Retrieval Augmented Generation
Prerequisites:
Sources:
An important task of LLMs is to fill human information needs by answering people’s questions. A lot of information is online, so answering questions is closely realted to web information retrieval, the task performed by search engines. Indeed, the distinction is becoming ever more fuzzy, as modern search engines are integrated with large language models.
Simply prompting an LLM can be useful to answer many factoid questions, but the fact that knowledge is stored in feedforward weights of the LLM leads to a number of problems with prompting as method for correctly answering factual questions.
The first problem is hallucinations: a response that is not faithful to the facts of the world. LLMs may make up answers that sounds reasonable but are wrong.
Calibrated: it’s not always possible to tell when a LM is hallucinating partly because LLMs aren’t well calibrated. In a calibrated system, the confidence of a system in the correctness of its answer is highly correlated with the probability of an answer being correct. So if a calibrated system is wrong, at least it might hedgeits answer or tell us to go check another source. But since language models are not well-calibrated, they often give a very wrong answer with complete certainty.
No questions about propertary data like personal email. For various applications we may want to ask factual questions about proprietary data like:
- Healther application: apply a language model to medical records
- Company: may have internal documents that contain answers for customer service or internal use
- Legal firms: need to ask questions about legal discovery from proprietary documents.
Hopefully, none of this data was in the large web-based corpora that LLM are pretrained on.
Knowledge is static: if a LLM is pretrained once, at a particular time, it cannot answer questions about rapidly changing information (like something that happened last week) since they won’t have up-to-date information from after their release data.
Retrieval-Augmented generation (RAG): one solution to all these problems with simple prompting for answering factual questions is to give a language model external sources of knowledge, for example proprietary texts like medical or legal records, personal emails, or corporate documents, and to use those documents in answering questions. With RAG:
- we use information retrieval (IR) techniques to retrieve documents that are likely to have information that might help answer the question.
- Then we use a large language model to generate an answer given these documents.
Information Retrieval (IR)
The field encompassing the retrieval of all manner of media based on user information needs.
The IR system is often called search engine.
Consider the IR task of ad hoc retrieval, a user poses a query to a retrieval system, which then returns an ordered set of documents from some collection.
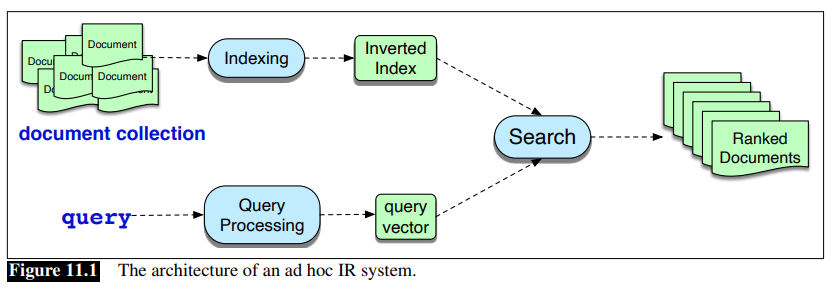
A basic IR architecture uses the [[../../../../University Exams/Bachelor Degree in ML and Big Data/Natural Language Processing/NLP - Lecture - Vector Space Models - Co-occurence matrix, TF-IDF, PMI|[NLP] Vector Space Models]].
IR - Term weighting and document scoring
Let term be the word(s) in the collection (set of documents being used to satisfy user quests).
Instead of computing a term weight, we use either tf-idf weighing See TF-IDF or a slightly more powerful variant called BM25.
Document Scoring: we score document
Some improvements to the formula:
- drop the idf term for the document (second part of the equation) since the identical term is already computed for the query, resuing in better performance.
Let’s see an example. Consider this query with these four nano documents:
 Next figure shows the computations for the query and first two documentations:
Next figure shows the computations for the query and first two documentations:
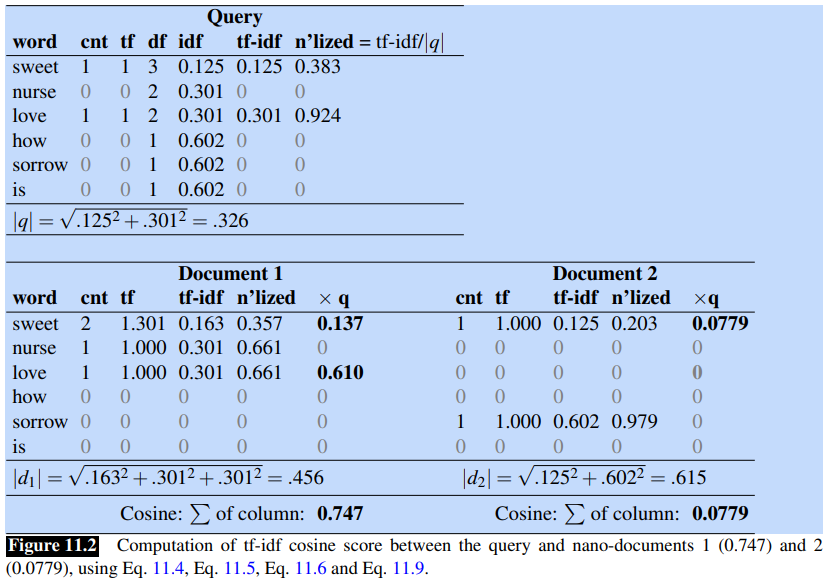 Since Document 1 has an higher cosine than Document 2, the tf-idf cosine model would rank the first document above the second one.
Since Document 1 has an higher cosine than Document 2, the tf-idf cosine model would rank the first document above the second one.
BM25
Adds two parameters:
is the inverted document frequency (IDF) is the weighted term frequency (tf) is the length of the average document
when
Inverted Index: to efficiently find documents that contains words in the query, the data structure is used. It also conveniently stores useful information like document frequency and the count of each term in each document. The inverted index, given a query, gives the list of documents that contasin the term. It consists of two parts: a dictionary and the postings. The dictionary is a list of term, each pointing to a posting list for the term. The dictionary can also store the document frequency for each term
Evaluation of Information-Retrieval Systems
We use precision and recall
Assume that each document returned by the IR system is either relevant or not relevant.
- A system returns
ranked documents - R is a subset of
of relevant documents and are the remaining irrelevant documents are documents in the collection as a whole are relevant to this request
Unfortunately, these metrics don’t adequately measure the performance of a system that ranks the documents it returns.
Note that:
- recall is non-decreasing: when a relevant document is encountered recall increases, and when a non-relevant doc is found, it remains unchanged
- precision jumps up and down: increasing when relevant documents are found and decreasing otherwise
Also, results must be combined for all queries, in a way that lets us compare one system to another.
The most common way to visualize precision and recall is called precision-recall curve:
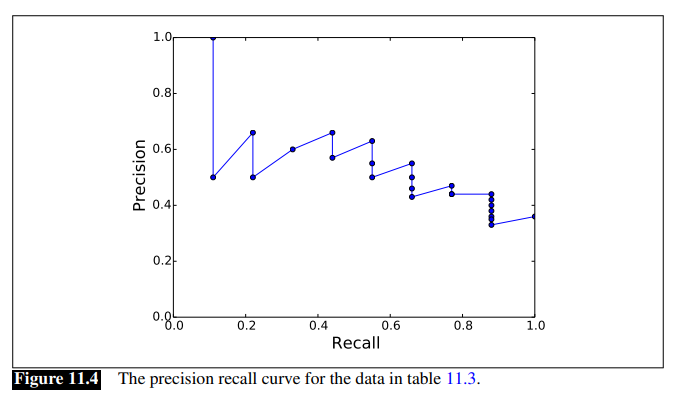
To combine values for all queries, one way is to plot averaged precision values at 11 fixed levelevs of recall (0, to 100, in steps of 10).
Interpolated precision: we are not likely to have datapoints at these exact levels, so interpolated precision values for the 11 recall values from the data points are computed, by choosing the maximum precision value achieved at any level of recall at above the one we’re calculating:
Mean Average Precision (MAP) is another way to evaluate ranked retrieval, whcih provides a single metric that can be used to compare competing systems or approaches. In this approach, we again descend through the ranked list of items, but now we note the precision only at those points where a relevant item has been encountered. For a single query, we average these individual precision measurements over the return set (up to some fixed cutoff.
More formally, if we assume that
is the precision measured at the rank at which document was found.
For an esnemble of queries
Information Retrieval with Dense Vectors
Vocabulary mismatch problem: classic tf-idf or BM25 algorithms for IR works only if there is exact overlap of words between the query and the document. This is on the shoulder of user that have to guess exactly the words.
Solution is to use (dense) embeddings.
IR with BERT
BERT architecture is used for this task. Both the query and the document are presented to a single encoder, and thus building a representation that is sensitive to the meanings of both query and document. Then a linear layer can be put on top of the [CLS] token to predict a similarity score for query/document.
- For understanding what is the [CLS] token, read Next Sentence Prediction task for BERT
Equations:
Token Windows Usually documents are broken into smaller passages, and the retriever encodes and retrieves these passages rather the entire documents. The query and document have to be made to fit the token window of the model, in case of BERT it is 512 tokens. This is done usually by truncating the query to 64 tokens and the document if necessary, such that: the query, [CLS] and [SEP] fit in 512 tokens.
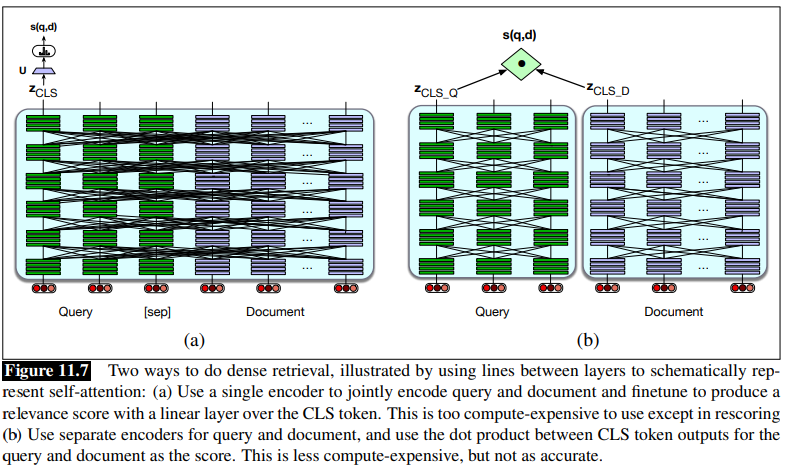 The problem with a full BERT architecture is the expense and computation time.
The problem with a full BERT architecture is the expense and computation time.
IR with Bi-Encoder
Bi-encoder is a much more efficient architecture where we can encode the documents in the collection only one time by using two separate encoder models, one to enocde the query and one to enocde the document. The workflow is the following:
- Documents are encoded and their vector embeddings is produced
- When a query comes in, it is encoded and then the dot product between the query vector and the document vector is used as score for each candidate document.
Using BERT as bi-encoder means using two encoders
The bi-encoder is much cheaper but less accurate, since its relevance decision can’t take full advantage of all the possible meaning interactions between all the tokens in the query and the tokens in the document.
Intermediate Approaches
There are numerous approaches that lie in between the full encoder and the bi-encoder.
One approach is to use methods like BM25 as first pass relevance ranking for each document, take the top N ranked documents and use expensive methods lik full BERT scoring to rerank only the top N documents rather than the whole set.
ColBERT Encodes the query and the document into two separate contextual representations for each tokens.
A question
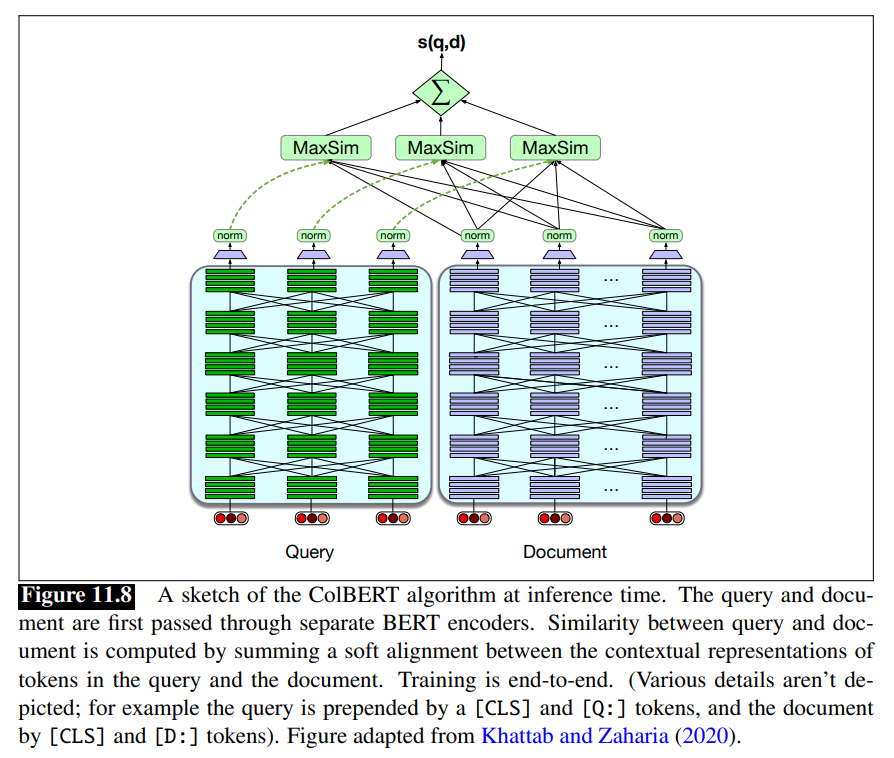
Relevance is computed using a sum of maximum similarity (MaxSim) operators between tokens in
The ColBERT scoring mechanism is:
Training ColBERT: a BERT architecture need to be trained end-to-end to fine-tune the encoders and train the linear layers (and the special [Q] and [D] embeddings) from scratch. It is trained on triples
Training data and efficiency
All the supervised algorithms need training data in the form of queries together with relevant and irrelevant passages or documents (positive and negative examples).
There aresome semi-supervised ways to get labels. Some dataset (like MS MARCO Ranking) contain gold positive examples. Negative examples can be sampled randomly from the top-1000 results from existing IR system.
Relevance-guided supervision: Iterative methods like relevance-guided supervision can be used if datasets don’t have labeled positive examples which rely on the fact that many datasets contain short answer strings. In this method, an existing IR system is used to harvest examples that do contain short answer strings (the top few are taken as positives) or don’t contain short answer strings (the top few are taken as negatives), these are used to train a new retriever, and then the process is iterated.
Faiss While for sparse word-count vectors, the inverted index is very efficient to rank documents by similarity to query, for dense vectors it isn’t as simple. Finding the set of document vectors that have the highest dot product with a dense query vector is an instance of the nearest neighbor search. Modern system make use of approximate nearest neighbor vector search algorithms like Faiss.
Retrieval-Augmented Generation (RAG)
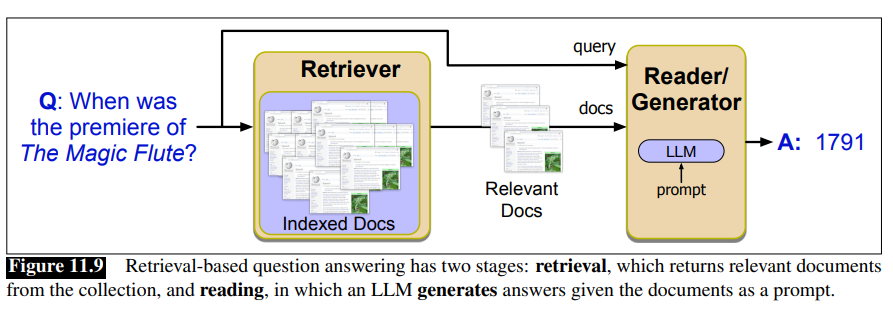
First the relevant passages from the text collection are retrieved, then the answer is generated via retrieval-augmented generation.
Recall that in simple conditional generation, we can cast the task of question answering as word prediction by giving a language model a question and a token like A: suggesting that an answer should come next:
Q: Who wrote the book ‘‘The Origin of Species"? A:
Then we generate autoregressively conditioned on this text.
Mormally, a simple autoregressive language modeling computes the probability of a string from previous tokesn:
Adding a prompt like Q: followed by a query A: all concatenated:
This approach still suffer from hallucination, since it is unable to show users textual evidence to support the answer, and is unable to answer questions from proprietary data.
Suppose we have a query 
More formally:
Often a two-stage retrieval algorithm is used in which the retrieval is reranked.
Multi-hop: some questions may require multi-hop architectures, in which a query is used to retrieve documents, which are then appended to the original query for a second stage of retrieval.
Details of prompt engineering also have to be worked out, like deciding whether to demarcate passages, for example with [SEP] tokens, and so on.
Much research in this area also focuses on ways to more tightly integrate the retrieval and reader stages.
Question Answering Datasets
There are scores of question answering datasets, used both for instruction tuning and for evaluation of the question answering abilities of language models.
We can distignuish the datasets along many dimensions (Rogers et al. (2023). One si the original purpose of the questions in the data: natural information-seeking questions or designed for probing i.e evaluating or testing systems or humans.
On the natural side there are datasets like:
- Natural questions a set of anonymized English queries to the Google Search Engine and their answers
- MS MARCO (Microsoft Machine Reading Comprehension) collection of datasets, including 1 million real anonymized English questions from Microsoft Bing query logs together with a human generated answer and 9 million passages
- TyDi QA dataset contains 204K question-answers pairs from 11 typologically diverse languages
On the probing side are datasets like:
- MMLU (Massive Multitask Language understanding): a commonly-used dataset of 15908 knowledge and reasoning questions in 57 areas including medicine, mathematics, computer science
- Reading comprehension task dataset
The task of question answering given one or more documents is also called open book QA task, while the task of answering directly from the LM with no retrieval component at all is the closed book QA task.
Evaluating Question Answering
Three techniques are commonly emploted to evaluate question-answering, with the choice depending on the type of question and QA situation.
Multiple choice questions like MMLU allow to report exact match i.e the % of predicted answers that match the gold answer exactly.
For questions with free text answers like Natural Questions dataset, we commonly evaluate with F1-score to roughly measure the partial string overlap between the answer and the reference answer. Treat the prediction and gold answers as a bag of tokens, and compute
Finally, in some situations QA systems give multiple ranked answers, in such cases mean reciprocal rank (MRR) is used. Each test set question is scored with the reciprocal of the rank of the first correct answer:
is the test set or a subset of it with non-zero scores
For example, if the system returns five answers to a question, but the first three are wrong (so the highest-ranked correct answer is ranked fourth), the reciprocal rank for that question is
Other topics
Generation-augmented Retrieval (GAR) and Query Expansion
Sources:
While RAG fetches (using a retrieval model) relevant documents from the corpus as context for the language model and then generates an answer for the input query directly using the language model. The generation-augmented retrieval (GAR) paradigm augments the input query using language models, and then uses a retrieval model to fetch the relevant documents from the corpus.
zero-shot information retrieval is a special case of information retrieval in which prompting doesn’t include labeled examples. Some zero-short datasets benchmarks are BEIR (Thakur et al. 2021) and Mr.TyDi (Zhang et al., 2021).
Query expansion is a technique used in information retrieval to improve search results by adding related terms to the original search query. Query expansion can be done using generative methods so for example using LLMs to improve queries, and then feed the query to the retrieval model.
Search queries are often short, ambiguous, or lack necessary background information, LLMs can provide relevant information to guide retrieval systems, as they memorize an enormous amount of knowledge and language patterns by pre-training on trillions of tokens.
Table 5 is taken from Wang et al.,2021 in an approach called “query2doc” where a query is augmented by converting it to a pseudo-document by an LLM and then concatenated to the original query to form a new query.
 Wang et al., 2021 also propose training DPR models initialized from a BERT with BM25 hard negatives only and using a standard contrastive loss:
Wang et al., 2021 also propose training DPR models initialized from a BERT with BM25 hard negatives only and using a standard contrastive loss:
is the set of hard negatives and represent the embeddings fro the query and document respectively.
And a second setting build upon dense retrivers and use KL divergence to distill from across-encoder teacher model:
and are the probabilities from the cross-ender and the student model, respectively. is a coefficient to balance the distillation loss and contrastive loss.
Arora et al (2023) propose an approach that combines both called GAR-meets-RAG paradigm, applied to zero-shot information retrieval. They make two observations:
- RAG model can be used to provide the context crucial for the GAR model
- the GAR model itself can be used as retriever model for the RAG model.
This then formulate the retrieval problem as a recurrence of RAG and GAR. They use a relevance model
Pseudo relevance feedback (source: Wikipedia] is a method for automatic local analysis that can be used in GAR. The procedure is:
- Take the results returned by initial query as relevant results (only top k with k being between 10 and 50 in most experiments).
- Select top
terms from these documents using for instance tf-idf weights. - Query expansion: add these terms to query, and then match the returned documents for this query and finally return the most relevant documents.