SC - Lezione 9
Checklist
Domande, Keyword e Vocabulary
- Singular Value Decomposition
- Two orthogonal and a diagonal
- Singular Values
- Left and right singular vectors
- What happens if you multiply a vector by a diagonal matrix?
- Directions of sigma1 and sigma2
- Semiaxis sigma1 and sigma2
- Economy form of the SVD
- Properties of the singular values
- non negative numbers
- The rank of A and
- The norm of A and
- trace of
and trace of - SVD of the transpose matrix
- SVD of orthogonal matrix
- Relationship between SVD and spectral decomposition
- Reduced SVD decomposition with rank
- Dimensionality reduction
Appunti SC - Lezione 9
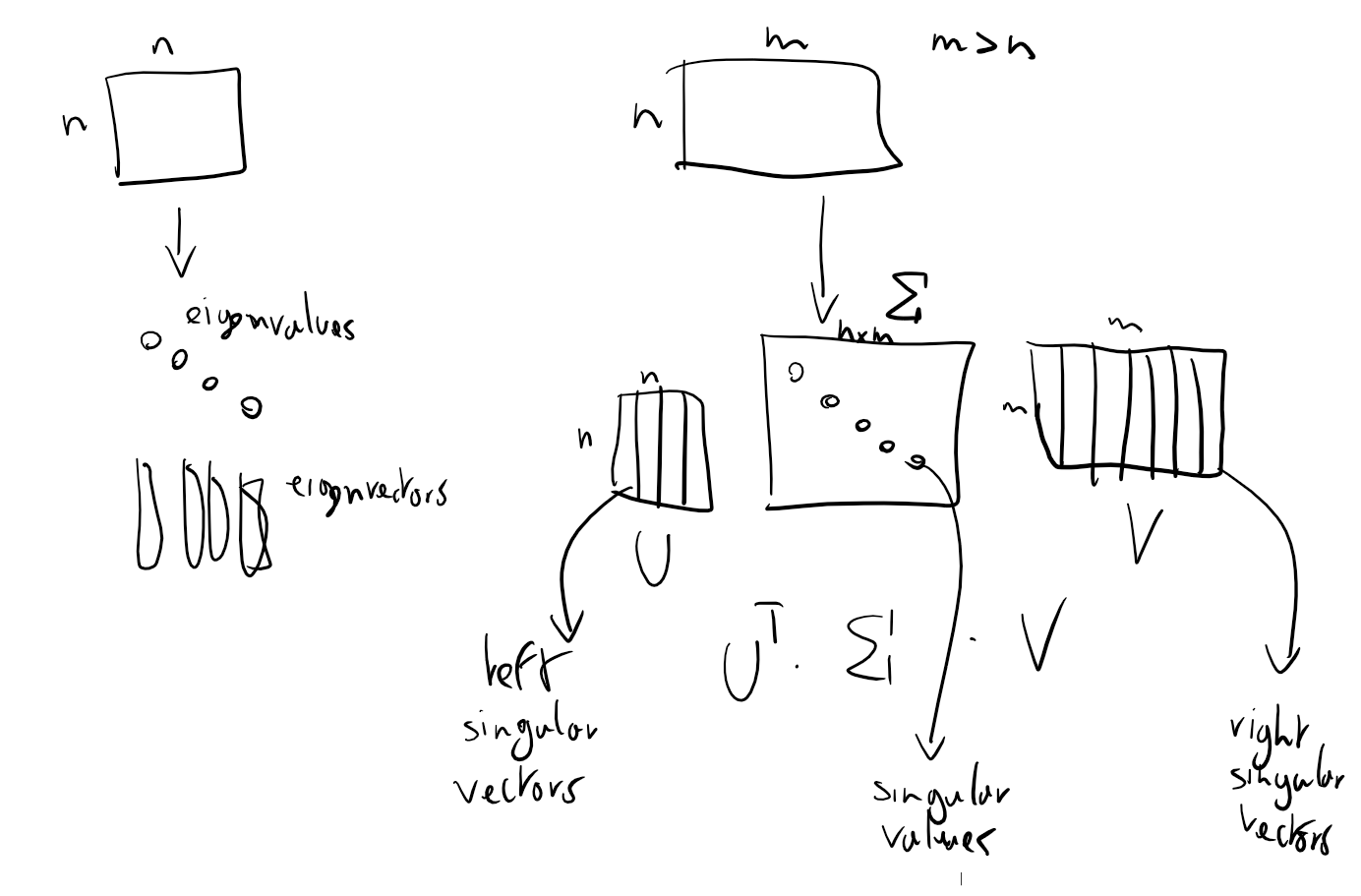
Singular Value Decomposition
The SVD is the most important decomposition in data science.
Methaphor: the SVD is a sort of extention of eigenvalue and eigenvectors to non square matrix. There is a very strong correlation between eigenvectors and eigenvalues anyway, even if is not entirely correct.
Theorem:
Let A be a matrix that is non square, then there exists an orthogonal matrix (square) called
What is a first difference between SVD and QR factorization?
In SVD we have 3 matrices: 2 orthogonal and 1 diagonal matrix. In QR we have two matrices: 1 orthogonal and 1 diagonal
Alternative formula of SVD
We can rewrite the formula as:
This emphasize the fact that A can always be diagonalized by means of an orthogonal transformation of its columns (by means of U) and its rows (by means of V).
What’s the conseguence of this? If you have any matrix you can rotate columns and rows in a suitable way such that you got a diagonal matrix. Like you can transform any matrix in a diagonal matrix.
SVD and complex numbers
Another difference between spectral decomposition and Singular Value Decomposition is that applying SVD, produces a matrix without complex numbers.
Singular Values
The values of the matrix
In matlab they appear in descending order (from the biggest to smallest). Also, they are non negative.
The singular values are denoted with
Check if V is orthogonal
I can check in matlab if a matrix is orthogonal by doing:
norm(V'*V-eye(length(V)))
The i-th column of U and the i-th column of V are called left singular vectors and right singular vectors.
Eigenvalues/vectors vs singular values/vectors
Geometrical Meaning of the SVD
Let’s consider the unit sphere of 2 norms: the infinite set of vectors that have two norm equal to one. Ofcourse this set is a circle, since it’s the set of points that have a distance to the origin that is 1 or less than 1.
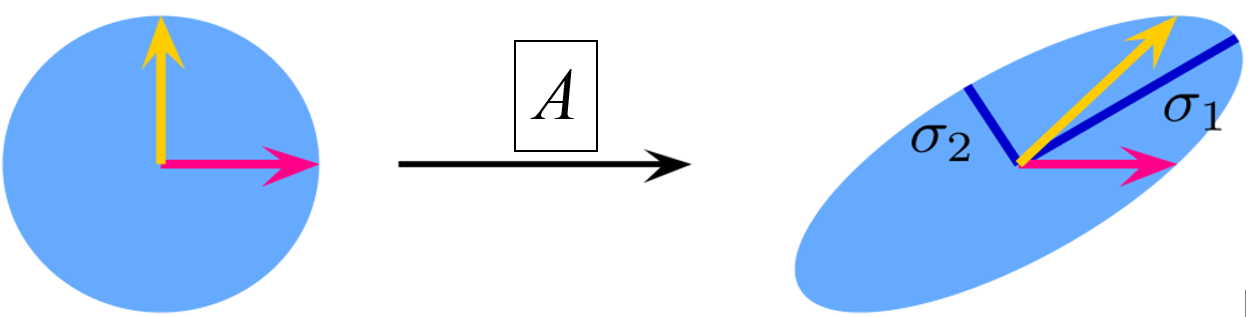
To these infinite vectors we apply a matrix A which produces the effect on the right. And we obtain an elipsoid (important note: it relates to the singular vector of matrix A).
Take any vector in this circle (for example the yellow and red) of length exactly 1. Then i multiply the yellow times A and i get the new vector yellow on the right. Same with the red one. If we take the infinite number of matrix vector multiplication we transform this unit sphere into the right one.
We can apply the SVD of A and we obtain three matrices, each will have an effect on the vectors and by applying all three, the effect will be the same as applying
if we apply 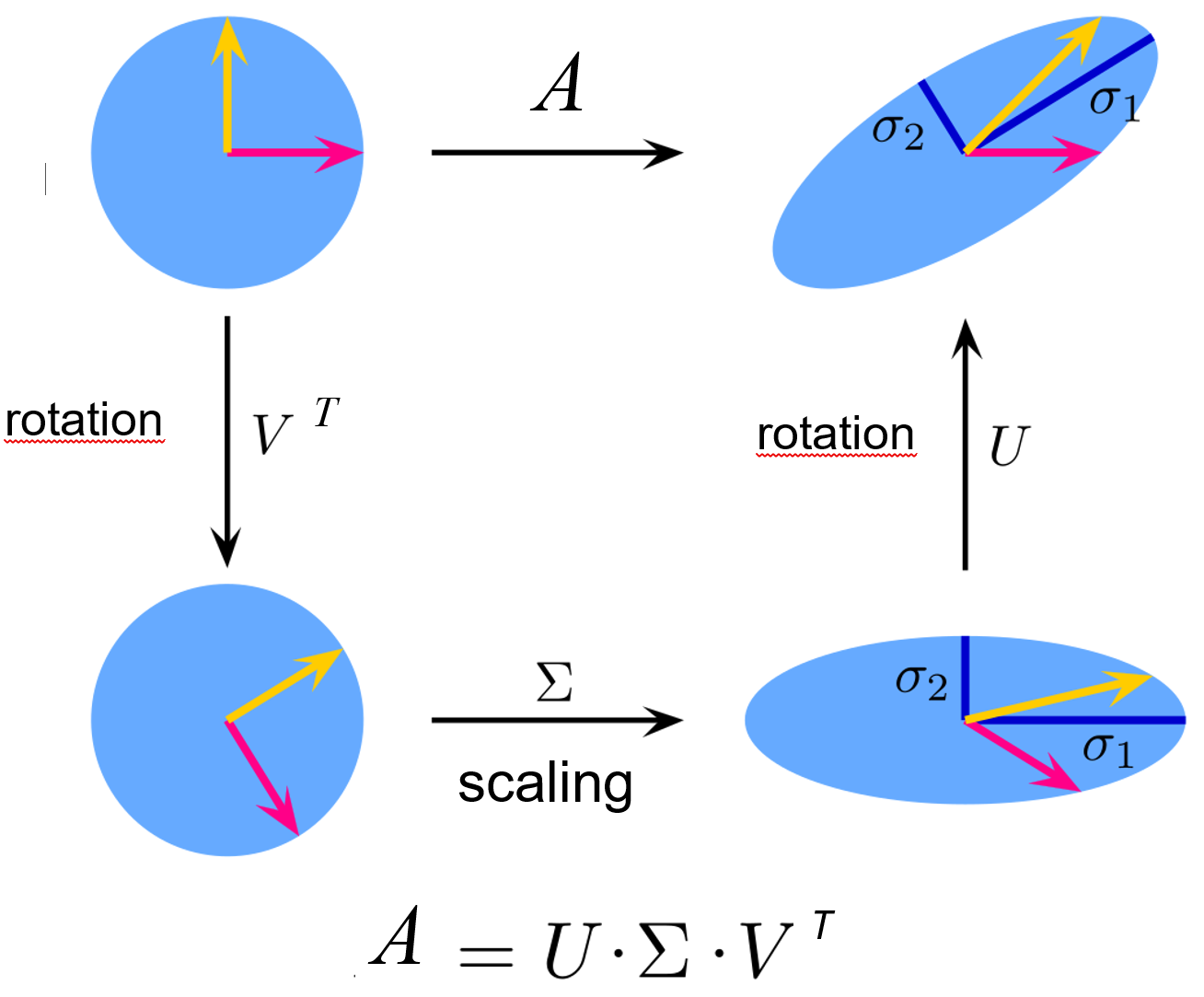 What happens if you multiply a vector by a diagonal matrix? IT GET SCALED
you can easily verify this in matlab for example
What happens if you multiply a vector by a diagonal matrix? IT GET SCALED
you can easily verify this in matlab for example
x=[10 20]'
F=[2 0; 0 4]
x*FWhat does it then tell us the singular value decomposition given the previous facts?
It’s a sequence of three simple transformation: a rotation, a scaling and another rotation.
SVD factorization - economy form
When we introduces the QR factorizaton we have seen that we can have a simpler factorization. The same can be done here, with the “reduced-form” or “economy form” of the SVD.
It follow the strcture of the matrix
What kind of matrix is
A = SVD
Properties of the singular values
- The singular values are non negative numbers (can be zero) but are ordered in descending order.
- The rank of the matrix A is equal to the number of its non-zero singular value. As conseguence of this, the rank of A is equal to the rank of
- The norm A is the same of norm of
- The conditional number is the same as
The Frobenius norm of
Orthogonal Matrices: like for eigenvalues/vectors, the singular values of an orthogonal matrices are all 1.
Rectangular matrix with orthogonal columns
This property also holds for rectangular matrix with orthogonal columns:
, where is a diagonal orthogonal matrix with singular values equals to 1
Left and right singular vectors: The singular values of
Exercise
Define a random matrix
What is the SVD of
Most of the data science is based on the fact that, in general, the singular values of real application matrix decay very fast. (Go to zero)
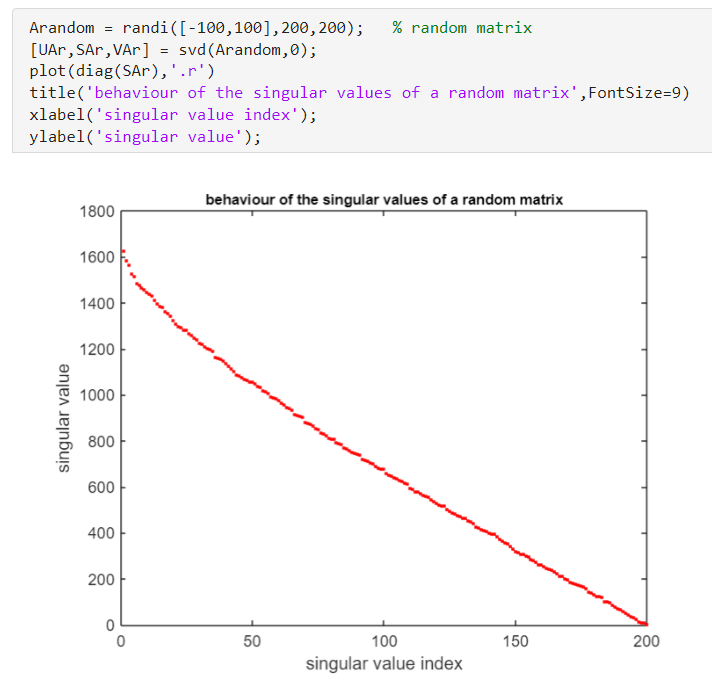
If you take a matrix that comes from real world application usually the decay is even faster.
Relationship between SVD factorization and spectral decomposition
Consider the spectral decomposition for the symmetric matrix:
We want to see the spectral decomposition of
I write the spectral decomposition as:
Using the SVD of A we may write:
Now, if multiply the side from the right by the matrix
We observe that the last equation is indeed the spectral decomposition of the matrix
It’s very important application, it’s in practice the principal component analysis (and we will show that is a type of SVD).
Now let’s do the same considering
In an 8 by 5 matrix, how many singular value you have? A diagonal matrix, just 5 elements.
I obtain a different result:
We notice that:
- only the first n columns of
concide with the first n columns of U - The first n eigenvectors of
coincide with the square of the first n diagonal entries of
Another thing to notice is that only the first
SVD Factorization: reduced version (economy)
It’s similar to the Reduced QR Factorization.
The reduced form is possible because we can decompose the diagonal matrix of the singular values into:
The last 
Orthogonal basis and projectors (SVD for non maximum rank matrices)
Let
This is similar to the rank reduced QR factorization. We are in the same case where the matrix has non maximum rank.
Using matlab, we get the singular values and notice that only the first
This leads us to the following:
is the matrix with orthonormal columns in consisting of the first columns of is the matrix with orthonormal columns in consisting of the first columns of V
As we will see in an application on photos, the singular values with more informations are the ones with higher values.
Orthonormal basis for the column space of A
We define
Note that this approximation
Try to interpret it as matrix vector multiplication: a linear combination of the column
and the factor combination is elements of In term of reference system what does it mean? The columns of the matrix are being transformed.
Orthonormal basis for the orthogonal complement of the column space of A
The last
Recall
- The range of
is the set of all possible linear combinations of its columns - The null space of
is the vectors such that - The range of
coincides with the null space of