NLP - Lecture - Word Embeddings
Today’s lesson is on how to create word embeddings.
To create a word embedding we need:
- A corpus text: as sawn in previous lesson the context of a word tells you what type of words tend to occur that specific word. The context is important as this is what will give meaning to each word embedding.
- an embedding method
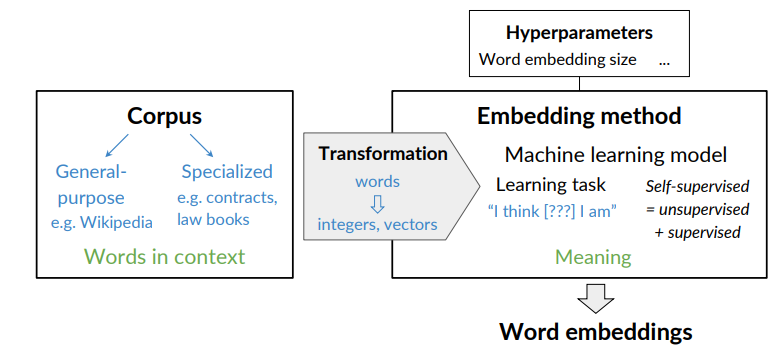
Sparse vs dense vectors
Count vectors — even when weighted using TF-IDF or PPMI — are typically very long, with lengths ∣V∣ ranging from 20,000 to 50,000. Another problem is that they are sprase that means most elements are zero.
An alternative approach is to learn vector representations directly from data, creating short (50–1000 dimensions) and dense vectors instead.
Why dense vectors?
- Short vectors are easier to use as features in a machine learning model.
- Dense vector may generalize better than explicit counts and may do better at capturing synonymy.
For example, car and automobile are synonyms, but in a sparse representation they occupy different dimensions, while in a dense embedding they can be represented by similar vectors.
How to create word embeddings?
Basic Word Embedding Models:
- Word2vec (Google, 2013) see word2vec
- Global Vectors (GloVe) (Standford, 2014) see glove
- fastText( Facebook, 2016)
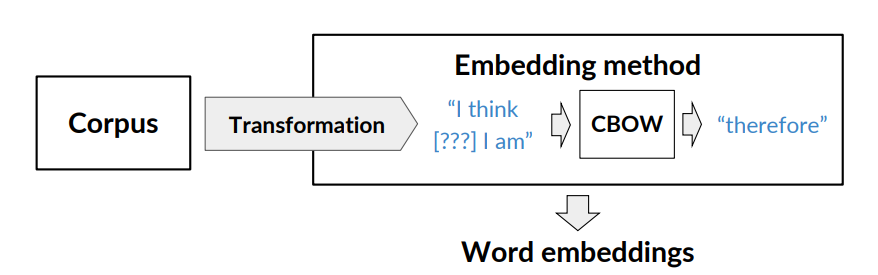
Word2vec uses a shallow neural network to learn word embeddings. There are two algorithms: one based on continuos bag-of-words (CBOW) and the other based on continuos skip-gram/skip-gram with negative sampling.
Global Vectors (GloVe) factorizes the log of the corpora word co-occurence matrix.
See Vector Space Models and
fastText considers the structure of words by representing words as an n-gram of characters. In this way it supports out-of-vocabulary words, since it consider characters. (See the end of previous lesson NLP - Lec 10). Word embedding vectors can be averaged together to make vector representations of phrases and sentences.
Advanced Word Embedding Models
If in the training data you have found that plant means flower you have only that. However, with contextual embeddings, the model can distinguish between different meanings based on context — for instance, plant as flower will have one embedding, while plant as power plant will have another.
Modern deep neural network architectures refine word representations according to their context, allowing words to have different embeddings depending on usage.
Some well-known examples includes:
- BERT (Google,2018)
- ELMo (Allen Institute for AI, 2018)
- GPT-2 (OpenAI, 2018)
These are all available as pre-trained Model, so we can just train the embeddings.
Word2vec
- Popular embedding method
- Very fast to train
Idea: predict rather than count.
Word2vec provides various options:
- Continuios Bag-of-Words (CBOW)
- Skip-gram with negative sampling (SGNS)
Continuos Bag-of-Words Model (CBOW)
The set of word embeddings is a byproduct of the learning task.
What is the rational behind center word prediction? It’s based on the distributional hyothesis
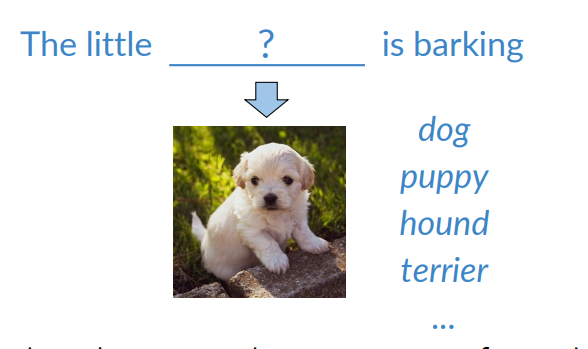 If two unique words are both frequently surrounded by similar sets of words in various sentences, then those words are semantically related.
If two unique words are both frequently surrounded by similar sets of words in various sentences, then those words are semantically related.
The model will end up learning the meaning of words based on their contexts.
Creating a Training Example
Using the corpus to create training data
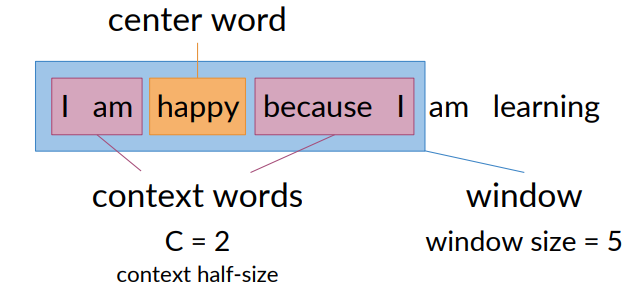
- I am happy because I am learning
Given a center word, e.g., happy, define the context as the C words just before and after the center word
- C (hyperparameter of CBOW) is the half size of the context, C = 2 in this example
- The window is the count of the center word plus the context words
To train the models, one needs a set of examples. Context words and the center word to predict, each.
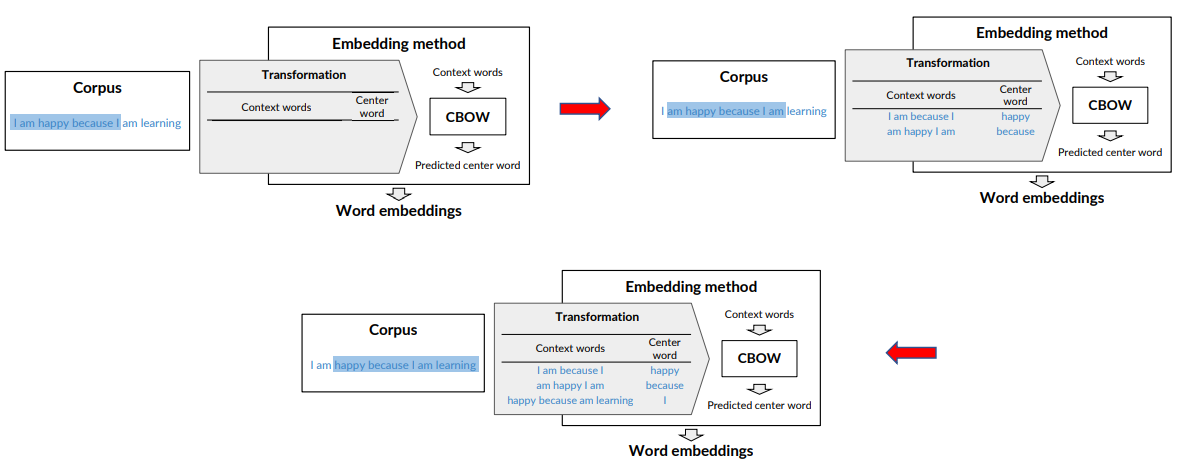 In the first phase of the training i use happy as center word and i am happy because i as window. Then in the next i move the window, consider ”because” as center and so on.
In the first phase of the training i use happy as center word and i am happy because i as window. Then in the next i move the window, consider ”because” as center and so on.
To the model
- context words as inputs
- center words as outputs
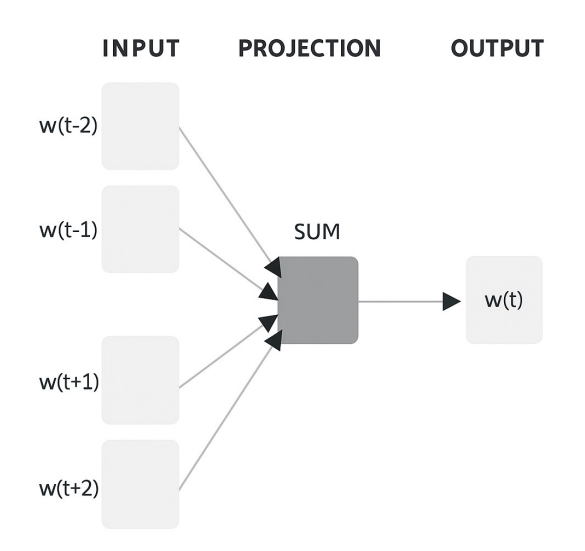 In this figure we are using a single layer percerptron, the output is obtained by applying the sum of the weight to the get the output.
In this figure we are using a single layer percerptron, the output is obtained by applying the sum of the weight to the get the output.
Cleaning and Tokenization
The words of the corpus should be case insensitive
- Uppercase or lowercase
Then handling of punctuations
- E.g., all interrupting punctuation marks as a single special word in the vocabulary
- One could ignore non-interrupting punctuation marks, e.g., quotation marks
- Collapse multi-sign marks into single marks, …
Handling of numbers
- Drop all numbers not carrying any meaning
- Keep the numbers if having special meaning for the use case
- Tag as a special token if too many, e.g., many area codes
Handling of special characters (Math, currency, … symbols)
- Usually, dropped
Handling special words (from tweets or reviews, e.g., Emojis, hashtags)
- Depending on the goals of your task
To summarise:

Transforming Words into Vectors
To feed the context words into the model and to predict and central word, they must be suitably represented.
Center words into vectors:
- First, create the vocabulary V of unique words in the corpus
- Encode each word as one-hot vector of size |V|

Context words into vectors: create a single vector that represents the context from all the context words.
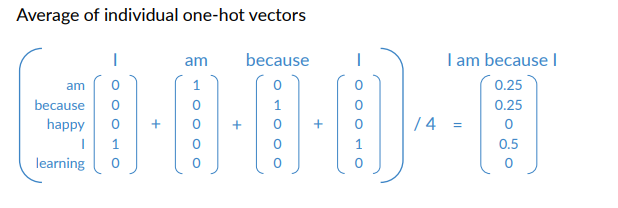
Final Prepared Trained Sets
Example: First Window. Note that the vectors are actually colmen vectors.

Note that the vectors are actually column vectors.
Recap on neural networks
- ML2 - Lecture 7 - Single Layer Neural Network
- ML2 - Lecture 8 - Multi Layer Neural Network
- ML2 - Lecture 9.1 - Error Back Propagation
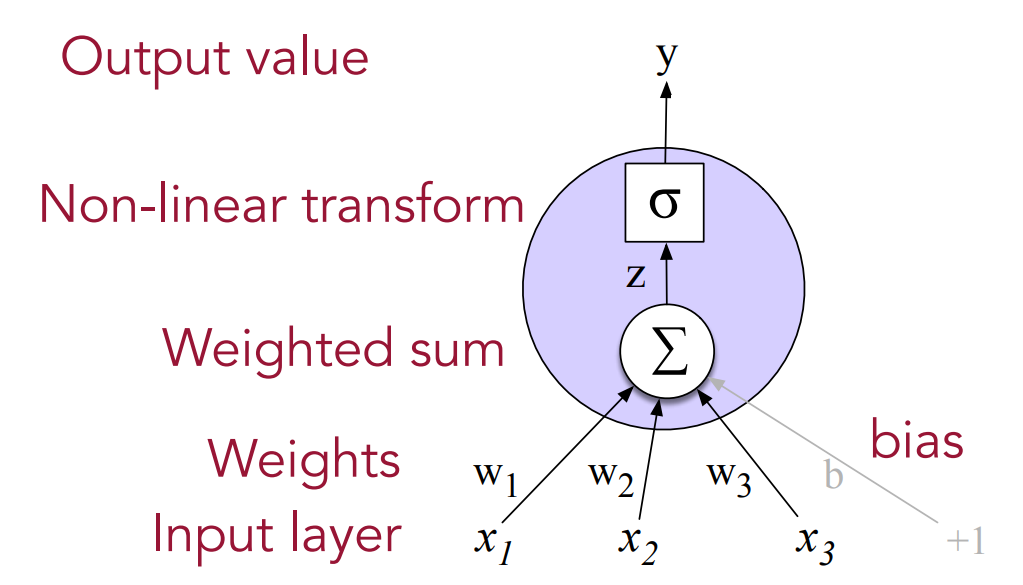 That can also be multi-layer percerptron.
That can also be multi-layer percerptron.
Architecture of the CBOW Model
The CBOW model is based on a shallow dense neural network.
- Hyperparameters are the N word embedding size (typicall 100-1000)
- Parameters are
to be learned during the training - word embeddings are derived from weight matrices
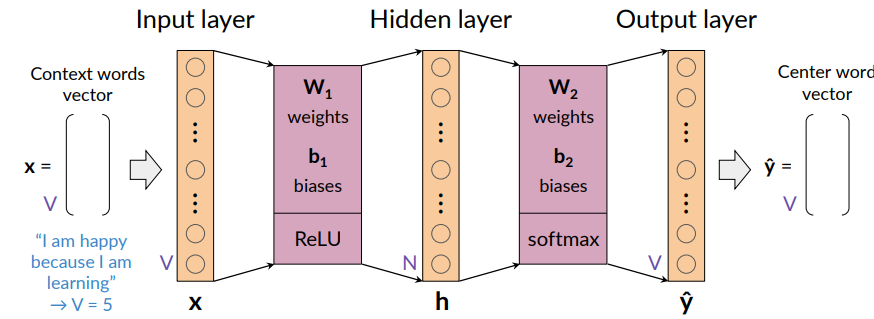
Notice that if i want like a word embedding size of 100, i need to consider h=100 nodes in the hidden layer. Input and output are of the size of the vocabulary.
To map from input layer to hidden layer, we compute weights and biases and apply ReLu. Then From hidden layer to output layer we compute weights and biased and apply softmax function
Softmax and ReLU are nonlinear functions.
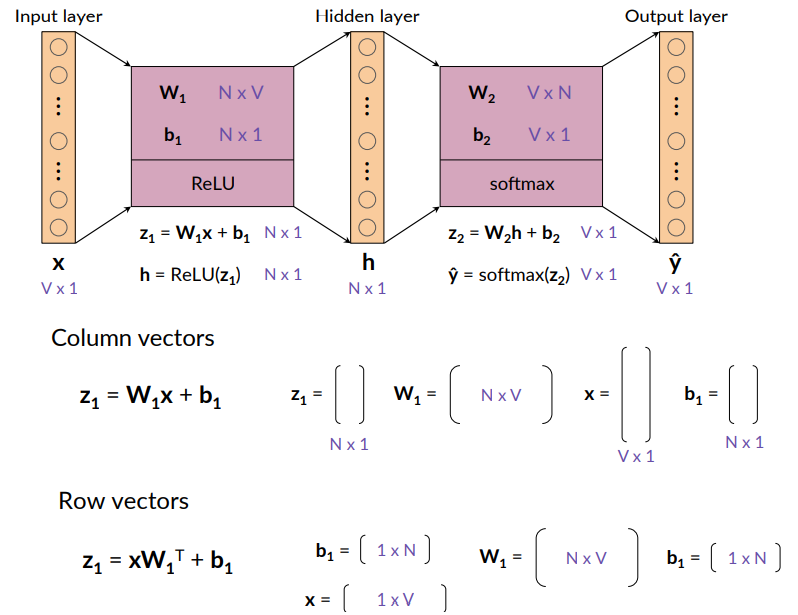
We apply the softmax in the second part because this is a classification problem, so i want to interpret the output of my network as probability and in order to do that i apply the softmax function.
Dimensions (Batch input):
- To quick the learning, the model is fed with several inputs (m) and provides several outputs at the same time.
- m is called batch size and is an hyperparameter
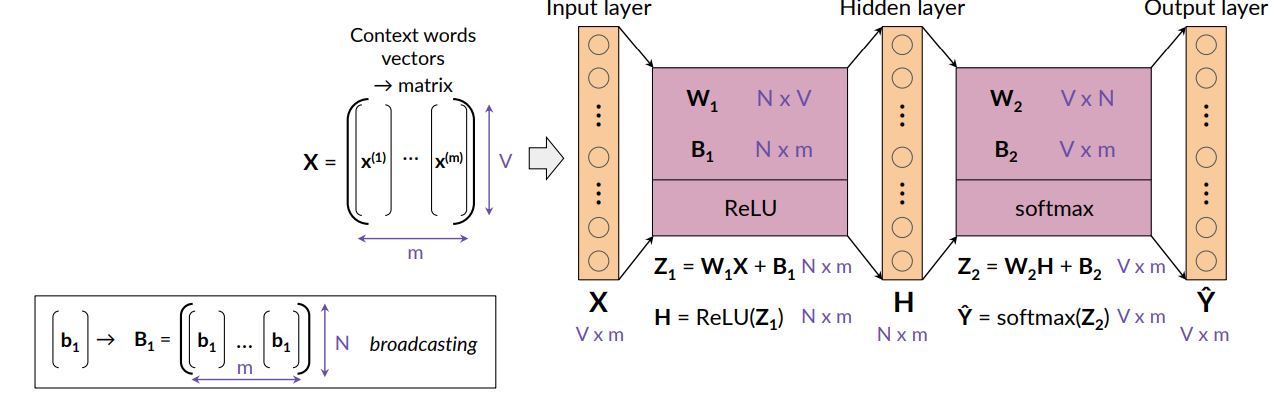 For output i will get the predictions for each of the N examples. So another matrix of size
For output i will get the predictions for each of the N examples. So another matrix of size
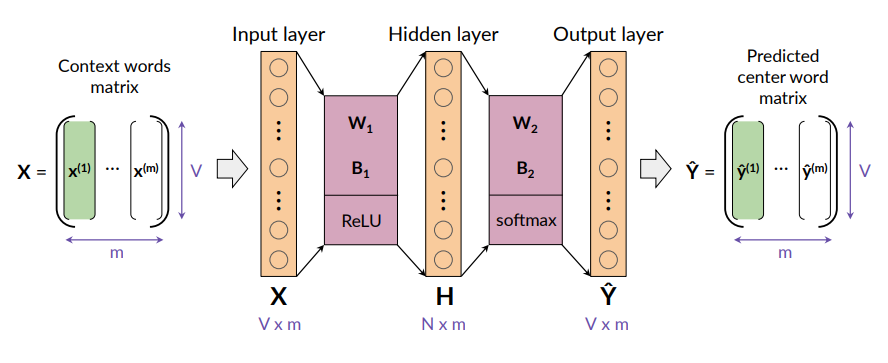
The vector from the first column of X is transformed into the vector corresponding to the first column of
Activation Functions: Hidden Layer Neurons
Rectified Linear Unit ( Rectified Linear Unit (ReLU)) defined as 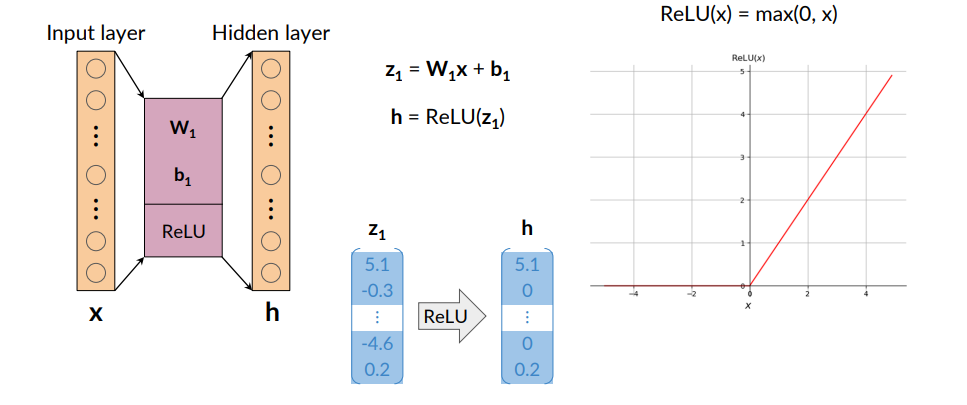
Activation Functions: Output Neurons
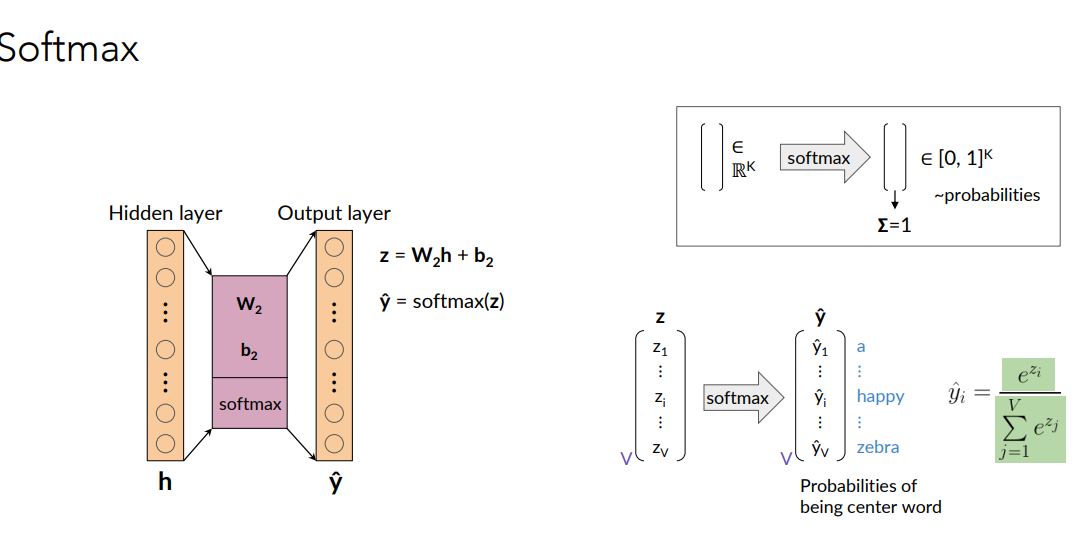 So basically i have the output of the hidden layer, to which is applied the softmax. the softmax outputs probabilities, and each output will be the probability of being a center word in a window of words.
So basically i have the output of the hidden layer, to which is applied the softmax. the softmax outputs probabilities, and each output will be the probability of being a center word in a window of words.
Here it is a clearer example
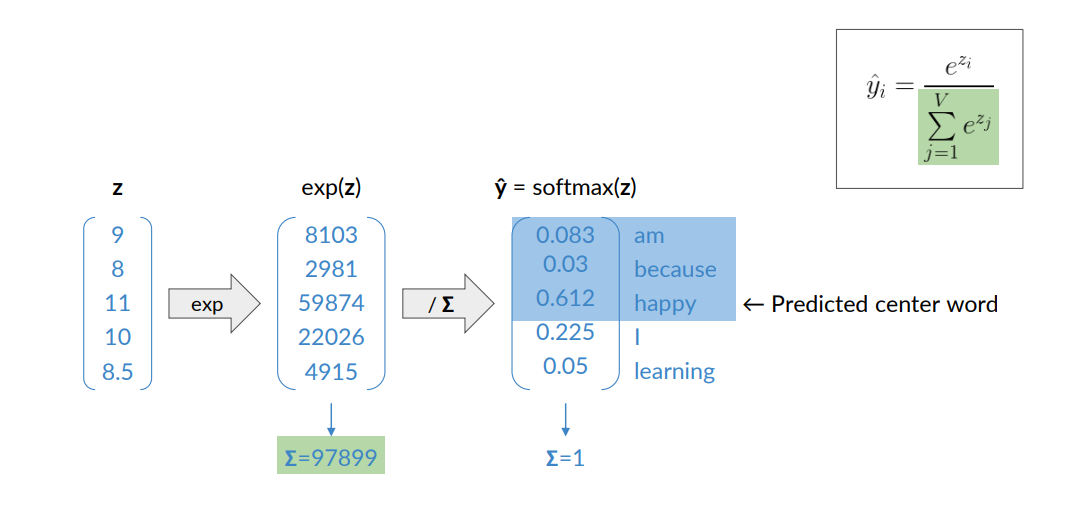
- We have the activation
from the hidden layer - then we apply the exponential to get these numbers (we do this because we may have negative values, so exponential transform everything to positive
- Then we divided everything by total sum such that each sum is exactly one
- In this way we can interpret the output vector as a probability, then we apply the softmax to this vector and obtain the predicted center word.
Training Loss
The training procedure involve the definition of the loss function that measure the error that the network does during the training of words.
Since we are dealing with a classification problem, the loss function is defined as the cross-entropy.
The learning is done with gradient descent.
Let’s see the cross entropy intuition:
The cross-entropy is used in classiication tasks that uses the softmax activation in the output layer
It is defined as:
Suppose we consider I am happy because i’m learning, with C=2.
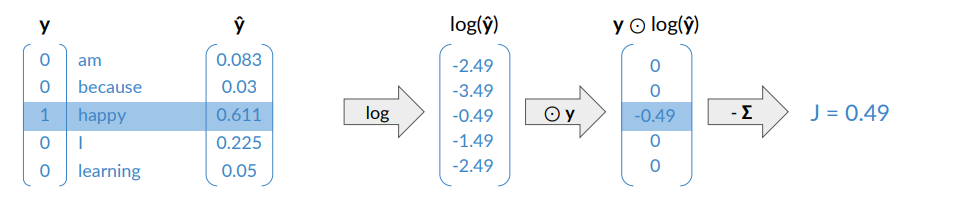
uses the one-hot encoding, the other one are zero. - If the network answers correctly what you get here is that
is one, so you ahve just the log of what you predicted.
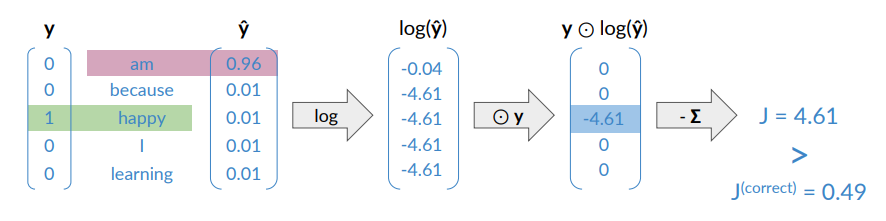 What happens if the network respond wrong? In this case “am” is the correct word.
What happens if the network respond wrong? In this case “am” is the correct word.
In the case of wrong response you get a larger value for the loss.
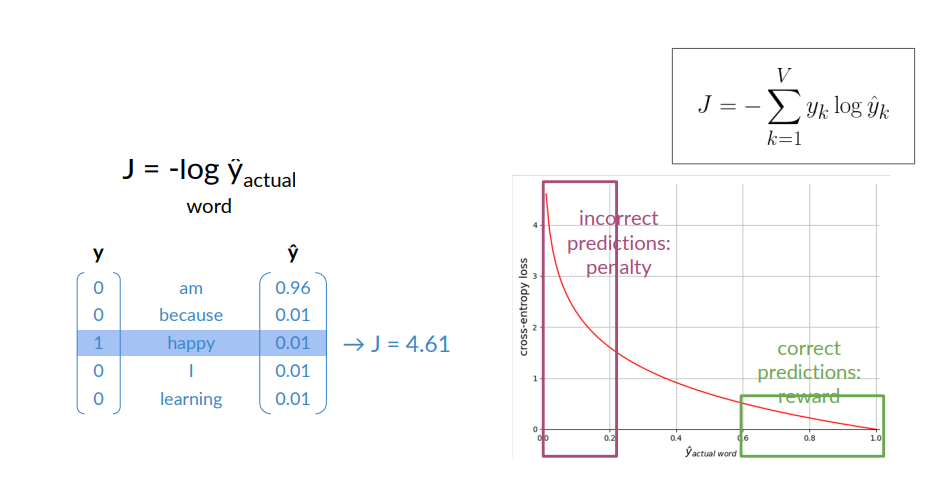
The loss rewards correct predictions and penalizes the incorrect ones.
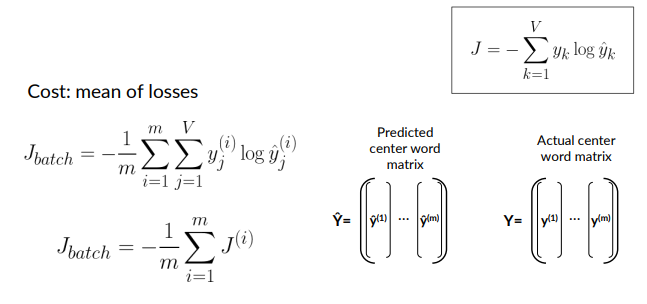
Cost
The cost is referred to as the loss computed on batch examples. It is mean of cross-entropy lossess of the individual examples.
Learning: Minimizing the cost
To minimize the cost we use backpropagation by updating their weights based on the error made during prediction.
The loss function on a batch is defined as:
Calculate gradients: the chain ruleis used to compute the partial derivatives of the loss
Applying gradient descent we adjust the parameters ideally moving in a direction toward a local minimum.
Minimizing the loss means the model will, on average, make more accurate predictions.
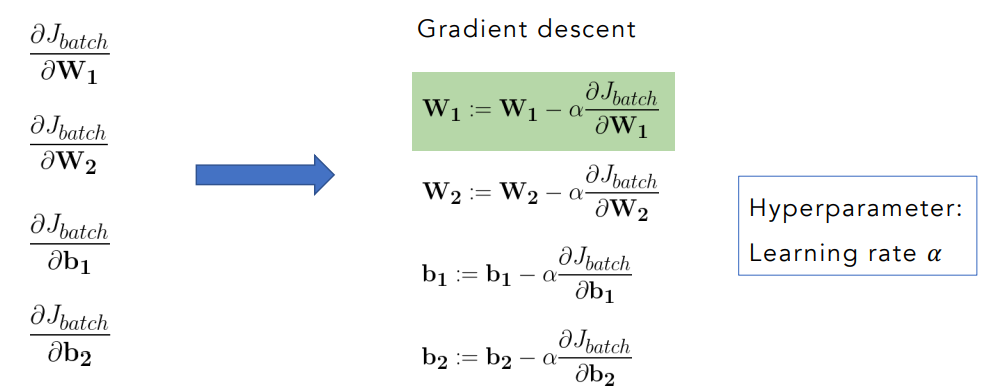
The learning rate is an hyperparamter, indicated with
- If it’s too large, the model may overshoot the minimum and fail to converge
- if it’s too small the training becomes slow or may get stuck.
Extracting Word Embedding Vectors
Once the training is completed, the next step is to extract the word embeddings.
The embeddings are not directly produced as an explicit output of the training process; rather, they are a by-product of it. It is learned implicitly through the network’s internal weight representations.
Option 1 is to consider the column vectors of 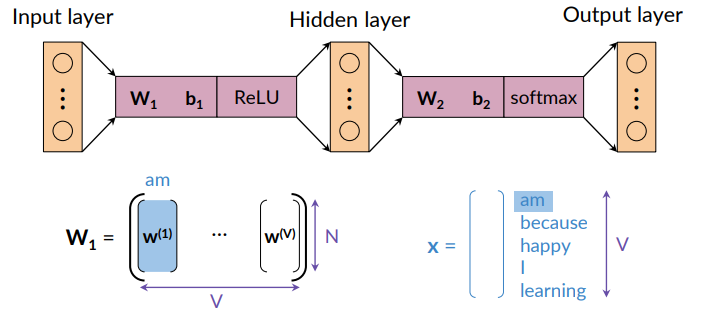
Option 2 is to consider the row vectors of 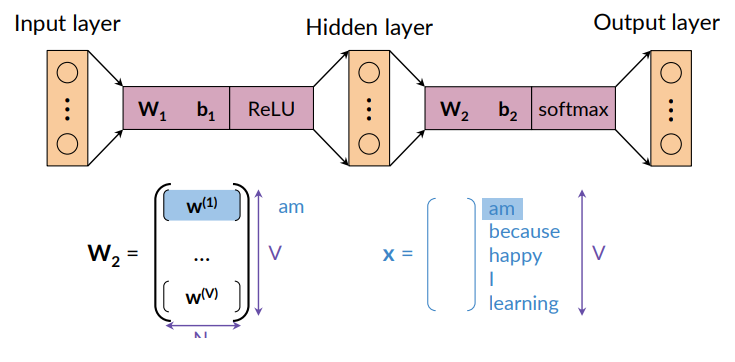
Option 3 is the average of the representations from option 1 and option 2 .
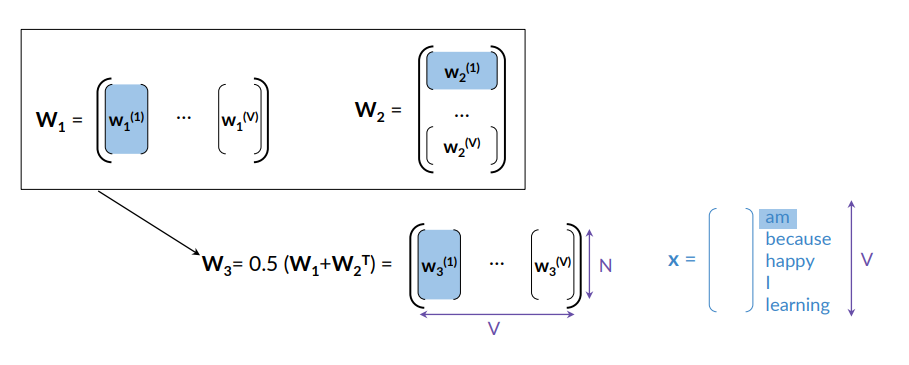
Some Properties of the Word Embeddings
Small Windows (C = ±2)
- Capture syntactic similarity — words that play a similar grammatical or structural role.
- Example: In Harry Potter, the nearest neighbors of Hogwarts might be other fictional schools like Sunnydale, Evernight, or Blandings.
Large Windows (C = ±5)
- Capture semantic or topical relatedness — words that appear in the same overall context or theme, even if they’re not similar in meaning.
- Example: In Harry Potter, the nearest neighbors of Hogwarts might be Dumbledore, half-blood, or Malfoy.
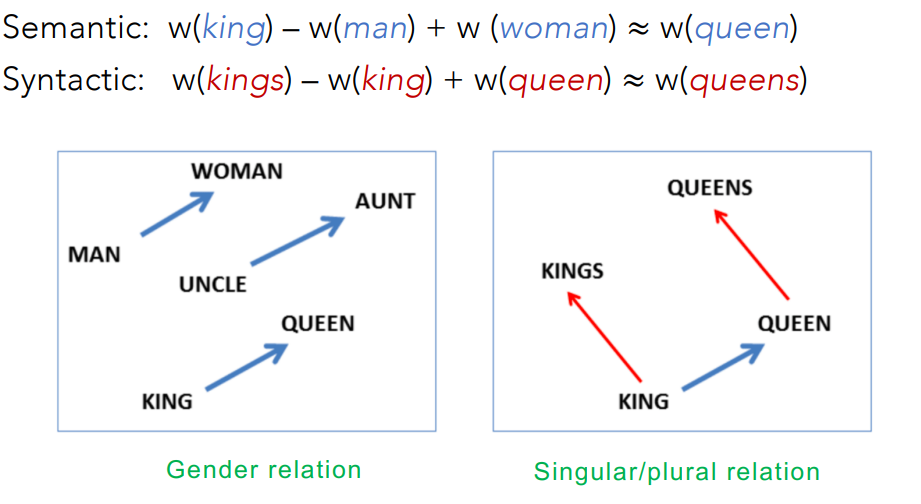
Analogical Relations
The classic parallelogram model of analogical reasoning.
To solve: “apple is to tree as grap is to ___”
We consider:
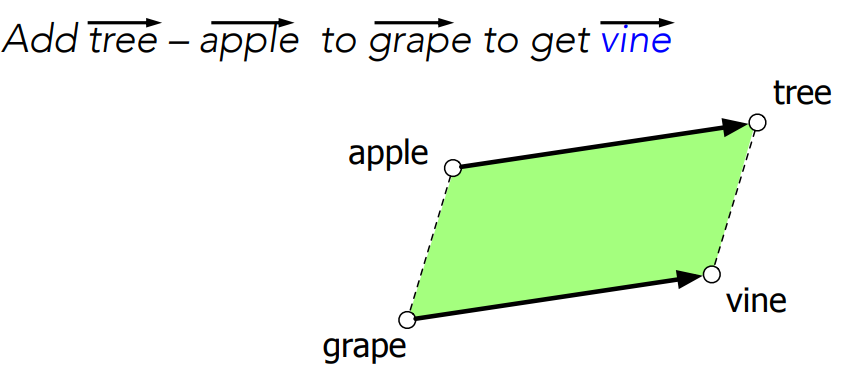
The parallelogram method can solve analogies with both sparse and dense embeddings (Turney and Littman 2005, Mikolov et al. 2013b)
- king – man + woman is close to queen
- Paris – France + Italy is close to Rome
Singular and plural are also related:
Caveats with the Parallelogram Method
It only seems to work for frequent words, small distances and certain relations (relating countries to capitals, or parts of speech), but not others. (Linzen 2016, Gladkova et al. 2016, Ethayarajh et al. 2019a)
Understanding analogy is an open area of research (Peterson et al. 2020).
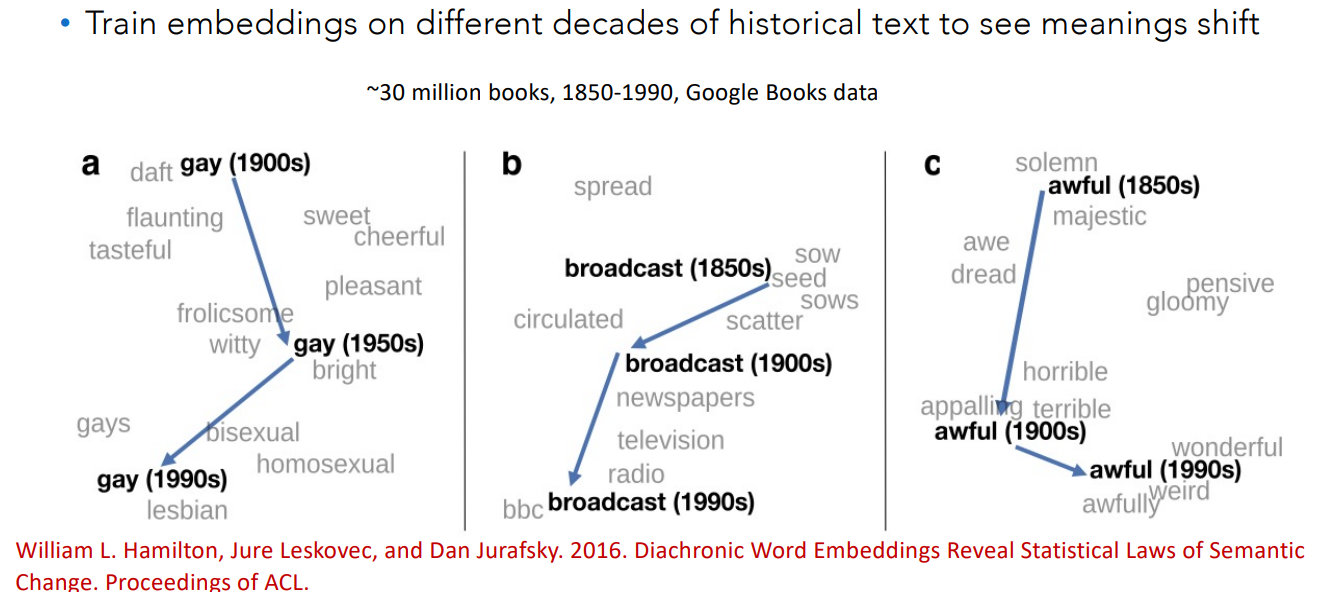
Embeddings Reflect Cultural Bias

Compute a gender or ethnic bias for each adjective: e.g., how much closer the adjective is to “woman” synonyms than “man” synonyms, or names of particular ethnicities.
Embeddings for competence adjective (smart, wise, brilliant, resourceful, thoughtful, logical) are biased toward men.
- bias slowly decreasing 1960-1990
Embeddings for dehumanizing adjectives (barbaric, monstrous, bizarre) were biased toward Asians in the 1930s
- bias decreasing over the 20th century
These match the results of old surveys done in the 1930s
Evaluating Word Embeddings
Two types of evaluation metrics, intrinsic and extrinsic evaluations: depending on the task
Intrinsic Evaluation
Assesses how well the word embeddings capture the semantic (meaing) or syntactic (grammar) relationships between words.

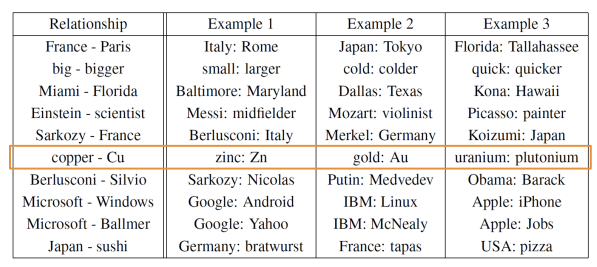
Test relationships between words, from the original Word2vec paper (word embedding created by a continuos skip-gram model):
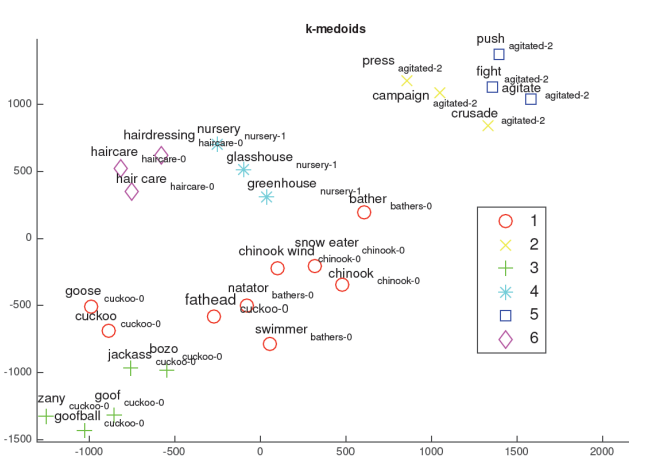
Another way is through clustering between words, and then doing human judgement through visualization of the clusters.
Extrinsic Evaluation
Test word embeddings on external tasks, e.g., named entity recognition (NER), part-of-speech tagging:
- Pro: Evaluates the actual usefulness of embeddings
- Cons: Time-consuming: you need to train and evaluate a full model around the embeddings
- Cons: More difficult to troubleshoot:
- If performing poor, one does not know the specific part of the end-to-end process responsible
- it could be the architecture, the optimization, the dataset and so on.
Named Entity Recognition (NER): detecting names of people, places, or organization Part-of-Speech Tagging (POS): labeling words as nouns, verbs, adjectives, etc.
To summarize:
- Extrinsic evaluation = “How well do these embeddings work in real tasks?”
- Intrinsic evaluation = “How well do these embeddings capture meaning on their own?”