NLP - Lecture - Language Models
Let’s consider the problem of predicting words:
- The water of Walden Pond is beautifully …
- blue
- green
- clear
A language model is a machine learning model that predicts upcoming words. More formally:
- an LM assigns a probability to each potential next word. That is, it gives a probability distribution over possible next words.
- An LM assign a probability to a whole sentence.
Two paradigms that we will follow:
- N-gram language models (this lecture)
- Large language Models (LLMs, neural models, future lectures)
Why Word Prediction?
It’s a helpful part of language tasks.
For example in grammar or spell checking:
- Their are two midterms ->
TheirThere are two midterms
Also in speech recognition, for example:
- I will be back soonish instead of I will be bassoon dish
Augmentative communication: for example they can be used to predict the most likely word from a menu for people unable to physically talk or sign.
Another motivation is that LLMs are trained to predict words, and thanks to this are able to generate text by predicting words i.e generate text from scratch. This is done by predicting the next over repeatedely
What’s (Probabilistic) Language Modeling
Goal: compute the probability of a sentence or sequence of words:
Related task: the probability of an upcoming word:
So the probability that
A model that computer either of these is called language model. It is also called the grammer, but language model or LM is standard.
Note: for now, let’s refer to these as words, but for LLMs, we use the term tokens.
Tasks to solve
- Process text corpus to N-gram langauge model
- Handle out-of-vocabulary words
- Smoothing for previously unseen N-grams
- Language model evaluation
How to Estimate these Probabilities
Could we just count and divide? For instance:
So the naive approach would be:
means count the words But there would be too many possible sentences because the human language is too creative/rich and can express the same thing in many way. So we cannot proceed in this way. It is unlikely that in a corpus the same exact sentence will appear.
That motivates the use of N-grams.
N-grams and Probabilities
N-grams are sequences of
For example, say the corpus is: I am happy because I am learning. I can consider the unigrams: so count the number of individual words: I, am, happy and so on.
A Bigram is the occurencies of two words occurring together in this case: I am, am happy, happy because, because I, I am, am learning. I can do the same with trigrams, and so on until n-grams.
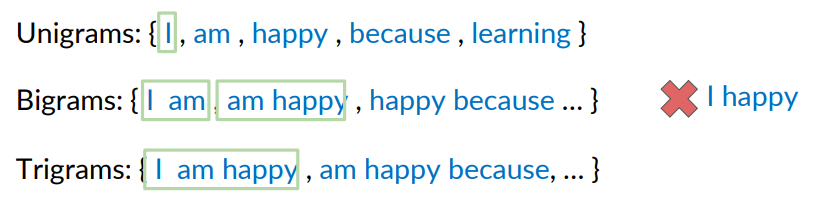
The order of words within the N-grams is important!! i.e there could never be a bigram I happy or learning I.
Note that typically punctuation like
Sequence Notation
Consider a corpus like this one: This is great … teacher drinks tea. with
- Each word is a symbol:
. - I can use the notation
to indicate the entire sequence. - I can also consider a subsequence like:

Unigram probability
We will use the Maximum Likelihood Estimate (MLE) for computing the probability.
We observe counts
Corupus: I am happy because I am learning.
Corpus size m=7,
The probability of unigrams is
means counting the occurences of
Bigram probability
We can do the same for bigram:
- the count of occurency of I am divided by the count of occurency I
For example:
- I happy could never happen.
So in general (General formula for bigram probability):
- Note this is expressed as conditional probability of appearing the word
given the word - And it is the number of times the words
appeared divided by the total count of and other words appears in the corpus. But this can be simplified to obtain the same result by counting the number of occurencies of at the denominator.
Trigram probability
We compute the conditonal probability of the last word of the trigram given the previous two words of the trigram:
Probability of a trigram is:
N-gram probability
Example: Corpus: “In every place of great resort the monster was the fashion. They sang of it in the cafes, ridiculed it in papers, and represented it on the sage. ” (Jules Verne, Twenty Thousand Leagues under the Sea)
What is the probability of word “papers” following the phrase “it in the” appearing?
Using the formula we are saying:
Answer: 1/2
Sequence Probabilities
Given a sentence, what is its probability?
- P(the teacher drinks tea)=?
Remind that (conditional probability and chain rule).
In general:
The Chain Rule for Words
Example: P(the teacher drinks tea) = P(the)P(teacher|the)P(drinks|the theacher)P(tea| the teacher drinks).
Sentence not in the Corpus
A corpus rarely contains the exact sentence we’re interested in or even its longer subsequences!
Example: The tacher drinks tea (input). Take previous example chain rule:
- P(the teacher drinks tea) = P(the)P(teacher|the)P(drinks|the theacher)P(tea| the teacher drinks).
P(tea|the teacher drinks) =
We cannot apply the chain rule. Because both the counting of the teacher drinks tea and the teacher drinks are likely zero. And applying the chain rule we got as result
Markov Assumption - Approximation of Sequence Probability
What if, instead of looking for all the words before tea, one just considers the previous word (drinks, in this case). (a fixed number of words before).
For instance: the teacher drinks tea:

And i can do the same with all other conditional probabilities in the chain, i.e. if i want to find:
P(the teacher drinks tea)
I discard the previous words and I consider only the words immediately preceed the last word. So it becomes:
P(the teacher drinks tea)
Why we are able to do so? because we are using the markov assumption: Only the last N words matter.
Note
it’s called Markov Assumption because we make the same assumption in Markov Chain, Markov Models, Hidden Markov Models (HMM) i.e the next state depends only on the state of previous one or previous sequence of states.
In general:
- Bigram
- N-gram:
Entire sequence is modeled with bigram:
The unigram probability of the first word in the sequence:
So whanever i compute the probability of a sequence i introduce the markov assumption that let me consider just the history of
Example Corpus: Mary likes dogs We apply the chain rule: P(Mary)P(likes|mary)P(dogs|likes)
We assume a bigram, so it means that when we compute the probability of a word, we compute the probability of the second word in the bigram consider the first one of the bigram.
Example/Exercise:

N-gram special cases: starting and ending of a sequence
These are two special cases of the n-gram. How do we handle the beginning and the end of a sentence?
Staring of Sentence Token for Bi-grams
In the case of the first word of a sentence, we don’t have a context for the previous word. For example consider the teacher drinks tea. We don’t have any context for the so we don’t know if it is exactly the first.
We solve this by adding a special character <s>. In this way we can write:
P(<s> the teacher drinks tea)
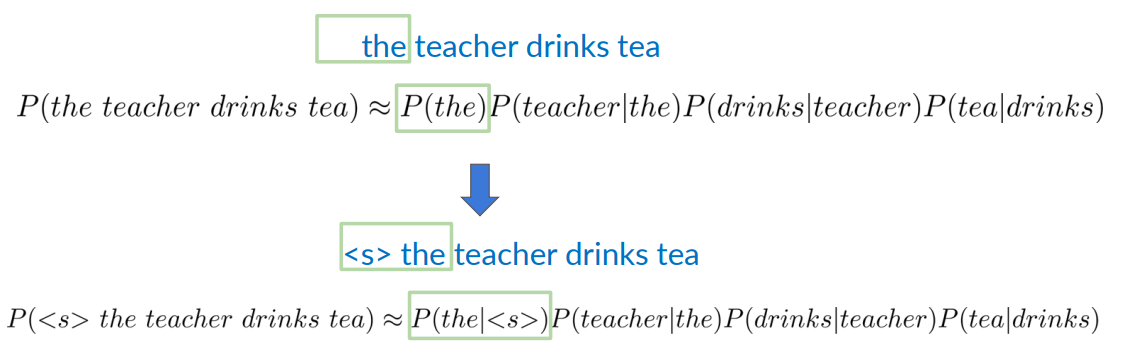
Starting of Sentence Token <s> for N-grams
In general a similar principle applies to N-grams
Consider first a trigram: we add two starting symbols for a trigram i.e

In general with an N-gram model we add
In practice in a corpus that is a set of sentence, we add this symbol to each sentence.
Preprocessing
The contraction for example of a word like ”we’re” must be replaced in preprocessing with another word. As we seen in previous lesson. Usually commas and period are considered separate words.
End of Sentence Token </s>: Motivation
There is a problem also with last word of a sentence. We have said that whenever we are computing conditional probability we apply this:
Example: if we have a corpus of two sentences:
- <s> Lyn drinks chocolate
- <s> John drinks
Now let’s consider the word drinks. If i want to consider the probability of the bigram drinks chocolate i would have to compute how many drinks chocolate appears divided by the number of times drinks appears as the first part of the bigram, that if i count this it is
But, if i’m counting the number of word drinks appearing is two. So we have a mismatch.

There’s another issue with N-gram probabilities:
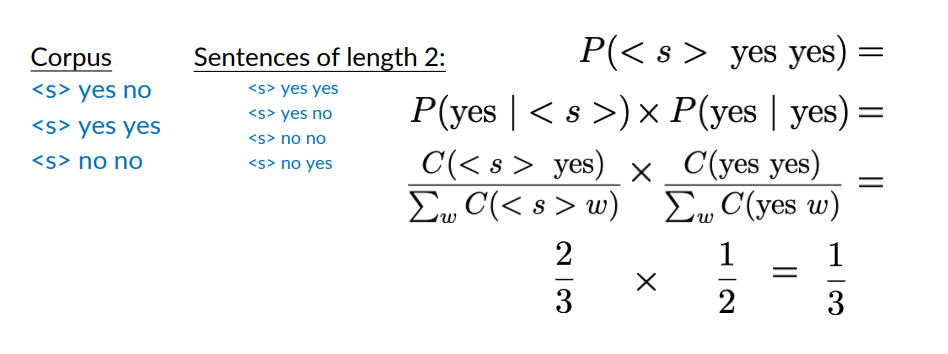
I can compute the same with other sentences and i will always get 1/3.
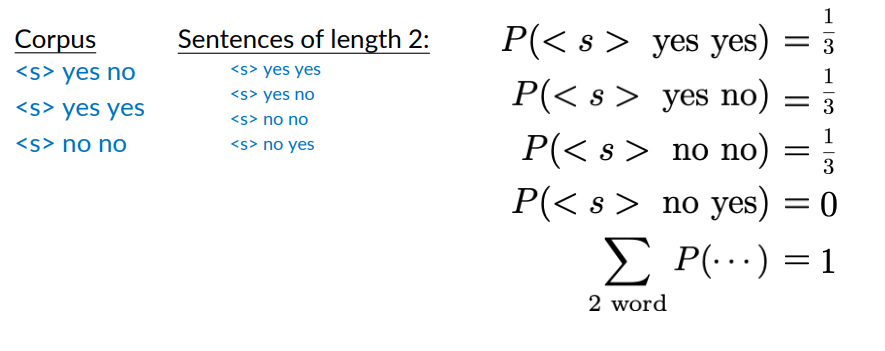 But if i sum up
But if i sum up
I get one.

What the correct result would be:
However, you really want the sum of the probabilities for all sentences of any length to be equal to 1. To compare the probabilities of two sentences of different lengths. That is, the probabilities of all 2-word sentences plus the probabilities of all 3-word sentences, plus the probabilities of all other sentences of arbitrary lengths, should be equal to 1.
This can be solved by simply adding </s> symbol to the end of the sequence. For each sequence we need to add just ONE for every sequence.
Let’s see with the bigram examples as before.

Preprocessing
The adding of symbols <s> and </s> are done in the preprocessing.
Observation
In N-gram
- Ending symbol -> just add one </s>
- Starting symbol -> Add N-1 <s> starting symbols.
Example: Bigram probability
If i want to compute the bigram probabilities for example of:
 Note that the result is 1/6 which is lower than the value of 1/3 you might expect when calculating the probability of one of the three sentences in the training corpus.
This also applies to the other two sentences in the corpus.
Note that the result is 1/6 which is lower than the value of 1/3 you might expect when calculating the probability of one of the three sentences in the training corpus.
This also applies to the other two sentences in the corpus.
Example: Four Different N-gram Models
Some automatically generated sentences from Shakespeare trigram models

The more the number of gram increases, the more the sentences resemble real english sentences.
Problems with N-gram models
N-grams can’t handle long-distance dependencies.
For example consider ”The soups that I made from that new cookbook i bought yesterday were amazingly delicious”.
N-grams don’t do well at modeling new sequences (even if they have similar meanings to sequences they’ve seen).
These problems are solved by Large language models:
- can handle much longer contexts
- because they use neural embedding spaces, they can model meaning better.
Why Study N-gram Models?
They are the “fruit fly of NLP”, a simple model that introduces important topics for large language models:
- training and test sets
- the perplexity metric
- sampling to generate sentences
- ideas like interpolation and backoff
N-grams are efficient and fast, and useful in situations where LLMs are too heavyweight. For example in spell checking it is enough to use a language model.
The N-gram Language Model
- Count matrix
- Probability matrix
- Language model
- Log probability to avoid underflow
- Generative language model
Count Matrix
Captures the numerator for all N-grams appearing in the corpus. Recall the formula:
The numerator of this formula is called count matrix.
Example: Bigram count matrix. Let the corpus be I study I learn, the rows represent the first word of the bigram and the columns represent the second word of the bigram.
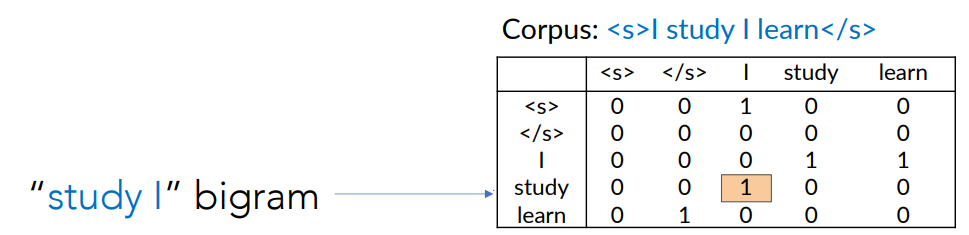
- Basically i count how many times that bigram appear in the corpus.
Doing this for every possible bigram we obtain the bigram count matrix.
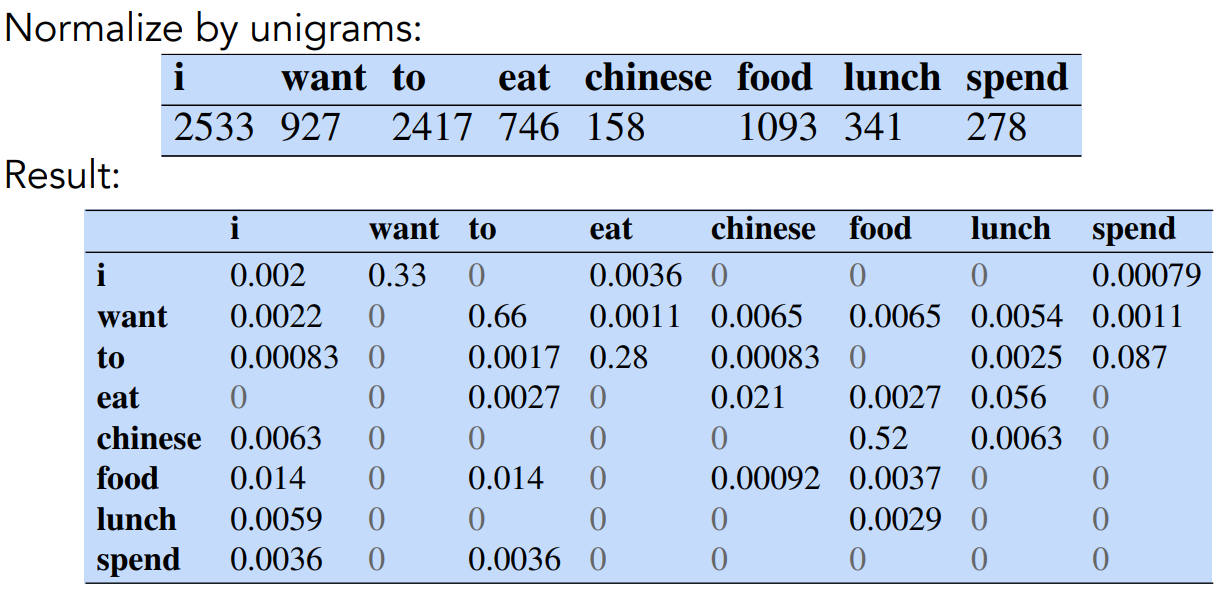
Probability Matrix
Defined as divide each cell by its row sum. Recall the formula:
We consider the denominator.
The denominator is basically the sum of the rows:
Example considering the corpus I study I learn
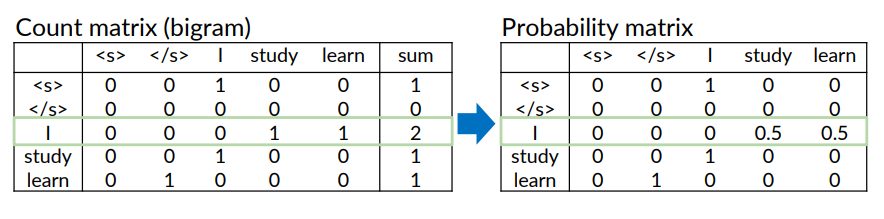 After i computed the count matrix, i divided by the corresponding probability matrix.
The result is the probability matrix.
After i computed the count matrix, i divided by the corresponding probability matrix.
The result is the probability matrix.
Language Model
Now that we have the probability matrix, we have the language model. Because we are able to compute:
- the probability of sentence
- or a next word prediction given previous words
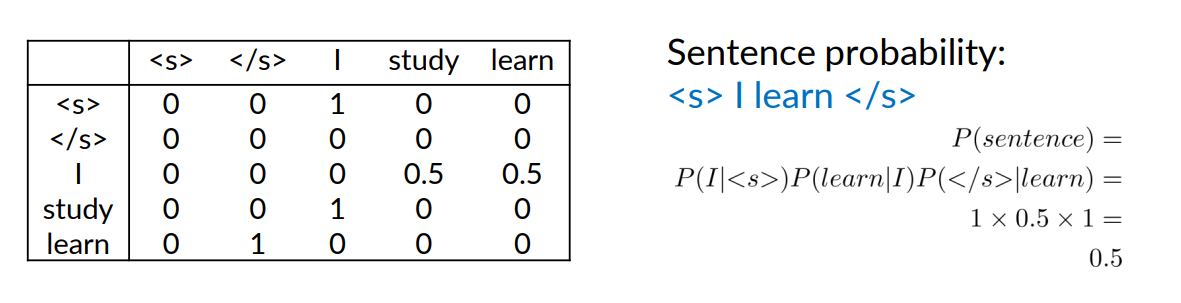
Another Example
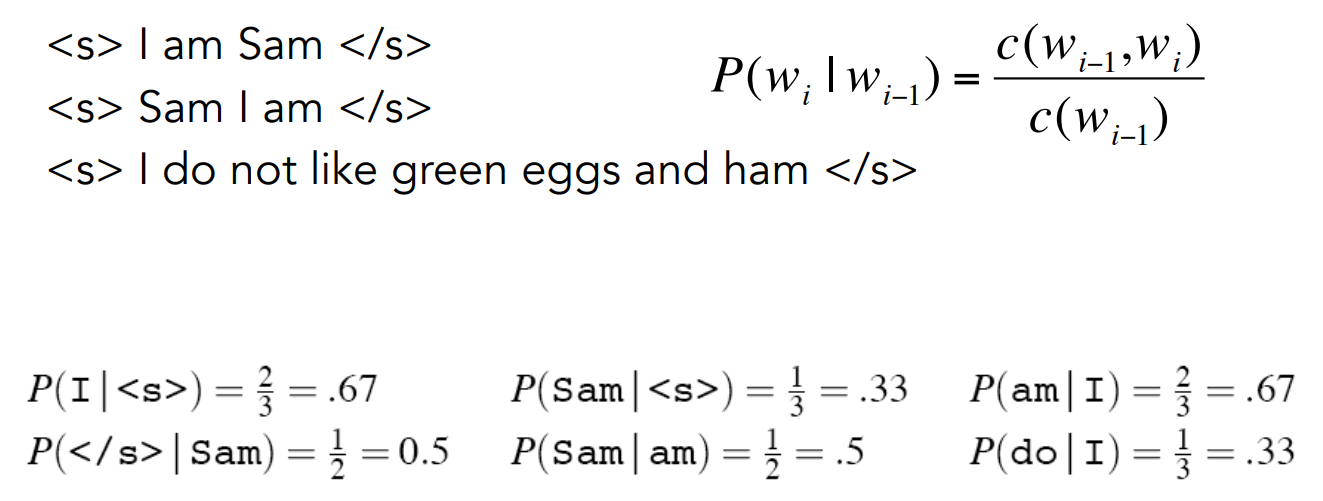
Example: Berkley Restaurant Project Sentences
- Datasets It is an old project dismissed. It was an automatic system that collect questions automatically in a berkley restaurant.
Some example sentences are:
- can you tell me about any good cantonese restaurants close by
- tell me about chez panisse
- i’m looking for a good place to eat breakfast
- when is caffe venezia open during the day
A subset of the count matrix (considering bigrams) is shown in next figure:
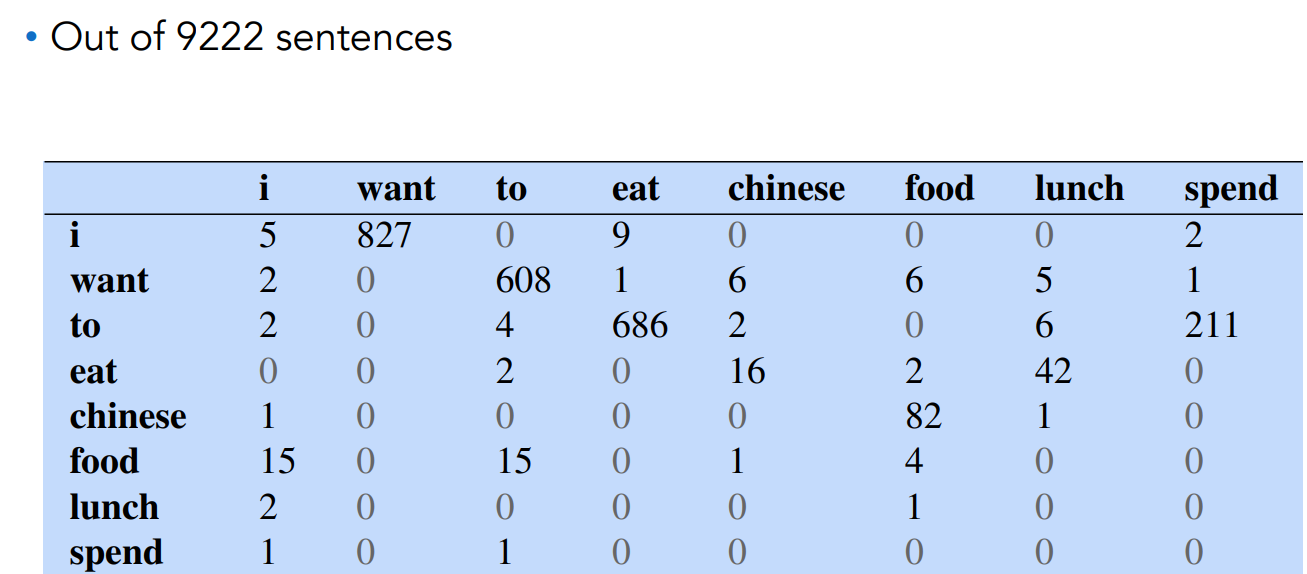
We can compute the probability:

What kind of Knowledge do N-grams represent?

Log Probability
Since all probabilities are
Use log of probabilities in probability matrix and calculations:
To convert back from log:
Generative LM: Sample Words from an LM
Unigram:
REPRESENTING AND SPEEDILY IS AN GOOD APT OR COME
CAN DIFFERENT NATURAL HERE HE THE A IN CAME THE TO
OF TO EXPERT GRAY COME TO FURNISHES THE LINE
MESSAGE HAD BE THESE.
Bigram:
THE HEAD AND IN FRONTAL ATTACK ON AN ENGLISH WRITER
THAT THE CHARACTER OF THIS POINT IS THEREFORE
ANOTHER METHOD FOR THE LETTERS THAT THE TIME OF WHO
EVER TOLD THE PROBLEM FOR AN UNEXPECTE
How Claude Shannon sampled in 1948: ”Open a book at random and select a letter at random on the page. This letter is recorded. The book is then opened to another page, and one reads until this letter is encountered. The succeeding letter is then recorded. Turning to another page, this second letter is searched for and the succeeding letter recorded, etc.”
Sampling a Word from a distribution
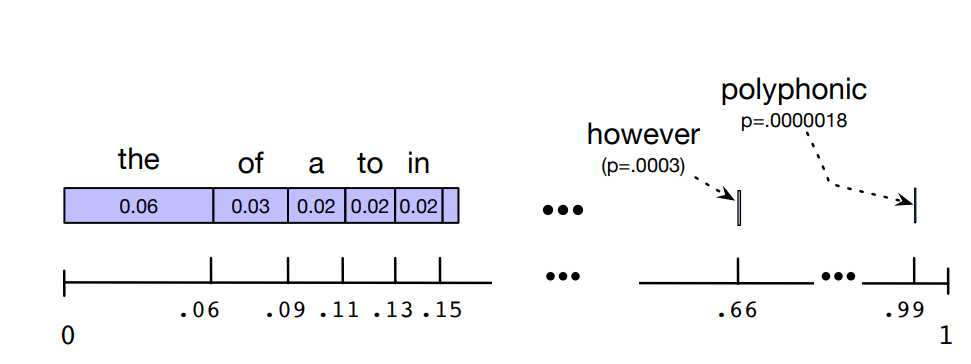
- Generate a random number between 0 and 1
- See which interval it appartain the number. The interval is proportional to the frequence of the word in the corpus.
- The most probable words have a larger interval and a better chance to be selected and generated.
As said before: a language model, when we are trying to generate sequence, should ideally generate sentences that have larger probabilities. Whereas instead sentence that randomly occur should have low probability. That’s why we choose this sampling method.
Visualizing Bigrams the Shannon Way

Generative Language Model
Application of language models in text generation from scratch or using a small hint

Algorithm:
- Choose among all bigrams, starting with <s>, based on the bigram probability
- Choose a new bigram at random from the bigrams beginning with the previously chosen word
- Add the choosen bigram to the sentence
- Continue until the end sentence token, </s> is chosen
(1) means that the bigrams with higher values in the probability matrix are more likely to be chosen. (4) the end sentence token is added when we choose a random diagram that starts with the previous word and ends with the closing sequence character
Note: there are other sampling methods
We will see them when we will talk about neural language models. Many of them avoid generating words from the very unlikely tail of the distribution.
One of the problem of this sampling method is that we generate only sentences already present in the text.
We’ll discuss when we get to neural LM decoding:
- Temperature sampling
- Top-k sampling
- Top-p sampling
How to Evalutate N-gram models
We have Extrinsic and Intrinsic evaluation
Extrinsic Evaluation
To compare two models
- Put each model in real task, for example: Machine Translation, speech recognition, etc.
- Run the task, get a score for A and for B, e.g., how many words translated or transcribed correctly
- Compare accuracy for A and B
Intrinsic Evaluation
Extrinsic evaluation not always possible:
- Expensive, time-consuming;
- Doesn’t always generalize to other applications.
The intrinsic evaluation is done using perplexity. This metric:
- Directly measures language model performance at predicting words
- Doesn’t necessarily correspond with real application performance
- But gives us a single general metric for language models
- Useful for large language models (LLMs) as well as n-grams
Model Evaluation: [[../../../AI & Machine Learning/Machine Learning/Model Evaluation/Machine Learning Evaluation Metrics#Testing and Validating in Machine Learning|Machine Learning Evaluation Metrics|Training and Test Set]]
We train the parameters of our model on a training set
We test the model’s performance on data we haven’t seen
- A test set is an unseen dataset, different from the training set.
- Intuition: We want to measure generalization to unseen data
- An evaluation metric (like perplexity) tells us how well our model does on the test set.
Some tips on choosing the datasets:
- If we’re building the LM for a specific task, the test set should reflect the task language we want to use the model to.
- If we’re building a general-purpose model, we’ll need lots of different kinds of training data and we DON’T want the training set or the test set to be just from one domain or author or language.
Dev (or Validation) Sets: If we test on the test set many times we might implicitly tune to its characteristics. Noticing which changes make the model better.
That means we need a third dataset:
- A development test set or, devset
- We test our LM on the devset until the very end
- And then test our LM on the test set once
Language Model Evaluation

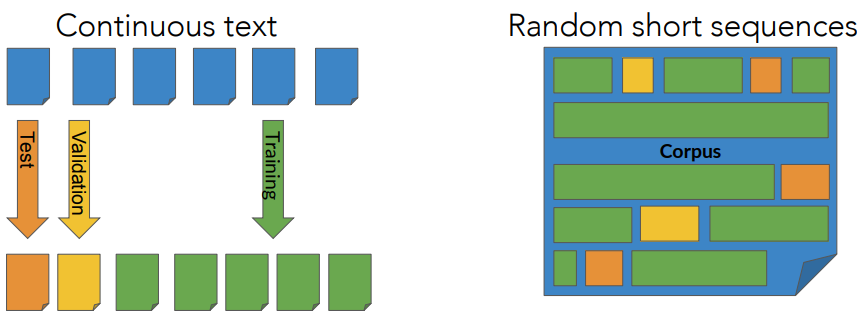
Test data: Split Method
In NLP there are two main methods for splitting:
- split the corpus by choosing longer continuous segments like Wikipedia articles.
- randomly choose sort sequences of words such as those in sentences
Perplexity
Intuition of Perplexity: How good is our LM?
Intuition: A good LM prefers “real” sentences
- Assign a higher probability to “real” or “frequently observed” sentences
- Assigns a lower probability to “word salad” or “rarely observed” sentences
Intuition of Perplexity: How good is our LM?

Unigrams are terrible because they lack the context, a word is more probable to appear in a word, given a context rather than in another context. Unigram don’t have any context.
Intuition of Perplexity: The LM that best predicts on test set
We said: a good LM assigns a higher probability to the next word that actually occurs.
Let’s generalize to all the words! The best LM assigns a high probability to the entire test set.
When comparing two LMs, A and B:
- We compute
and - The better LM will give a higher probability to (corresponding to being ”less surprised” by) the test set than the other LM.
Intuition of Perplexity: Perplexity instead of raw probability
Probability depends on size of test set. Probability gets smaller the longer the text. Better: a metric that is per-word, normalized by length.
Perplexity is the inverse probability of the test set, normalized by the number of words
- Probability range is
, while perplexity range is - Minimizing perplexity is the same as maximizing probability.
The inverse comes from the original definition of perplexity from cross-entropy rate ininformation theory.
Intuition of Perplexity: N-Grams
Consider the formula:
Since we apply the chain rule, we make products and obtrain:
For example, for bigram we consider:
Weighted Average Branching Factor
Another way to interpret perplexity is as the weighted average branching factor of a language.
- Branching factor: number of possible next words that can follow any word.
Example: Deterministic Language L={red, blue, green}. The branching factor is 3 (any word can be followed by red, blue, green).
Now assume that LM
Given a test set
But now suppose that red was very likely in the training set, such that for LM
- P(red)=.8, P(green)=.1 and P(blue)=.1
We would expect that the probability to be higher, hence the perplexity to be smaller:
Notice that 1.89 is smaller than 3 that is the case when there is equal probability between each words. The “weight” comes from the probability f each word In the case where the probability is the same.
Holding Test Set Constant, Lower Perplexity lead to better LM
Training 38 million words, test 1.5 million words, WSJ

Log perplexity
For ease of computation, the log perplexity is often used
becomes:
Example: Wall Street Journal Corpus
Training 38 million words, test 1.5 million words. Examples: Perplexity Unigram: 962 Bigram: 170 Trigram: 109.

Sparsity
How the size of N impacts on the LM
To better fix the perplexity changes in unigram, bigram, and trigram LM:
- Recall that
in an -gram language model defines the context used in each conditional probability
Consider the following sentences:
- Gorillas always like to groom friends;
- The computer that’s on the 3rd floor of our office building crashed.
The bold words depend on each other.
- If
is too small the context cannot be captured, and those sentences get a very low probability, while sentences that fail basic linguistic rules get the higher probabilities. - If
is too big, however, it is hard getting good estimates of the parameters from our corpus, because of data sparsity.
Generalizing vs overfitting the Training Set

The N-gram model is dependent on the training corpus.
Considering the Shakespeare corpus, we have:
Out of
The sparsity is even worse for
- Possible 4-grams =
- Only a very small fraction of those possible 4-grams actually occur
- Many 4-grams have zero count (i.e., never observed)
Once you reach a specific 3-gram, e.g., “It cannot be …”, there are only 6 possible continuations in the empirical model (“but, I, that, thus, this, .”), not 29,000.
The Wall Street Journal is not Shakespeare
To get an idea of the dependence on a training set, let’s look at LMs trained on a completely different corpus:
 Statistical models are useless as predictors when the training sets and the test sets are as different as Shakespeare and WSJ.
Statistical models are useless as predictors when the training sets and the test sets are as different as Shakespeare and WSJ.
Choosing Training Data
If task-specific, use a training corpus that has a similar genre to your task
- If legal or medical, need lots of special-purpose documents
Make sure to cover different kinds of dialects and speaker/authors
- Example: African-American Vernacular English (AAVE)
- One of many varieties that can be used by African Americans and others
- Can include the auxiliary verb finna that marks immediate future tense:
- “My phone finna die”
The Perils of Overfitting
N-grams only work well for word prediction if the test corpus looks like the training corpus.
But even when we try to pick a good training corpus, the test set will surprise us! We need to train robust models that generalize.
Our models may still be subject to the problem of sparsity: things that don’t ever occur in the training set, but occur in the test set.
One kind of generalization: zeros. Our models may still be subject to the problem of sparsity; ”that things that don’t ever occur in the training bu they occur in the test set.”
Zeros - Solving the Sparsity Problem

Zero Probability Bigrams
Zero Probability Bigrams are bigrams where we cannot compute complexity because we cannot divide by 0.
Bigrams with zero probability hurts performance for texts where those words appear, i.e assigning 0 probability to the test set.
The problem of Sparsity
Maximum likelihood estimation has a problem: sparsity.
Our finite training corpus won’t have some perfectly fine sequences. Perhaps it has “ruby” and “slippers”, but happens not to have “ruby slippers”.
Sparisty can take many forms
Verbs have direct objects; those can be sparse too!
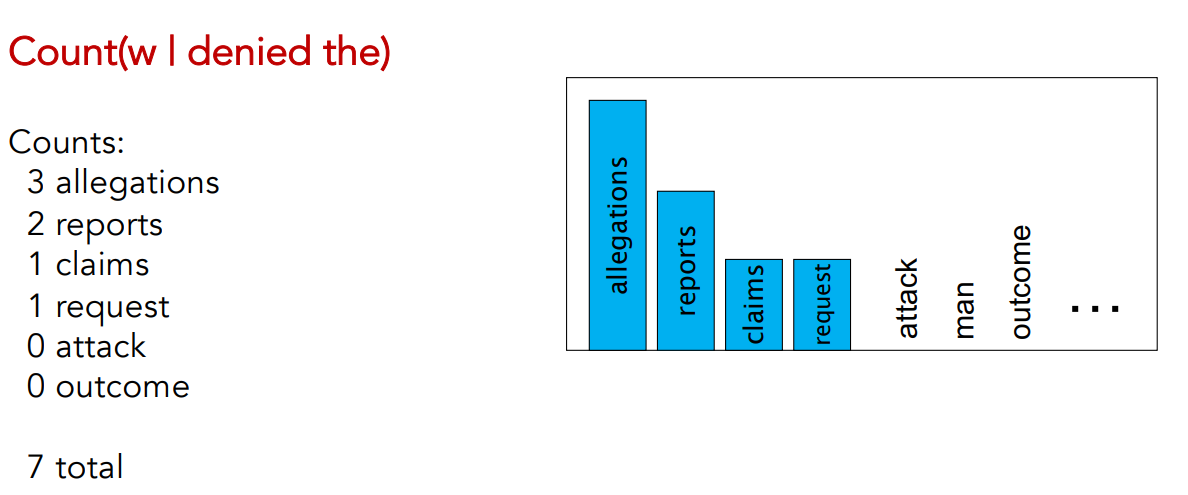
- Count(w | denied the) means we want to count any words
with denied the, so it’s a trigram. - We notice for example that in the corpus we have 3 occurencies of allegations and 0 occurencies of outcome.
The intuition of Smoothing
SInce we have this umbalanced distribution of words:
We can modify the distribution such that, given a proportion of values of distribution or frequents words and assign that fraction of values to the words that do not occur.
Let’s lower the frequencies of some frequent words in order to move the total probability mass in order to be able to compute some probabilities values also for values that do not occur.
“spalmare la probabilità su tutte le occurencies”.
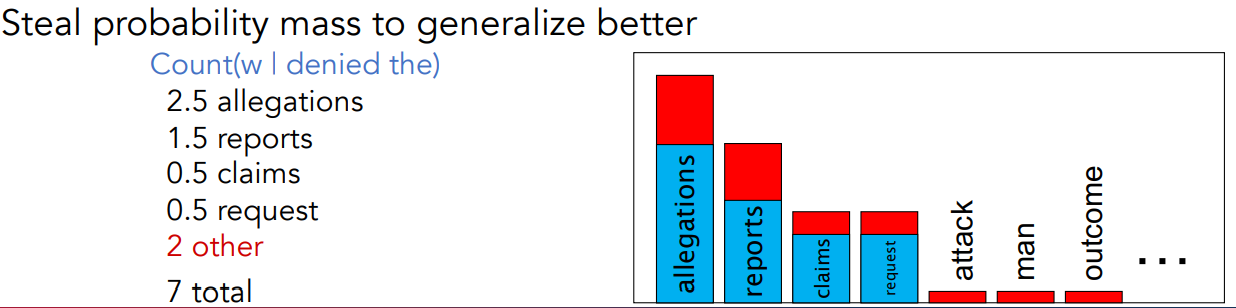 In this way, whenever i get some text sentences with those words in the N-gram i’m able to compute the probability.
In this way, whenever i get some text sentences with those words in the N-gram i’m able to compute the probability.
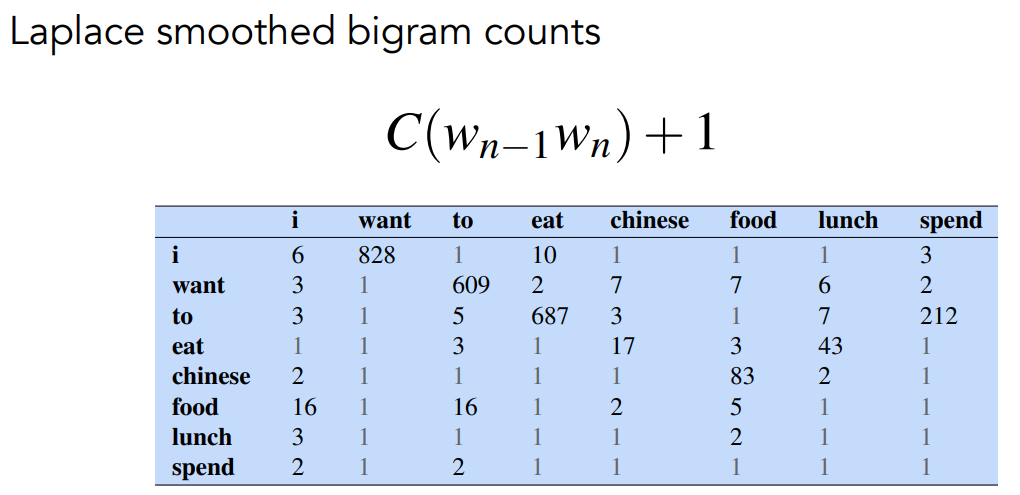
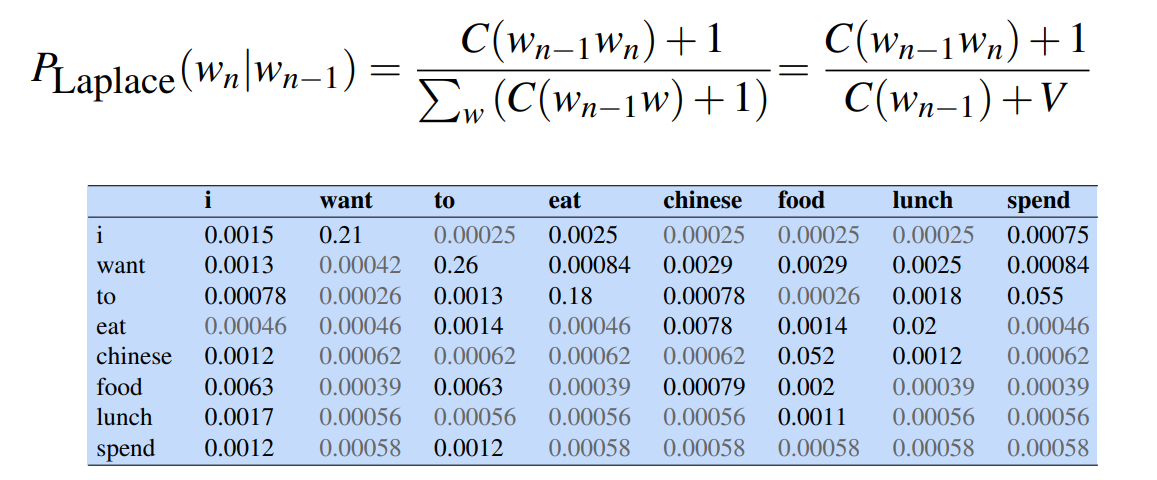
Add-one Estimation
Also called Laplacian smoothing. We pretend we saw each word one more time than we did. So we just add one to all the counts!
MLE estimate:
Add-1 estimate:
Example: Berkley Restaurant Corpus
Effect of Smoothing: Reconstitued Counts
After smoothing, instead of just storing probabilities, we can compute an “adjusted count”
where
Intuition
- C* is the count that would produce the smoothed probability if we treated it as a raw count
- It enables comparing the original count C and adjusted count C*
Reconstituted Counts 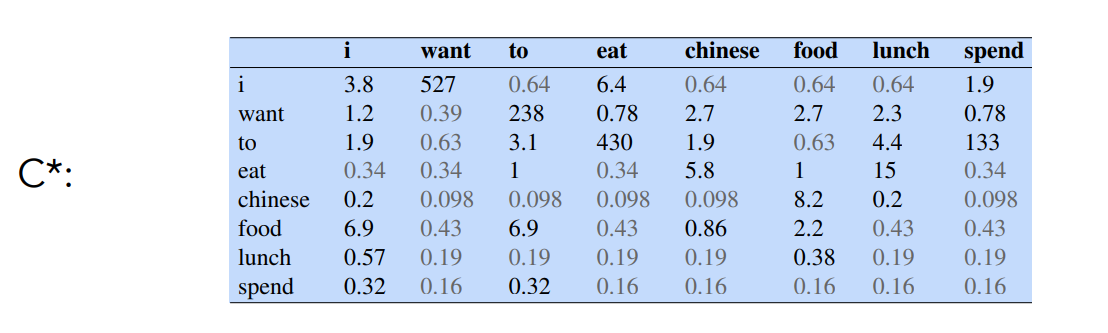
Comparing Raw and Smoothed Bigram Counts
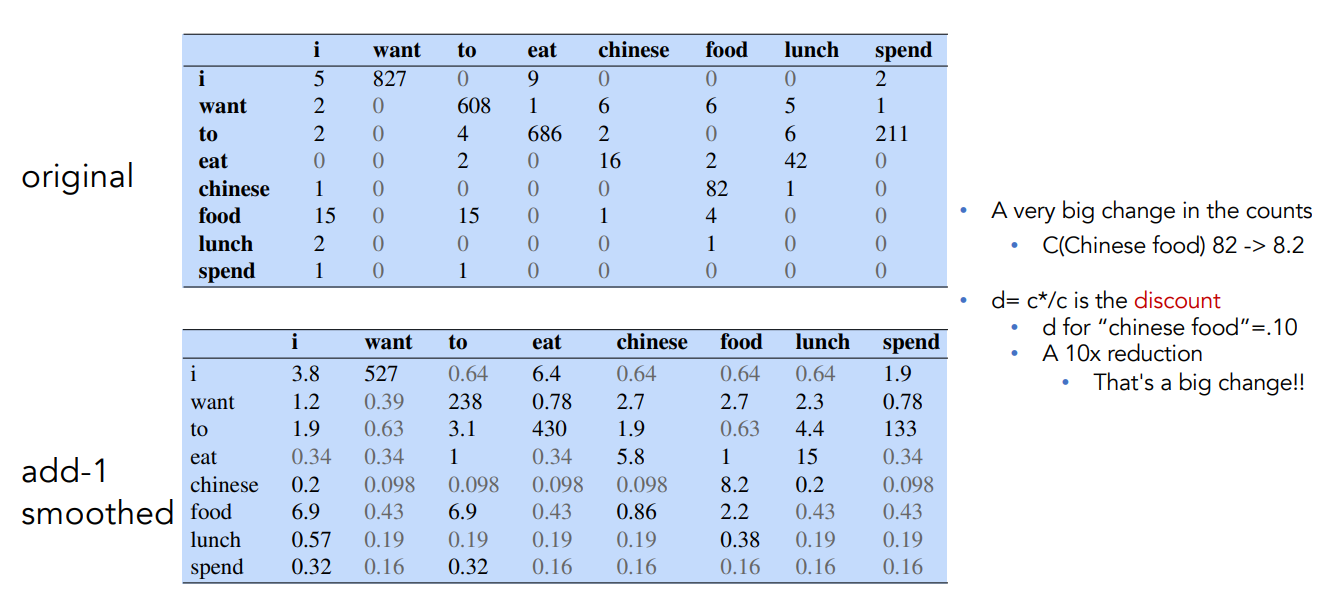
The change of Chineese food goes from 82 to 8.2, and it’s a big important change, a 10x reduction.
Laplace Smoothing Drawbacks
In practice Laplace smoothing could introduce other problems so instead interpolation or backoff are used.
But add-1 is used to smooth other NLP models. (for example? text classification)
Alternatively we can use add-k where
The definition of the add-k is:
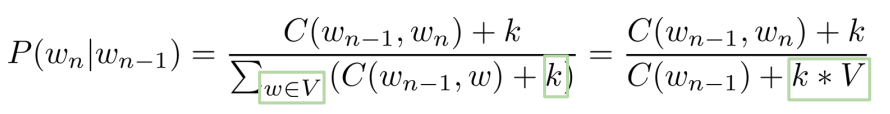 we simply addedd a
we simply addedd a
Backoff and Interpolation
Sometimes it helps to use a simpler model. When computing the conditional probability for N-grams i can consider less context for contexts you know less about. If i’m not able to find an N-gram, i refer to the N-1-gram. If i can’t find the N-1-gram i move to N-2-gram and so on.
Backoff
Suppose we have a trigram
Another approach is Interpolation. Consider trigram for example. Let’s combine the probability of unigram, twograms and trigrams in order to compute an estimation of the probability of the bigram.
In general interpolation works better.
Linear Interpolation
Use the linear interpolation of all orders of N-grams. You would always combine the weighted probability of the N-gram, N-1-gram down to 1-grams.
IF we consider a trigram for example:
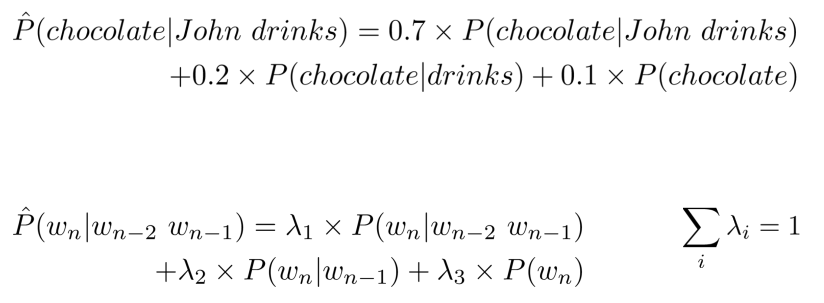
- In the first example, 0.7, 0.2 and 0.1 are the weights, and the sum must be one.
- Because we weight the different contribution of probabilities.
- The second formula is the general one
How to set weights for interpolation?
We consider a validation corpus (backlink).

Choose
I can use for example an Expectation and Maximization algorithm for this.
Backoff
When an n-gram (e.g., a trigram) has zero counts, we “back off” to a lower-order ngram (bigram or unigram) to estimate the probability.
Instead of assigning 0 probability to unseen sequences, we rely on less specific, more general statistics.
 A complication is the need to discount the higher-order ngram so probabilities don’t sum higher than 1 (e.g., Katz backoff).
A complication is the need to discount the higher-order ngram so probabilities don’t sum higher than 1 (e.g., Katz backoff).
Stupid Backoff
It avoids what the Katz backoff does i.e assigning weights such that at the end we get probabilities.

instead of to underline that we don’t get probabilities. - If it is non-zero, i consider that count, because in that case i consider an n-gram present in the training set
- In the other case i.e when the n-gram is not present, i multiply it by the constant 0.4.
- 0.4 an empirical value that has been shown to work well in many situations
This is done in order to overwhelm the higher order probabilities and to avoid to put too much on the low order probability.
Let’s see an example:
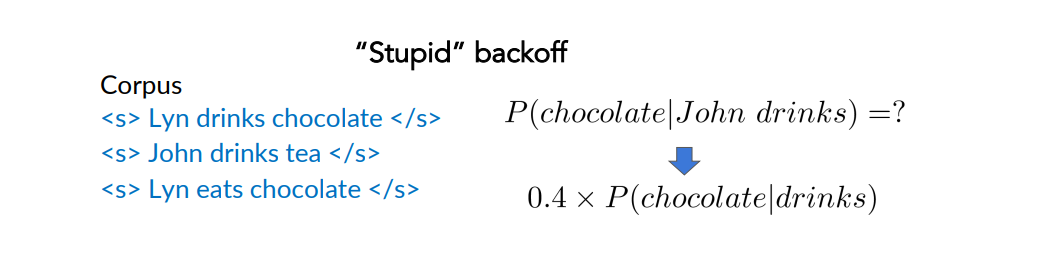
Summary - What to do if you have never seen an n-gram in training
- Smoothing: Pretend you saw every n-gram one (or k < 1) times more than you did;
- Backoff: If you haven’t seen the trigram, use the (weighted) bigram probability instead and so on. In general we want to avoid stupid backoff unless it is a small size corpora
- Interpolation: (weighted) mix of trigram, bigram, unigram. The best, also used to combine multiple LLMs.
Out of Vocabulary Words
When using LM in real tasks, it happens to deal with words that did not occur in the training set.
Need to handle words missing from a training corpus, i.e unknowns words.
We need to:
- Update corpus with <UNK>
- Choose a vocabulary.
Closed vs Open vocabulary
- Closed vocabulary: in some tasks, one will encounter and generate only words from a fixed set of words. This fixed set of words is the closed vocabulary. The test set can only contain words from that lexicon (no unknown words)
- Open vocabulary: An open vocabulary contains potentially unknown words i.e never seen in the training set.
Usually for an Out of vocabolary word (OOV) we add a special tag <UNK> in corpus and in input.
Unknown special tag in corpus
Two ways to train the LM for unknown words.
The first one is to turn the problem back into a closed vocabulary one by choosing a fixed vocabulary in advance. The steps are:
- Choose a vocabulary (word list) that is fixed in advance
- Convert in the training set any OOV to the token <UNK>
- Estimate the probability for <UNK> from its count like any other regular word in the training set.
The second approach is to create a vocabulary implicitly (we don’t have a prior vocabulary in advance), i.e replace by <UNK> the words based on their frequency.
Example
Training corpus where (we decided) a vocabulary word appears at least twice (min frequency = 2)
Replace all words with frequency less than 2 with <UNK>
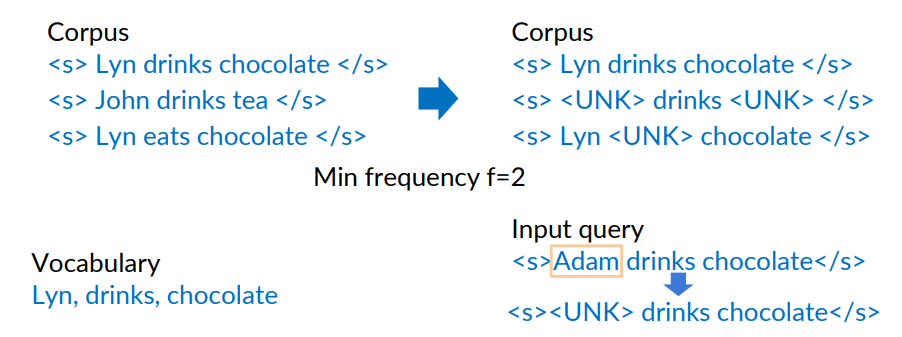
Any words in the input query that are outside the vocabulary are also replaced with <UNK>.
How to create a vocabulary
Criteria:
- Set a min word frequency
- Set max
in advance, include words by frequency (from the higher) - Use <UNK> sparingly because otherwise the model will generate a sequence of <UNK> with a high probability
- Perplexity: only compare LMs with the same
Another example
<s> I am happy I am learning </s> <s> I am happy I can study </s>
The vocabulary would look like: V=(I,am,happy)
Important: Yet on OOV
Although entire words may not appear in the training data, NLP models typically operate on subword tokens rather than full words.
Using subword tokenization methods such as Byte Pair Encoding (BPE), any word can be broken down into a sequence of familiar subwords or, if needed, into tokens representing individual characters.
Thus, while we often refer to “words” for simplicity, the LM’s vocabulary actually consists of tokens, not words. This guarantees that the test set never includes unseen tokens.
If you think in terms of tokens and go all the way down to characters, then the “unknown” token isn’t needed because letters are always the same. With syllables, you might come across some that don’t exist, but it’s already less likely than with full words. In modern approaches, word embeddings are used, where words are represented as arrays of numbers.