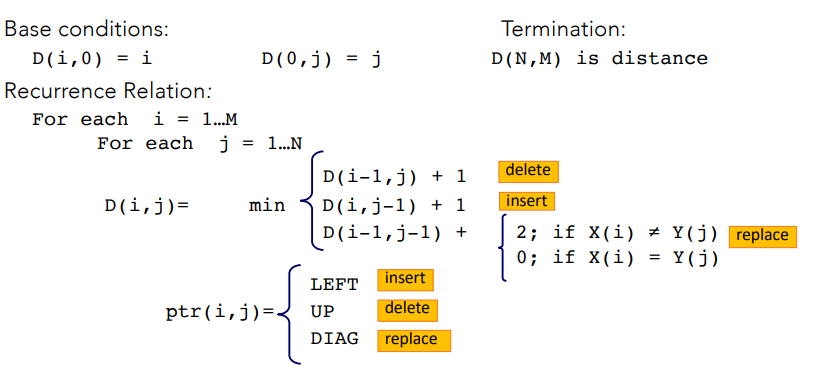
Minimum edit distance
it is a way to evaluate similarity between two strings. It’s the minimum number of edits needed to transform one string into the other.
Several applications: spelling correction, document similarity, machine translation, DNA sequencing, and more.
Example:

Note that as your strings get longer it gets much harder to calculate the minimum edit distance. We could use a brute force approach adding one edit distance at a time and enumerating all possibilities until one string changes to the other Exponential computational complexity in the size of the string!!!
Example:
- “convolutionalneuralnetworks”
- CCAAGGGGTGACTCTAGTTTAATATAACTTTAAGGGGTAGTTTAT
We need to speed up the enumeration of all possible strings and edit:
- A tabular apprach (dynamic programming)
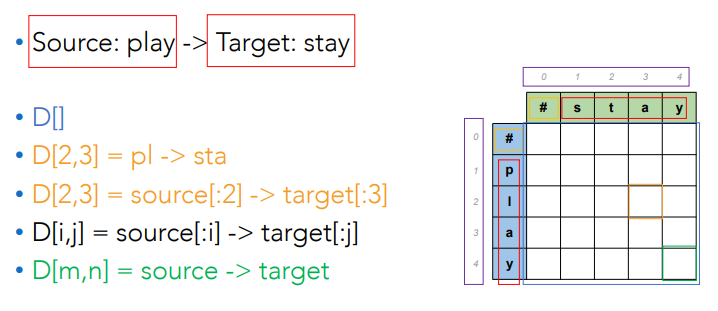
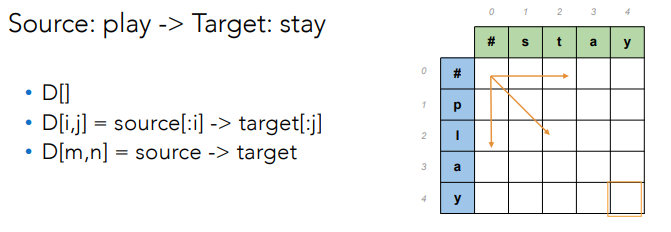
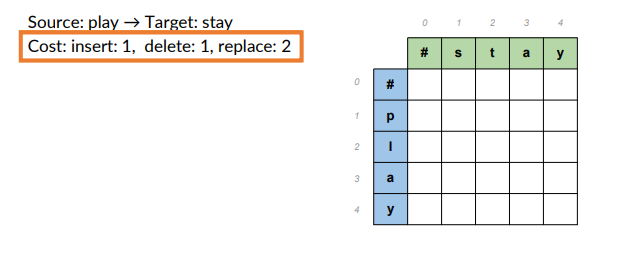
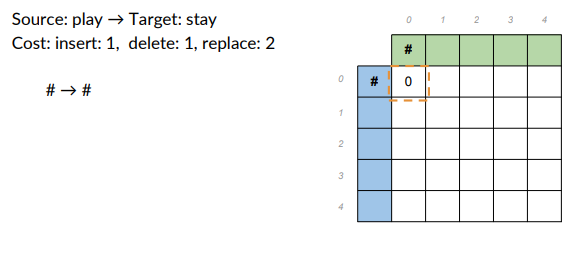
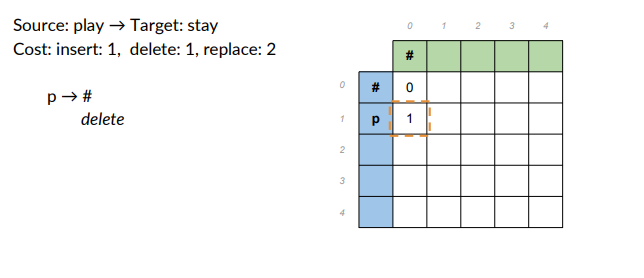
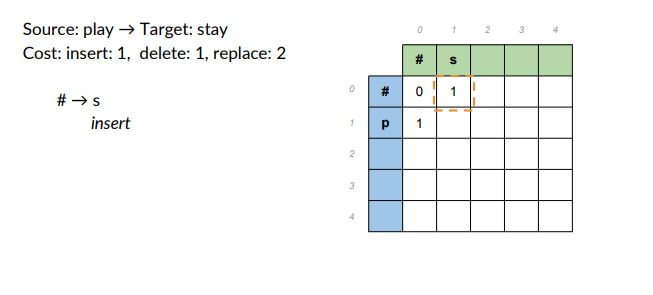
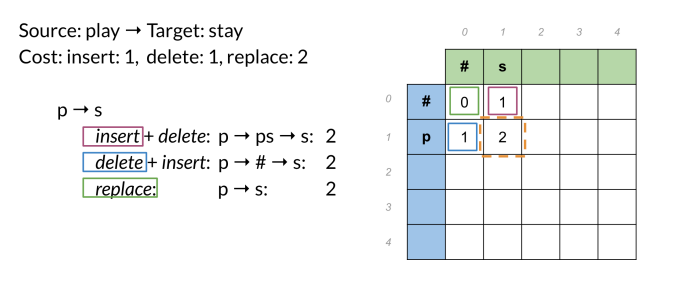

- Source: play -> target word: stay
- Cost: insert 1, delete1, replace 2.
Populate the table
Then apply the following algorithm:
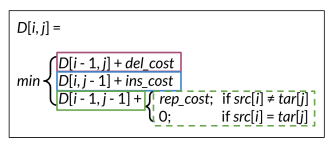 That simply chooses of the three possible paths, the least expensive one.
That simply chooses of the three possible paths, the least expensive one.
The complete algorithm is:

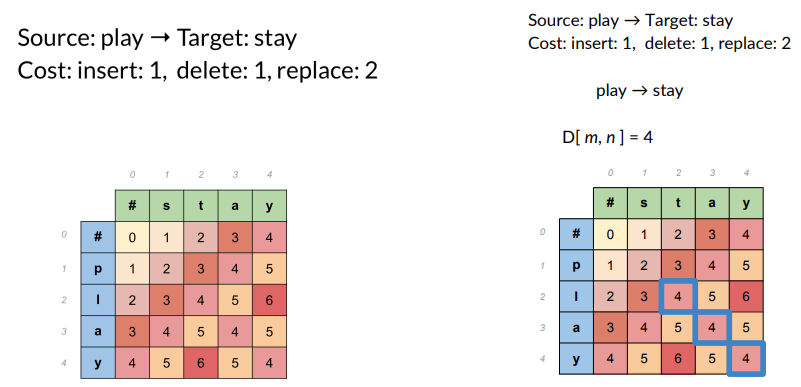
Computing alignement
Edit distance isn’t sufficient.
We often need to align each character of the two strings to each other, like:
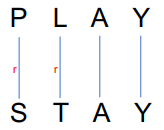
We do this by keeping a ”backtrace”. Every time we enter a cell, remember where we came from. When we reach the end, trace back the path from the upper right corner to read off the alignement.
Adding Backtrace to Minimum Edit Distance
Comutational complexity
- Time:
- Space:
- Backtrace:
The Noisy Channel Model
In real-word spelling corrector, the framework is cast into Noisy Channel Model
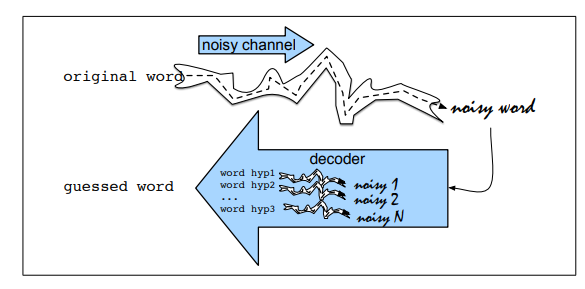
Noisy Channel Method
It uses a bayesian inference.
Observing a misspelled word
First, find the word
By using the bayes rule:
The denominator can be dropped.
The likelihood or channel model of the noisy channel is:
is the channel model is the prior probability
Modelling the Channel Likelihood
In the Noisy Channel framework,
Each edit operation introduces “noise”, similar to static or interference in a communication channel.

Estimating Probabilities from Data
The joint probability of the observed word being
These operations include:
- Insertion
- Deletion
- Substitution
- Transposition (swapping two adjacent letters)
The probabilities of these operations are estimated from a corpus of spelling errors and corrections (training data).
To compute
is the probability of a specific edit (e.g., deleting ‘r’, substituting ‘a’ to ‘e’)
We use a corpus of real spelling errors (e.g., wikipedia edit logs, online type datasets).
From this data, we count how often each edit occurs:
P(substitute
and how often deletions occurs
P(delete
and from this we can compute probabilities.
This produce confusion matrices, such as:
- Substitution matrix (rows=intended letters, columns= typed letters)
- Deletion and insertion frequency tables
Example:
- transforming
“cat” into “car” involves one substitution (‘t’ ‘r’), then =P(‘t’ ‘r’).
If the probability of replacing t with r is 0.0015, then
If multiple edits were needed, we’d multiply the probabilties of each one.
Example:
- transforming
“cat” into “car” involves one substitution (‘t’ ‘r’), then =P(‘t’ ‘r’).
Computing the likelihood
Kernighan et al. (1990) proposed an approach that learns confusion matrices by iteratively applying the spelling error correction algorithm itself:
- Start by initializing all matrix values equally — every character is equally likely to be deleted, substituted, or inserted. (This gives a uniform confusion matrix).
- Run the spelling correction algorithm on a dataset of known spelling errors.
- Use the predicted corrections to recompute the confusion matrices, then rerun the algorithm — repeating this process iteratively (similar to the Expectation-Maximization (EM) algorithm).
- Once the confusion matrices are updated, we can accurately estimate P(x|w), the probability of observing a misspelled word x given the correct word w.
Step-by Step process
Expectation Step (E-step):
- Run the spelling correction algorithm on a dataset of misspelled words
- For each typo, the algorithm predicts its most likely correction using the current confusion matrices
- This yields a set of (observed, corrected) word pairs, e.g., (“deah”, “dear”), (“frend”, “friend”)
Maximization Step (M-Step): From the predicted corrections, update the confusion matrices:
- Count how often each type of edit occurs (e.g., “a
e”, ” deleted”) - Compute relative frequencies:
- P(edit)=
- Normalize probabilities to sum to 1 for each operation type
- P(edit)=
Iteration: Repeat the process:
- Rerun the spelling correction using the updated confusion matrices
- recompute new matrices from its predictions
With each iteration, the model converges toward a stable estimate of the true edit probabilities.
Final Output
Once the model converges:
- Each type of error (like
, deleted, inserted) has an empirically probability.
These are used to compute:
This makes the Noisy Channel Model both data-driven and self-correcting.
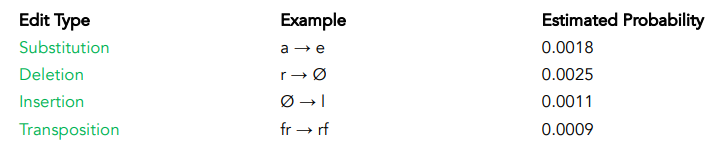
From simple to Sophisticated Spelling Correction
Basic spelling correction is done combining minimum edit distance and noisy channel mode.
Limitations:
- ignores word frequency (some corrections are more common than others)
- ignores context (whether the word fits the sentence)
- cannot detect real-word errors (e.g., “dear” vs “deer”)
Example:
- “I have to many books” Edit distance alone won’t detect that “to” should be “too”.
Modern Context-Aware Spelling Correction
Probabilistic Models
- Use the noisy channel model;
- Combines: likelihood of typing the error
and frequency or prior probability of the word .
Contextual Understanding:
- Uses n-gram or neural language models to check if the correction fits grammatically and semantically
- Example: “He went to the sea” and “He went to the see”
Learning from data:
- Systems learn from large corpora and user interactions
- adapt to frequent typos and user-specific vocabulary
- for example when you use a word in Whatsapp that isn’t in dictionary but is frequently used, after a while that word will appear as autocompletation suggestion.
- handle real words using contextual embeddings