NLP - Lecture - Large Language Models (LLM)
- 7.pdf
- Slides
LLM definition: a computational agents that can interact conversionally with people using natural language. They are the main components that started the revolution in AI.
Recall Laguage Models and their properties. Here there is a summary:
- The simple n-gram language model assigns probabilities to sequences of words
- Generate text by sampling possible next words
- Is trained on counts computed from lots of text
Large Language Models are similar and different:
- Assigns probabilities to sequences of words
- Generate text by sampling possible next words
- Are trained by learning to guess the next word.
What does a model learn from pretraining
- With roses, dahlias and peonies, I Was surrounded by wloers.
- The room wasn’t just but it was enormous
- The square root of 4 is 2
- The author of “A Room of One’s Own” is Virgiana Woolf
- The professor told me that he. (this to say the model can learn bias like professors are only males).
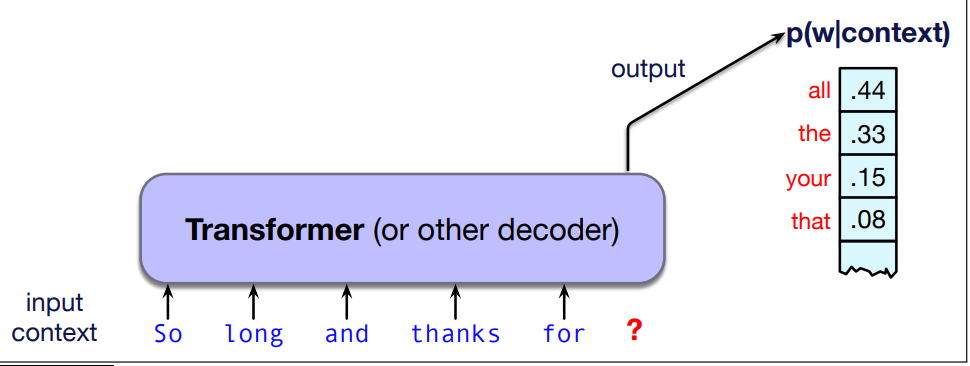
- A large language model is a neural network that takes as input a context or prefix, and outputs a distribution over possible next words
LLMs can generate text A model that gives a probability distribution over next words can generate by repeatedly sampling from the distribution. sampling means to choose a word from a distribution.
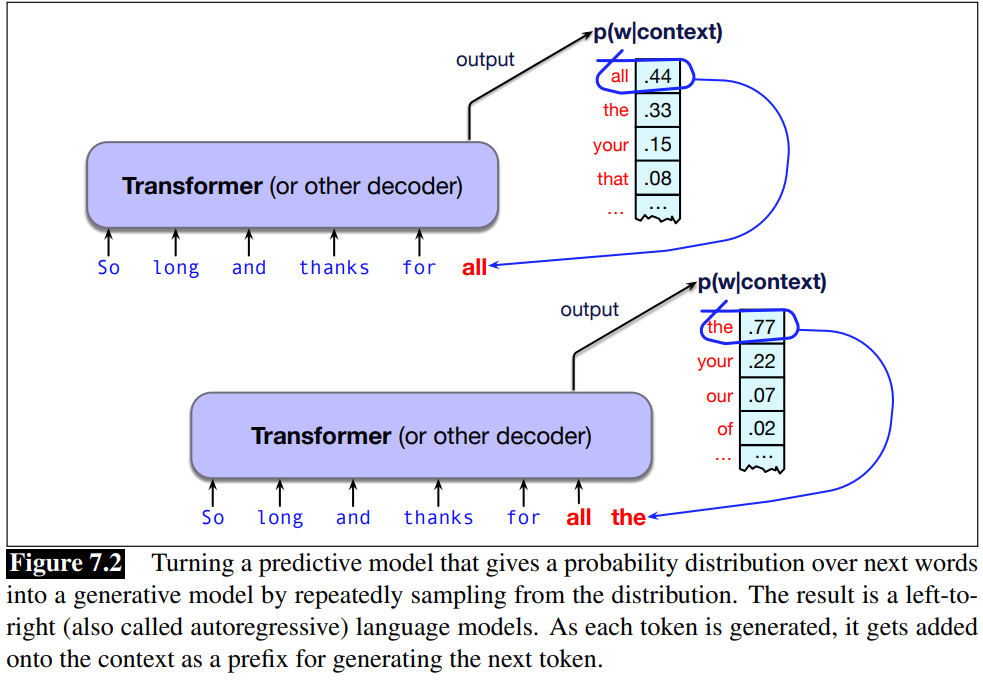 We have seen transformers that implements the causal or autoregressive language models.
We have seen transformers that implements the causal or autoregressive language models.
Generative AI: this idea of using computational models to generate text, as well as code, speech, and images constitutes the important new area called generative AI
Three architectures for LLM
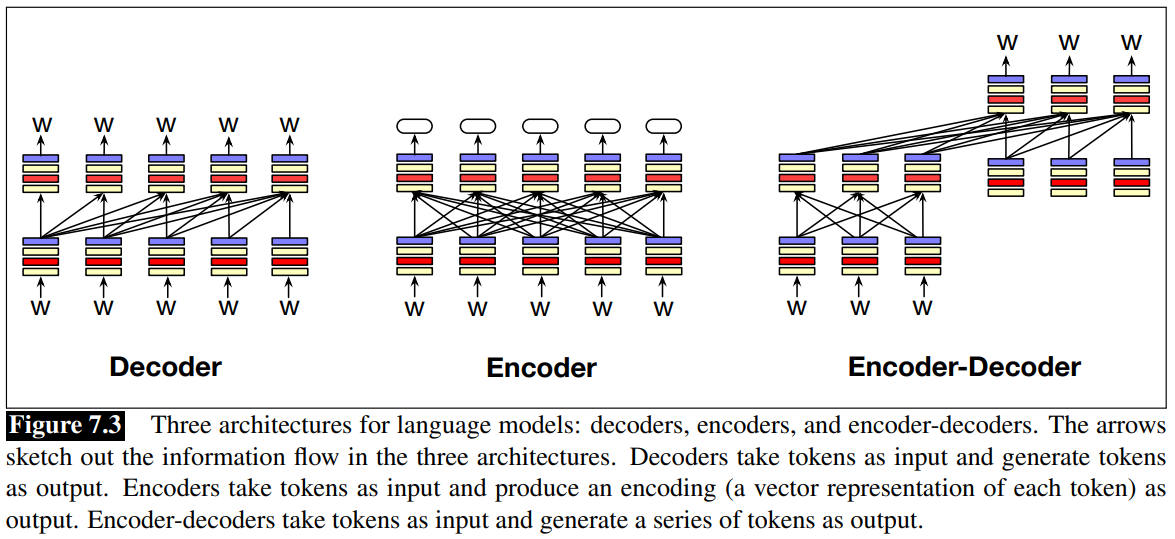
- Decoders: GPT, Claude, LLama, Mixtral
- Encoder: BERT family, HuBERT.
- Encoder-Decorders: Flan-T5, Whisper
Decoder: takes as input a series of tokens and iteratively generates an output token on at a time. They are generative models (generate text based on the history of previous tokens) See Autoregressive models.
Encoder: task as input a sequence of tokens and outputs a vector representation for each tokens. See Masked Language Models.
Encoder-Decoders: are very useful whenever the text we are dealing is used to generate other text that could be different from input text and of different length. As happens for example in text summarization and machine translation. Whisper is typically used for speech-to-text application.
What makes it different than the decoder-only models, is that an encoder-decoder has a much looser relationship between the input tokens and the output tokens, and they are used to map between different kinds of tokens.
There are many more recent architectures such as the state space model.
Conditional Generation of Text: The Intuition
Conditional Generation Definition A fundamental intuition underlying language models is that almost anything we want to do with language can be modeled as conditional generation of text.
Conditional generation is the task of generating text conditioned on an input piece of text. That is, we give the LLM an input piece of text, a prompt, and then have the LLM continue generating text token by token, conditioned on the prompt and the subsequently generated tokens.
We generate from a model by first computing the probability of the next token
NLP Tasks as Conditional Generation Let’s consider Sentiment Analysis of the sentence “I like Jackie Chan”.
We give the language model this string “The sentiment of the sentence ‘I like Jackie Chan’ is” and we observe the output.
Which word has an higher probability? for example positive or negative. So it just evaluates the conditional distribution.
P(“positive”|“The sentiment of the sentence ‘I like Jackie Chan’ is:”)
P(“negative”|“The sentiment of the sentence ‘I like Jackie Chan’ is:”)
We assign the most probable.

As a classification task.
Question Answering as Conditional Generation The same intuition can help us perform a task like question answering, in which the system is given a question and must give a textual answer.
QA: “Who wrote The Origin of Species”?
We give the language model this string: Q: Who wrote “The Origin of Species”? A:
And see what word it thinks fomr next:
It would determine that the most probable word is Charles:
P(w|Q: Who wrote the book ‘‘The Origin of Species"? A: Charles)
we might now see that Darwin is the most probable token, and select it.

Prompting
Instruction-tuning: we take a base language model that has been trained to predict words, and continue training it on a special dataset of instructions together with the appropriate response to each. The data set has many examples of questions together with their answers, commands with their responses, and other examples of how to carry on a conversation.
Prompt: a text string that a user issues to a language model to get the model to do something useful by conidtional generation Prompt engineering: the process of finding effective prompts for a task.
A prompt could be a question like What is a transformer network?
Perhaps structures: Q: What is a transformer network? A:
Or an instruction: Translate the following sentence into Hindi: 'Chop the garlic finely'
 This prompt uses a number of more sophisticated prompting characteristics.
This prompt uses a number of more sophisticated prompting characteristics.
- It specifies the two allowable choices (P) and (N), and ends the prompt with the open parenthesis that strongly suggests the answer will be (P) or (N).
- Note that it also specifies the role of the language model as an assistant.
Demonstration: Including some labeled examples in the prompt can also improve performance.
few-shot sampling: the task of prompting with examples zero-shot: don’t include labeled examples.

Demonstrations are generally drawn from a labeled training set.
They can be selected by hand, or the choice of demonstrations can be optimized by using an optimizer like DSPy (Khattab et al., 2024) to automatically chose the set of demonstrations that most increases task performance of the prompt on a dev set. This is part of a more general area called Language Model Programming.
The primary benefit of demonstrations seems more to demonstrate the task and the format of the output rather than demonstrating the right answers for any particular question. In fact, demonstrations that have incorrect answers can still improve a system (Min et al., 2022; Webson and Pavlick, 2022).
In-context learning Prompts are a way to get language models to generate text, but prompts can also can be viewed as a learning signal. This kind of learning is different than pretraining methods for setting language model weights via gradient descent methods that we will describe below.
We therefore call the kind of learning that takes place during prompting in-context learning that improves model performance or reduces some loss but does not involve gradient-based updates to the model’s underlying parameters.
System Prompt: Large language models generally have a system prompt, a single text prompt that is the first instruction to the language model, and which defines the task or role for the LM, and sets overall tone and context. The system prompt is silently prepended to any user text.
<system>You are a helpful and knowledgeable assistant. Answer
concisely and correctly.
<system> You are a helpful and knowledgeable assistant.
Answer concisely and correctly. <user> What is the capital
of France?
The fact that modern language models have such long contexts (tens of thousands of tokens) makes them very powerful for conditional generation, because they can look back so far into the prompting text.
For example the full system prompt for one language model Anthropic’s Claude Opus4, is 1700 words long and includes sentences like the following:
Claude should give concise responses to very simple questions,
but provide thorough responses to complex and open-ended
questions.
Claude is able to explain difficult concepts or ideas clearly.
It can also illustrate its explanations with examples, thought
experiments, or metaphors.
Claude does not provide information that could be used to
make chemical or biological or nuclear weapons
For more casual, emotional, empathetic, or advice-driven
conversations, Claude keeps its tone natural, warm, and
empathetic
Claude cares about people’s well-being and avoids encouraging
or facilitating self-destructive behavior
If Claude provides bullet points in its response, it should
use markdown, and each bullet point should be at least 1-2
sentences long unless the human requests otherwise
It’s also possible to create system prompts for other tasks, like the following prompt for creating a general grammar-checker (Anthropic, 2025):
Your task is to take the text provided and rewrite it into
a clear, grammatically correct version while preserving
the original meaning as closely as possible. Correct any
spelling mistakes, punctuation errors, verb tense issues,
word choice problems, and other grammatical mistakes.
Each user can then make a prompt to have the system fix the grammar of a particular piece of text.
Generation and Sampling
Which tokens should a language model generate at each step?
The generation depends on the probability of each token, so let’s remind ourselves where this probability distribution comes from.
The internal networks for language models (whether transformers or alternatives like LSTMs or state space models) generate scores called logits (real valued numbers) for each token in the vocabulary.
This score vector
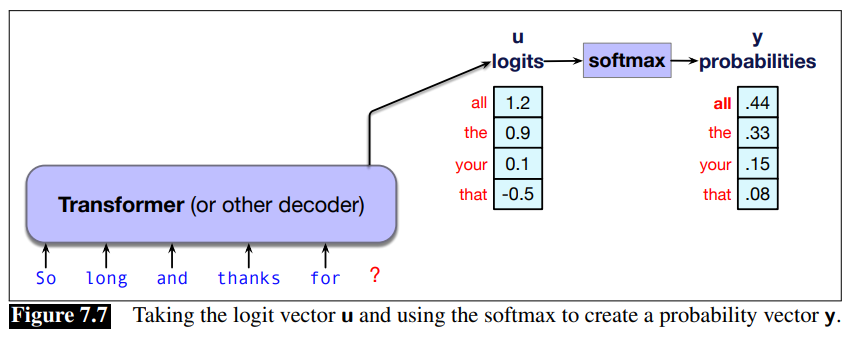
Decoding: the task of choosing a token to generate based on the model’s probabilities is often called decoding.
Greedy decoding
A greedy algorithm is one that makes a choice that is locally optimal, whether or not it will turn out to have been the best choice with hindsight.
Thus in greedy decoding, at each time step in generation, we turn the logits into a probability distribution over tokens and then we choose as the output
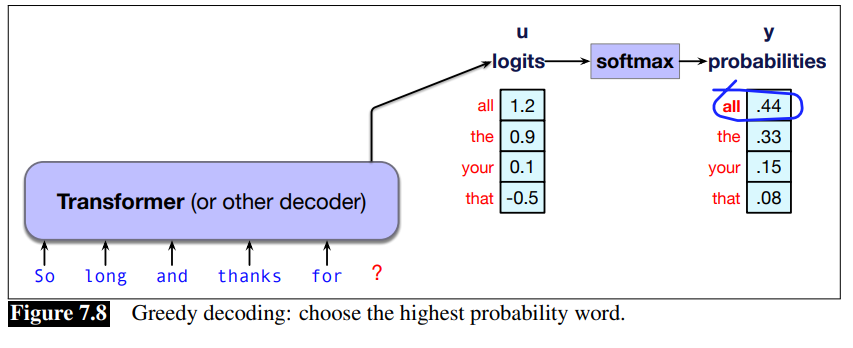 Greedy Decoding Drawbacks:
In practice, however, we don’t use greedy decoding with large language models. A major problem with greedy decoding is that because the tokens it chooses are (by definition) extremely predictable, the resulting text is generic and often quite repetitive.
Greedy Decoding Drawbacks:
In practice, however, we don’t use greedy decoding with large language models. A major problem with greedy decoding is that because the tokens it chooses are (by definition) extremely predictable, the resulting text is generic and often quite repetitive.
Greedy is good when you want to use a LLM for sentiment analysis. In fact, greedy decoding is so predictable that it is deterministic; if the context is identical, and the probabilistic model is the same, greedy decoding will always result in generating the exactly same string.
But in most task people prefer text which has been generated by sampling methods that introduce a bit more diversity into the generations.
Random Sampling
Thus the most common method for decoding in large language models involves sampling.
That is, we randomly select a token to generate according to its probability in context as defined by the model, generate it, and iterate. We could think of this as rolling a die and choosing a token according to the resulting probability.
We are more likely to generate tokens that the model thinks have a high probability and less likely to generate tokens that the model thinks have a low probability.
To generate text from a large language model we’ll just generalize this model a bit: at each step we’ll sample tokens according to their probability conditioned on our previous choices, and we’ll use the large language model as the probability model that tells us this probability.
The algorithm is called random sampling, or random multinomial sampling random sampling (because we are sampling from a multinomial distribution across words).
Formalize as:
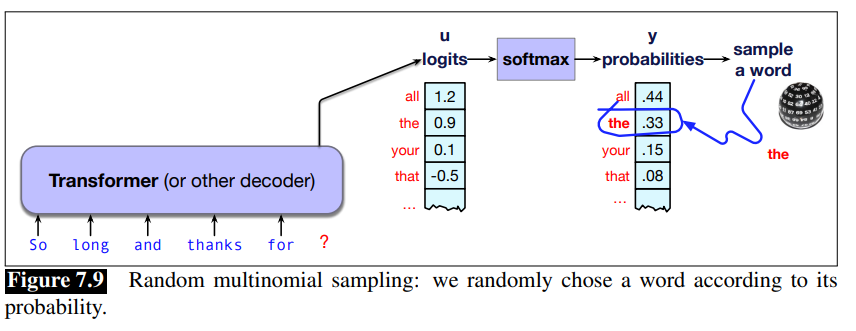
Random sampling doesn’t work well either. The problem is that even though random sampling is mostly going to generate sensible, high-probable tokens, there are many odd, low-probability tokens in the tail of the distribution, and even though each one is low-probability, if you add up all the rare tokens, they constitute a large enough portion of the distribution that they get chosen often enough to result in generating weird sentences.
In other words, greedy decoding is too boring, and random sampling is too random. We need something that doesn’t greedily choose the top choice every time, but doesn’t stray down too far into the very low-probability events. There are three standard sampling methods that modify random sampling to address these issues. We’ll describe the most common, temperature sampling here, and talk about two others (top-k and top-p) in the next chapter.
Most modern LLM interfaces combine top-k and temperature sampling by default.
Temperature Sampling
Idea: reshape the probability distribution to increase the probability of the high probability tokens and decrease the probability of the low probability tokens.
We implement this intuition by simply dividing the logit by a temperature parameter
- Raw logis are divided by a factor
- If it it’s low
the larger the value that we pass to the softmax and the model becomes very confident and boring (it is more greedy)
- If it it’s low
- The softmax function has the chracteristic is that if i give it an high value it is pushed toward 1, if i give it a low value, it is pushed toward 0.
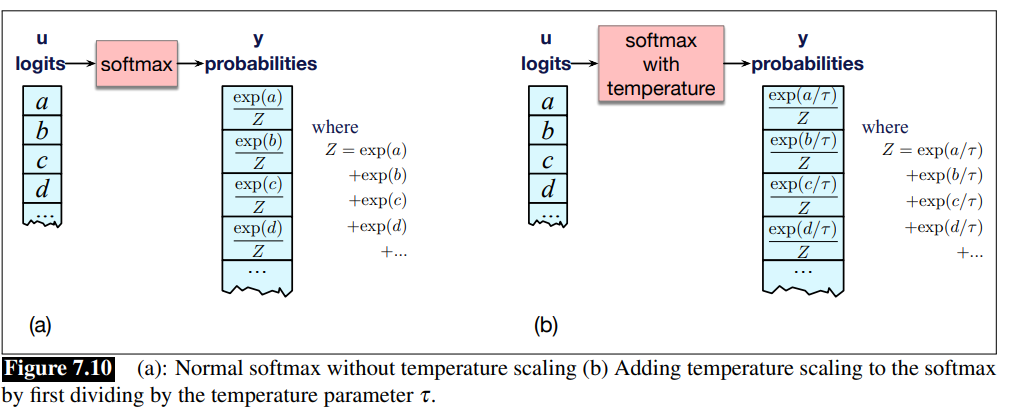
The intuition for temperature sampling comes from thermodynamics, where a system at a high temperature is very flexible and can explore many possible states, while a system at a lower temperature is likely to explore a subset of lower energy (better) states.
In low-temperature sampling, we smoothly increase the probability of the most probable tokens and decrease the probability of the rare tokens.
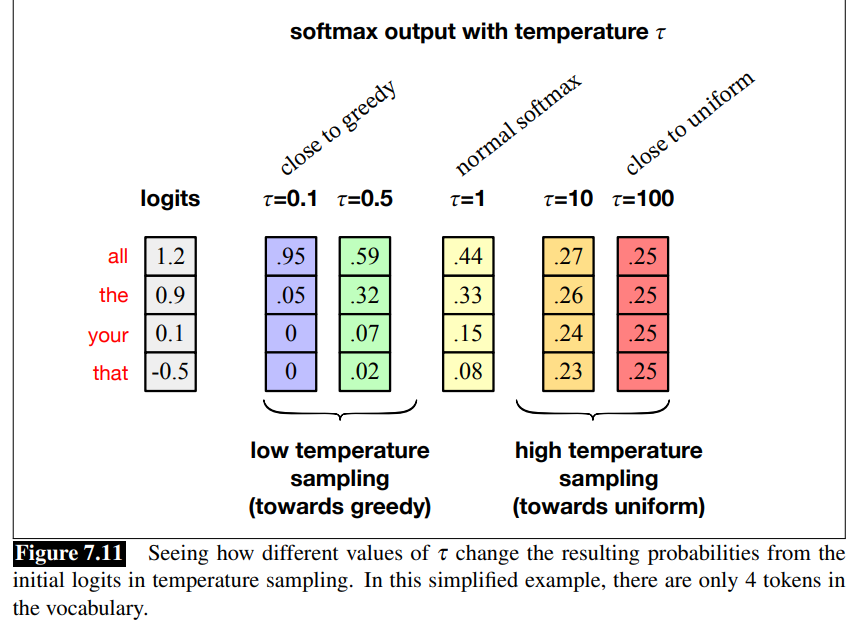
is very similar to greedy sampling is very similar to random sampling
High-temperature sampling: there are some cases where we can use
Training Large Language Models
How do we learn a language model? What is the algorithm and what data do we train on? Language models are trained in three stages:
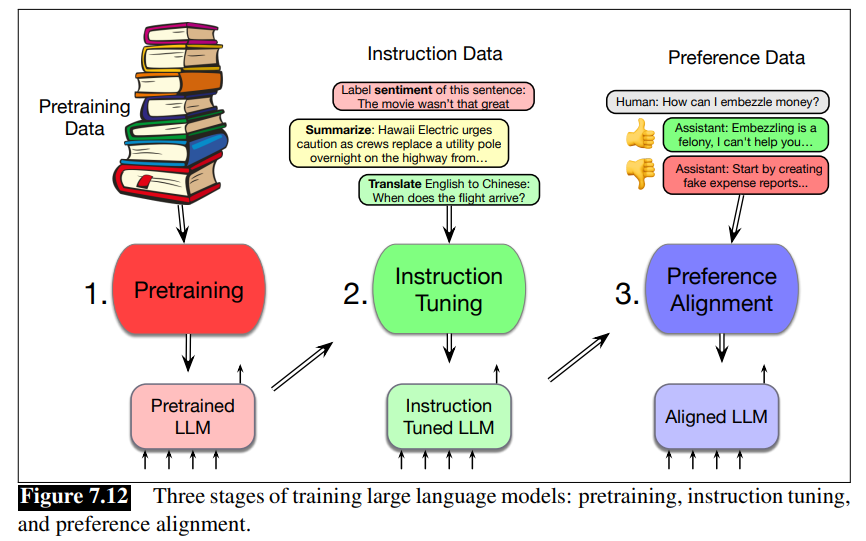
- Pretraining: In this first stage, the model is trained to incrementally predict the next word in enormous text corpora. The model uses the cross-entropy loss, sometimes called the language modeling loss, and that loss is backpropagated all the way through the network. The training data is usually based on cleaning up parts of the web. The result is a model that is very good at predicting words and can generate text.
- Instruction tuning, also called supervised finetuning or SFT: In the second stage, the model is trained, again by cross-entropy loss to follow instructions, for example to answer questions, give summaries, write code, translate sentences, and so on. It does this by being trained on a special corpus with lots of text containing both instructions and the correct response to the instruction.
- Alignment, also called preference alignment. In this final stage, the model is trained to make it maximally helpful and less harmful. Here the model is given preference data, which consists of a context followed by two potential continuations, which are labeled (usually by people) as an ‘accepted’ vs a ‘rejected’ continuation. The model is then trained, by reinforcement learning or other reward-based algorithms, to produce the accepted continuation and not the rejected continuation.
Pretraining
Recall from Transformers that usually LLM are trained using teacher forcing (giving the model the correct history sequence to predict next word rather than its best guess from the previous time stap).
The loss function for a batch of length
The weights in the network are then adjusted to minimize this average cross-entropy loss over the batch via gradient descent using error backpropagation on the computation graph to compute the gradient.
Pretraining corpora for large language models LLMs are mainly trained on text scraped from the web.
Because these training corpora are so large, they are likely to contain many natural examples that can be helpful for NLP tasks, such as question and answer pairs (for example from FAQ lists), translations of sentences between various languages, documents together with their summaries, and so on.
Key sources include:
- Common Crawl, which collects billions of web pages.
- Colossal Clean Crawled Corpus (C4) is a filtered dataset about 156 billion English tokens.
- Wikipedia
- News websites
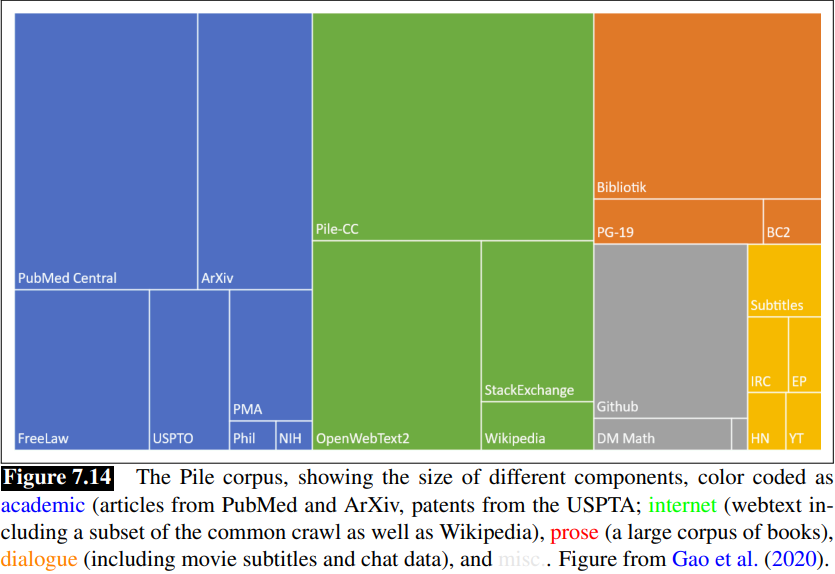 The Pile is an 825 GB English text corpus that is constructed by publicly released code, containing again a large amount of text scraped from the web as well as books and Wikipedia.
The Pile is an 825 GB English text corpus that is constructed by publicly released code, containing again a large amount of text scraped from the web as well as books and Wikipedia.
Filtering for quality and safety:
- Pretraining data drawn from the web is filtered for both quality and safety.
- Quality filters are classifiers that assign a score to each document. Quality is of course subjective, so different quality filters are trained in different ways,
- But often to value high-quality reference corpora like Wikipedia, books, and particular websites and to avoid websites with lots of PII (Personal Identifiable Information) or adult content.
- Filters also remove boilerplate text which is very frequent on the web.
Problems with scraping:
- Copyright: much of the text in these datasets is copyrighted
- Data consent: Website owners can indicate they don’t want their site crawled
- Privacy: websites can contain private IP addresses and phone numbers
- Skew: Training data is also disproportionately generated by authors from the US and from developed countries, which likely skews the resulting generation toward the perspectives or topics of this group alone.
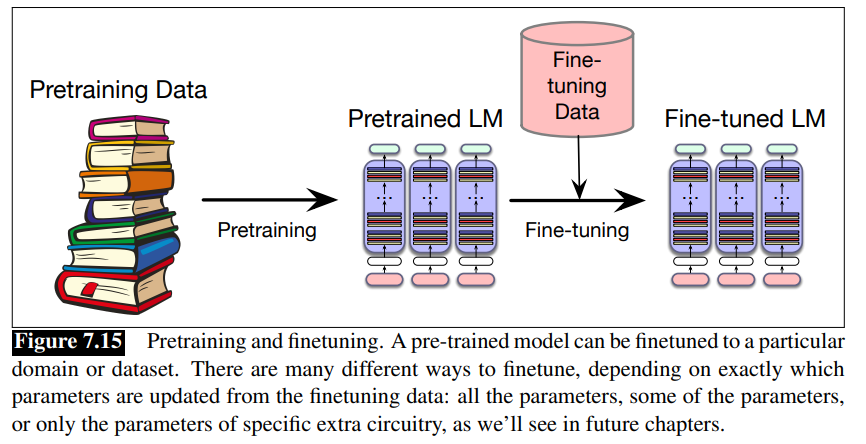
Finetuning
What if we need our LLM to perform well in a domain that it didn’t encounter during pre-training? What if it’s a specific medical or legal doman? Or what if a multiligual LM needs to see more data on a language?
Finetuning: the process of taking a fully pretrained model and running additional training passes using the cross-entropy loss on some new data is called finetuning. The word “finetuning” means the process of taking a pretrained model and further adapting some or all of its parameters to some new data.
The method we describe here, in which we just continue to train, as if the new data was at the end of our pretraining data, can also be called continued pretraining.
Evaluating LLMs
Perplexity
Recall in N-gram language models section, we defined perplexity.
Also in LLMs perplexity is used to measure how well the LM predicts unseen text.
The perplexity of a model
Because of the inverse in the higher the probability of the word sequence, the lower the perplexity. Thus the the lower the perplexity of a model on the data, the better the model.
One caveat: because perplexity depends on the number of tokens
Downstream tasks: Reasoning and world knowledge
Perplexity measures one kind of accuracy: accuracy at predicting words.
A LLM can be used on various tasks like question answering, machine translation or reasoning, that may need different metrics.
One metric for measuring accuracy in answering questions focusing on multiple-choice is based on a dataset called MMLU (Massive Multitask Language Understanding), a commonly-used dataset of 15,908 knowledge and reasonin questions in 57 areas including medicine, mathematics, computer science, law and others.

Data Contamination: data contamination is when some part of the dataset that we are testing on (a test set of any kind) makes its way into our training set. For example, since LLMs train on the web and MMLU is on the web, it may incorporate some MMLU questions into their training. One way to mitigate data contimination is to make available the exact training data used to train a model, or at least to report training overlap with specific test sets.
Other Factors to Evaluate
- Size: big models take lots of GPUs and time to train and memory to store
- Energy usage: can measure kWh or kilograms of
emitted - Fairness: benchmarks measure generated and racial stereotypes or decreased performance for language from or about some groups. StereoSet, RealToxicityPrompts and BBQ among many others ar edataset that measure the strenght of these biases.
- Leaderbors like Dynabench and general evaluation protocols like HELM.
Ethical and Safety Issues with Language Models
Ethical and safety issues have been key to how we think about designing artificial agents since well before we had large language models.
Hallucination: LLMs are prone to saying things that are false. The training algorithms we have seen so far don’t have any way to enforce that the text is generated is correct or true.
Language Models can suggest unsafe actions: like suggesting users to do dangerous or illegal things like harming themselves or others. They can provide wrong medical advice, or when indicating the intentions of self-harm, incorrect advice can be dangerous and even life-threatening.
Hallucination and factuality can be mitigated with methods like Retrieval Augmented Generation.
Leak: Large language models can leak information from their training data. An adversary can extract training-data text from a language model such as a person’s name, phone number, and address (Henderson et al. 2017, Carlini et al. 2021). This becomes even more problematic when large language models are trained on extremely sensitive private datasets such as electronic health records.
Illegal and unethical activies: language models can assists users for generating text for fraud, phising, propaganda, disinformation campaigns or other socially harmful activities.
Finding ways to mitigate all these ethical safety issues is an important current research area in NLP.
Anaylizing training data One important step is to carefully analyze the data used to pretrain large language models as a way of understanding safety issues of toxicity, discrimination, privacy, and fair use, making it extremely important that language models include datasheets or model cards giving full replicable information on the corpora used to train them. Open-source models can specify their exact training data.
Value sensitive design—carefully considering possible harms in advance — is also important. (Dinan et al., 2021) give a number of suggestions for best practices in system design. For example getting informed consent from participants, whether they are used for training, or whether they are interacting with a deployed LLM is important.
Historical Notes
The technology used for language models can also be applied to other domains and tasks, like vision, speech, and genetics. Foundation model is sometimes used as more general term across domains and area when the elements we are computing over are not necessarily words. Bommasani et al. (2021) is a broad survey that sketches the opportunities and risks of foundation models, with special attention to large language models.