NLP - Lecture 13 - Neural Network for Text Classification and Language Modelling
Let’s consider 2 (simplified) sample tasks:
- Text classification
- Language modeling
State of the art systems use more powerful neural classifiers like BERT classifiers (transformers), but simple models will introduce some important ideas.
Feedforward nets for Simple Classification
We can apply the same idea used in logistic regression (see previous lesson):
- the input layer consists of hand-crafted features, and the output layer predicts either 0 or 1.
However, unlike standard logistic Regression, this model includes additional hidden layers and uses nonlinear activation functions.
These nonlinearities allow the network to capture complex, nonlinear relationships in the data that logistic regression alone cannot model.
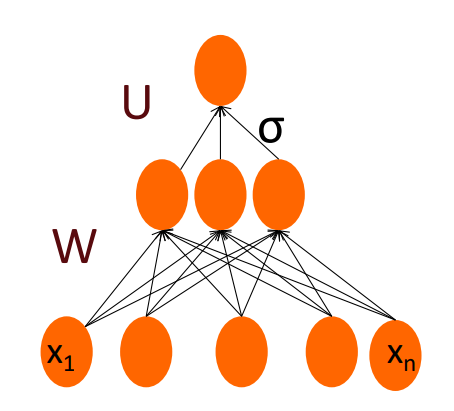
We have the same features and a layer of weights denoted as
Sentiment Features

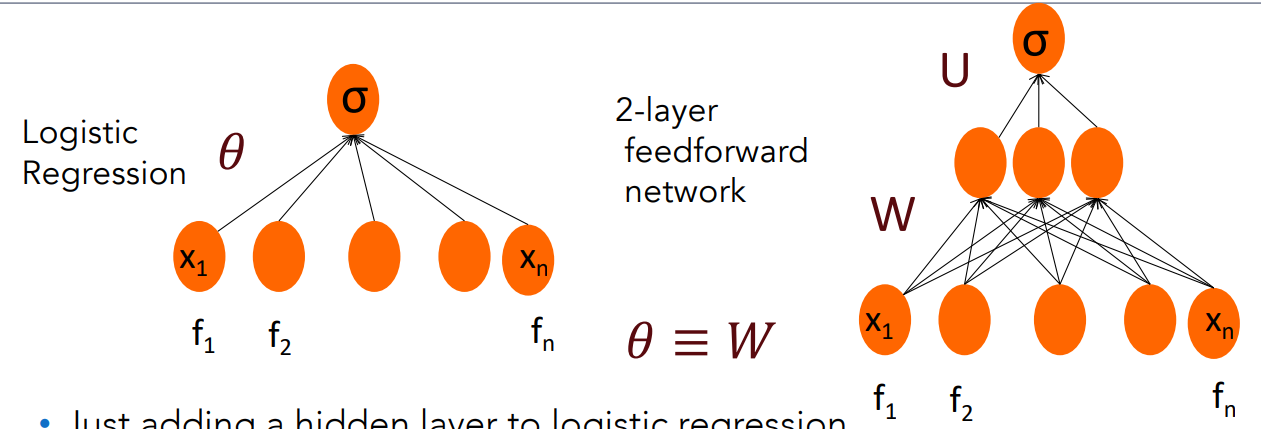
Just adding a hidden layer to logistic regression
- allows the network to use non-linear interactions between features i.e capturing non-linearity in data.
- which may (or may not) improve performance.
Multiclass Output:
If you have more than two output class you can use more output units (one for each class) and use a softmax layer:
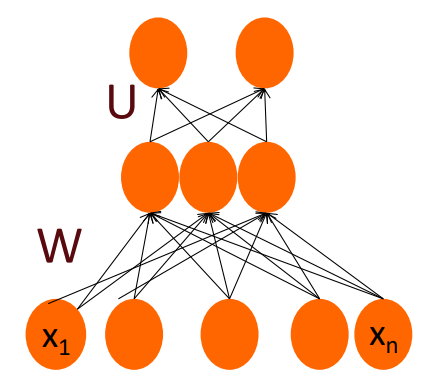
The output layer:
could have one or two nodes (one each for positive and negative) or 3nodes (positive negative, enutral)
We have:
estimated probability positive sentiment, negative and neutral
Equations for NN with hand-designed features:
Hand-designed features
Means that features i.e the important aspect of data are manually choosen.
MLP for Sentiment with Hand Features
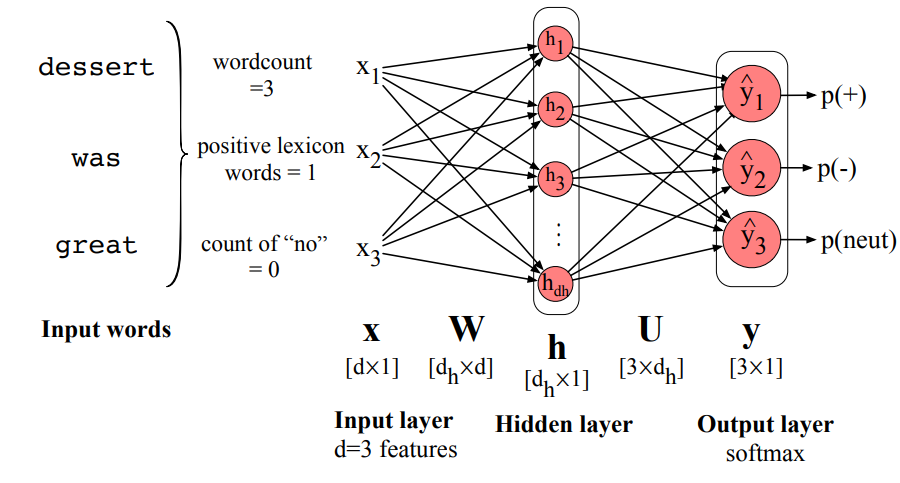
- Features are extracted from the input words and used as input.
- In this simple example: wordcount, positive lexicon words and count of “no” are the hand-craften features.
Vectoring for parallelizing inference
So we would like to efficiently classify the whole test set of
So we vectorize i.e pack all the input features into
- Each row
of is a row vector with all the features for example - Feature dimensionality is
, is
Slight changes to the equations:
is of shape is of shape - We’ll need to do some reordering and transposing
- Bias vector
that used to be is now
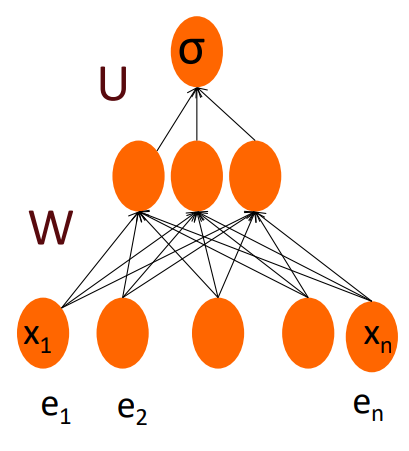
Embedding as Input to Neural Classifiers
Representation Learning: The real power of deep learning comes from the ability to learn features from the data. Instead of using hand-built human-engineered features for classification. Use learned representations like embeddings!
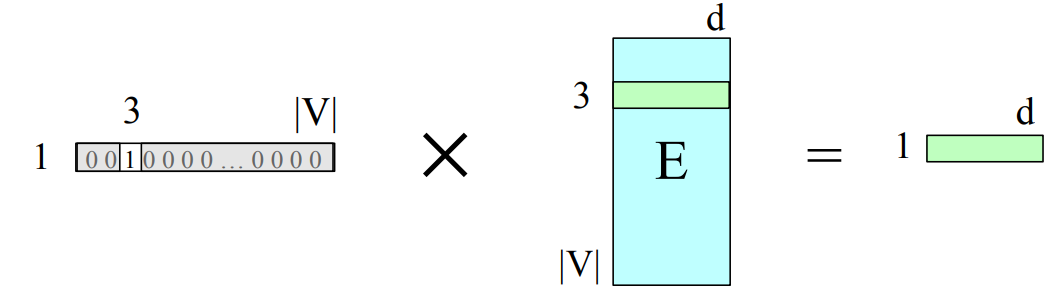
Embedding Matrix E
An embedding is a vector of dimension
Embedding matrices are central to NLP; they represent input text in LLMs and NLP tools.
Text Classification from embeddings
Given tokenized input: dessert was great
Select the embedding vectors from
Option 1:
- Convert BPE tokens into vocabulary indices
- use indexes to select the corresponding rows from
: row 3, row 4000, row 10532.
Option 2:
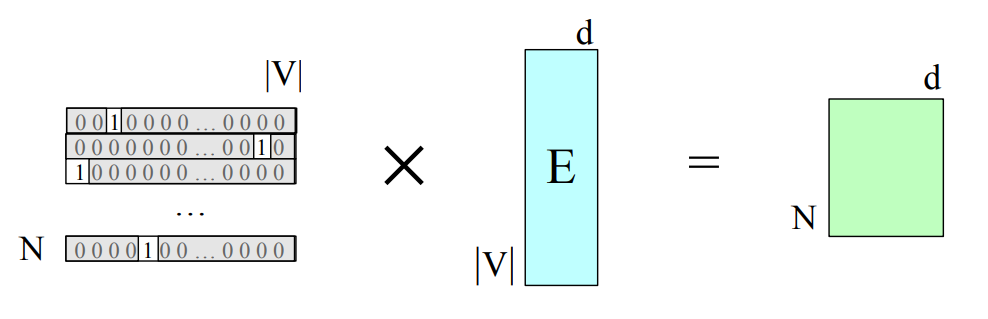
- Treat each input word as a one-hot vector i.e if dessert is index 3 so the corresponding one hot vector is in the third position 1 and all other entries are 0
- Given the one-hot representation in order to get the corresponding embedding i can multiply the one-hot vector for the embedding matrix, and now since we have 1 just in the third position we get by multiplication just the third row so the word embeddings for third word
Collecting embeddings from
So i get collectively a number of word embeddings for my input sample.
Text comes in different lengths
The problem is the following: the architecture is fixed, if my network works with
But text comes in different lengths i.e a tweet of 3 words but also a tweet of 12 words.
In which way i can represent properly the input? i have two options:
- Concatenate all the inputs into one long vector of shape
i.e the input is length of the longest review. If shorter, then pad with zero embeddings. Truncate if you get longer reviews at test time. - Pool the inputs into a single short
vector - A single sentence embedding (the same dimensionality as a word) to represent all the words
- Less info, but very efficient and fast
Pooling
Intuition: the exact position not so important for sentiment analysis.
We’ll do some sort of averaging of all the vectors (mean pooling):
The mean is applied to each
The other equations remains the same:
is the matrix of embeddings, it is shared across all words (i.e inputs), this is a characteristic of CNNs
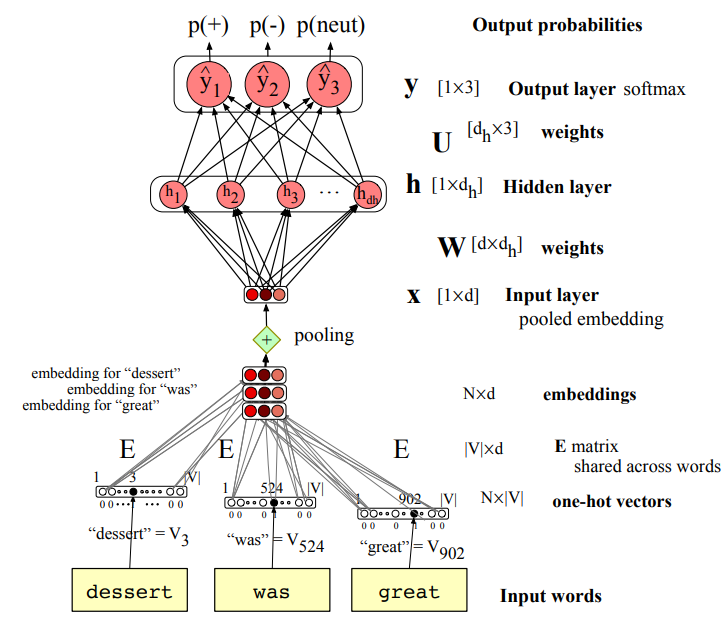
We begin with the input words “dessert,” “was,” and “great.” Each word is first converted into its one-hot vector, and from these we obtain their corresponding pre-trained embeddings (for example, from Word2Vec).
Because we are performing sentiment analysis, we combine these embeddings using a pooling operation (such as min or max pooling).
After pooling, we obtain a single input vector of dimension D, which represents the entire sentence — a compact summary of its meaning derived from the individual word embeddings.
Neural Network for Language Modeling
Neural Language Models
Language Modeling: calculating the probability of the next word in a sequence given some history:
- we’ve seen N-gram -based LMs, but neural networks LMs far outperform n-gram language models
State-of-the-art neural LMs are based on more powerful neural network technology like Transformers. But also a simple feedforward LMs can do almost as well!
Task: use a NN to predict the next word
Let’s pretend to use a 4-gram LM, the NN should estimate
Emeddings allow neural LMs to generalize better to unseen data.
Why Neural LLMs work better than N-gram LMs
Training data:
- We’ve seen: I have to make sure that the cat gets fed.
- Never seen: dog gets fed
Test data:
- I forgot to make sure that the dog gets ___
N-gram LM can’t predict fed! Neural LM can use the similarity of cat and dog embeddings to generalize and predict fed after dog.
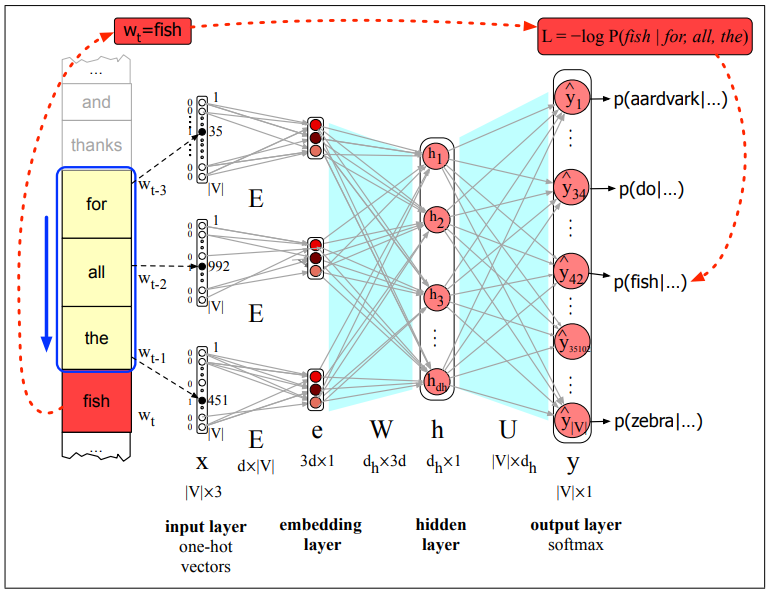
Decoding the Neural LM
Each of the
The feedforward neural language model has a moving window that can see N-1 words in the past.
Since N=4, 3 words
The embedding weight matrix
Multiplying
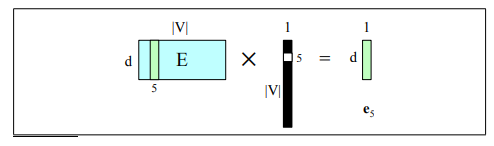
Figure:
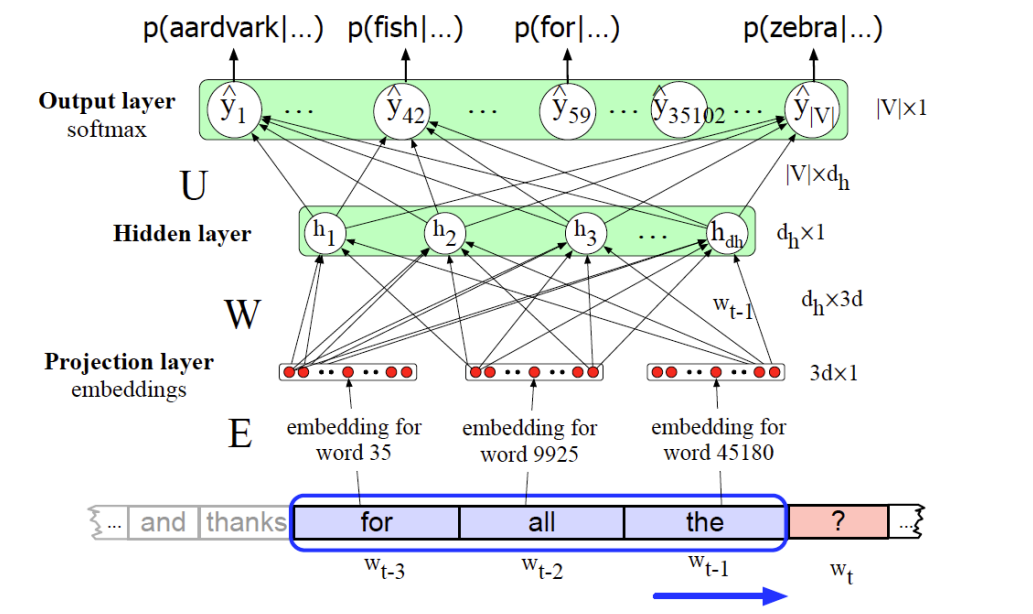
The 3 resulting embeddings vectors are concatened to produce the embedding layer.
This is followed by a hidden layer and an output layer whose softmax produces a probability distribution over words.
For example
The equations for a neural language model with a window size of 3, given one-hot input vectors for each input context word, are:
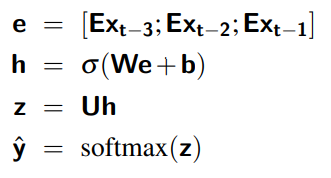
Forward inference in a neural language model
At each timestep
- computes a
-dimensional embedding for each context word - concatenates the three resulting embeddings to get the embedding layer
So